Optimization 101 for Data Scientists
We show how to use optimization strategies to make the best possible decision.
By Rajiv Shah, data scientist at DataRobot
As a data scientist, you spend a lot of your time helping to make better decisions. You build predictive models to provide improved insights. You might be predicting whether an image is a cat or dog, store sales for the next month, or the likelihood if a part will fail. In this post, I won't help you with making better predictions, but instead how to make the best decision.
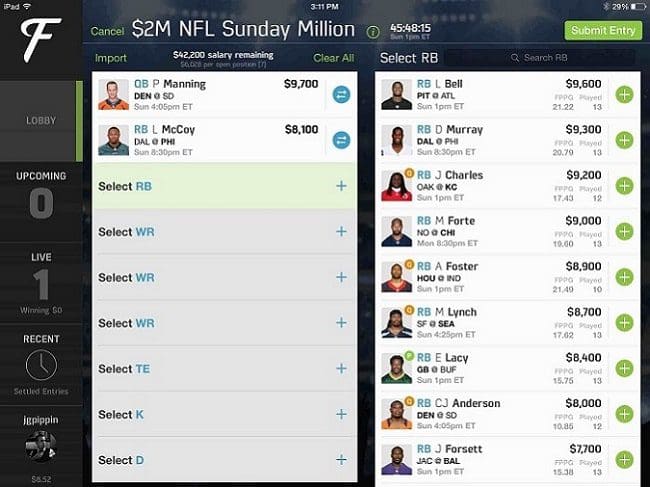
The post strives to give you some background on optimization. It starts with a simply toy example show you the math behind an optimization calculation. After that, this post tackles a more sophisticated optimization problem, trying to pick the best team for fantasy football. The FanDuel image below is a very common sort of game that is widely played (ask your in-laws). The optimization strategies in this post were shown to consistently win! Along the way, I will show a few code snippets and provide links to working code in R, Python, and Julia. And if you do win money, feel free to share it :)
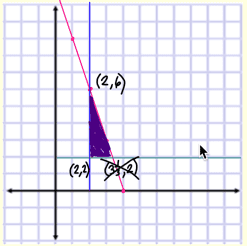
Your initial inclination could be that since the large bookcase is the most profitable, why not focus on them. In that case, you would profit (2*$20) + (3*$50) which is $190. That is a pretty good baseline, but not the best possible answer. It is time to get the algebra out and create equations that define the problem. First, we start with the constraints:
x>=2 ## large bookcases y>=2 ## small bookcases 6x + 2y <= 24 (labor constraint)
Our objective function which we are trying to maximize is:
P = 50x + 20y
If we do the algebra by hand, we can convert out constraints to y <= 12 - 3x. Then we graph all the constraints and find