How GOAT Taught a Machine to Love Sneakers
Embeddings are a fantastic tool to create reusable value with inherent properties similar to how humans interpret objects. GOAT uses deep learning to generate these for their entire sneaker catalogue.
By Emmanuel Fuentes, GOAT.

Mission
At GOAT, we’ve created the largest marketplace for buyers and sellers to safely exchange sneakers. Helping people express their individual style and navigate the sneaker universe is a major motivator for GOAT’s data team. The data team builds tools and services, leveraging data science and machine learning, to reduce friction in this community whenever and wherever possible.
When I joined GOAT, I was not a sneakerhead. Every day while learning about new sneakers, I gravitated towards the visual characteristics that made each one unique. I started to wonder about the naturally different ways people new to this culture would enter the space. I came away feeling that, regardless of your sneaker IQ, we can all communicate about their visual appeal. Inspired by my experience, I decided to build a tool with the hope that others would find it helpful.

The first place to start is developing a common language to describe all sneakers. However, this is not a simple task. With over 30,000 sneakers (and growing) in our product catalogue of unique styles, silhouettes, materials, colors, etc. attributing the entire catalogue manually becomes intractable. In addition, every shoe release creates the possibility of changing how we talk about sneakers, meaning we have to update the common language. Instead of trying to fight this reality, we need to embrace the variation and innovation by including them in our language from the beginning.
One way to address this is to use machine learning. To keep up with the changing sneaker landscape, we use models that find relationships among objects without explicitly stating what to look for. In practice, these models tend to learn features similar to humans. I detail in this post how we use this technology to build visual attributes as the base of our common sneaker language.
Latent Variable Models
At GOAT, we use artificial neural networks to approximate the most-telling visual features from our product catalogue i.e. latent factors of variation. In machine learning, this falls under the umbrella of manifold learning. The assumption behind manifold learning is that often the data distribution, e.g. images of sneakers, can be expressed in a lower dimensional representation locally resembling a euclidean space all the while preserving a majority of the useful information. The result is transforming millions of image pixels into interpretable nuanced characteristics encapsulated as a list of a few numbers.
Manifold WHAT?
Think about how you would tell your friend the directions to your home. You would never describe how to get from their house to yours in a series of raw GPS coordinates. GPS, in this metaphor, represents a high dimensional, wide-domain random variable. Instead, you would more than likely use an approximation of those coordinates in the form of a series of street names and turn directions, i.e. our manifold, to encode their drive.
Modeling
We leverage unsupervised models such as Variational Autoencoders (VAE) [1], Generative Adversarial Networks (GAN) [7], and various hybrids [4] to learn this manifold without expensive ground truth labels. These models provide us a way to transform our primary sneaker photos into aesthetical latent factors, also referred to as embeddings.
In many cases these models leverage the autoencoder framework in some shape or form for their inference over the latent space. The model’s encoder decomposes an image into its latent vector then rebuilds the image through the model’s decoder. Following this process, we then measure the model’s ability to reconstruct the input and calculate the incorrectness, i.e. loss. The model iteratively compresses and decompresses many more images using the loss value as a signal of where to improve. The reconstruction task pushes this “bowtie looking” model to learn embeddings which are the most helpful to the task. Similar to other dimensionality reduction techniques such as PCA, this technique often results in encoding the variability in the dataset.
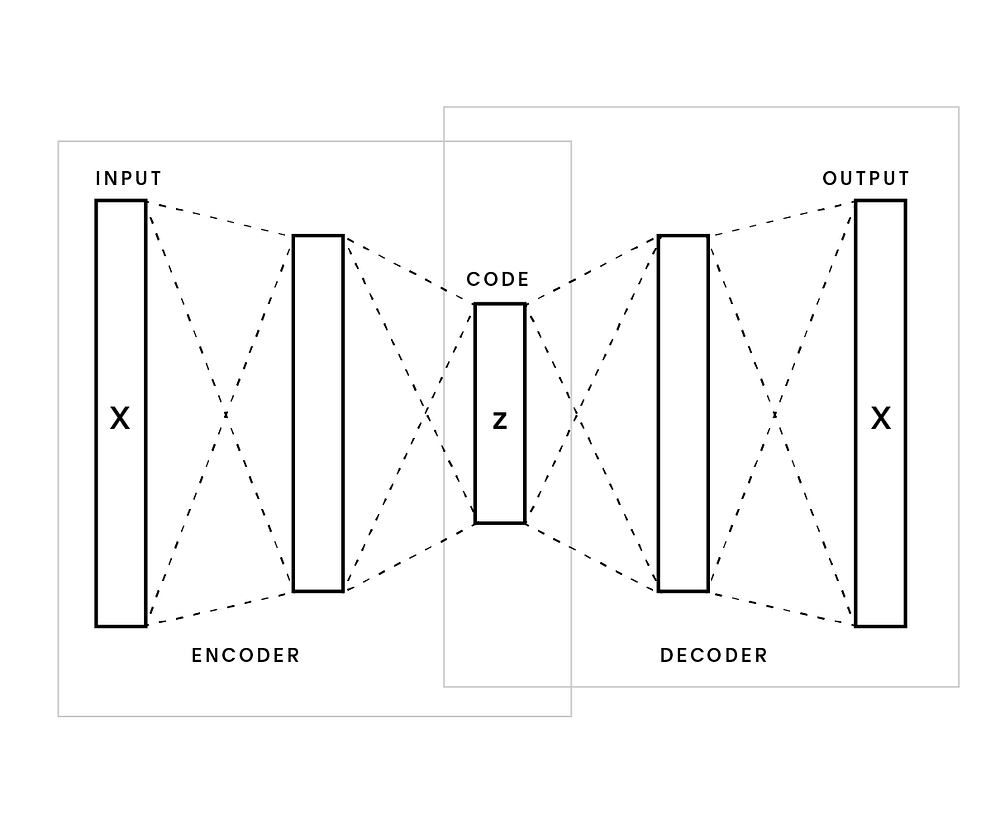
Gotchas and Design Choices
Simply being able to reconstruct an image is often not enough. Traditional autoencoders end up being fancy look up tables of a dataset [1] with minimal generalization capabilities. This is a result of a poorly learned manifold with “chasms”/”cliffs” in the space between samples. Modern models are solving this problem in a variety of ways. Some, such as the famous VAE [1], add a divergence regularization term to the loss function in order to constrain the latent space to some theoretical backing. More specifically, most of these kinds of models penalize latent spaces that do not match some Gaussian or uniform prior and attempt to approximate the differences through a choice of divergence metrics. In a lot of cases, choosing the appropriate model comes down to the design choices of divergence measurement, reconstruction error function, and imposed priors. Such examples for design choices are the β-VAE[2, 3] and Wasserstein Autoencoder [4] which leverage the Kullback-Leibler divergence and adversarial loss respectively. Depending on your use case for learned embeddings you may favor one over the other as there is commonly a tradeoff between output quality and diversity.
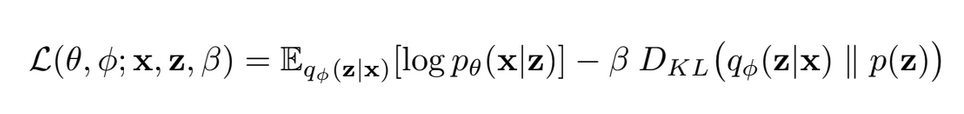
“Looks Like” Case Study

To showcase the learned manifold and inspect the “smoothness” of the learned surface, we can visualize it further through interpolations [6]. We choose two seemingly different sneakers as anchors, then judge the transitions between them in latent space. Each latent vector along the interpolation is decoded back into image space for visual inspection and matched with its closest real product in our entire catalogue. The animation illustrates both these concepts to map the learned representation.



Takeaways
Embeddings are a fantastic tool to create reusable value with inherent properties similar to how humans interpret objects. They can remove the need for constant catalogue upkeep and attribution over changing variables, and lend themselves to a wide variety of applications. By leveraging embeddings, one can find clusters to execute bulk-annotations, calculate nearest neighbors for recommendations and search, perform missing data imputation, and reuse networks for warm starting other machine learning problems.
References
- Auto-Encoding Variational Bayes
- β -VAE: Learning Basic Visual Concepts with a Constrained Variational Framework
- Understanding disentangling in β-VAE
- Wasserstein Auto-Encoders
- Visualizing Data using t-SNE
- Sampling Generative Networks
- Generative Adversarial Networks
Original. Reposted with permission.
Related: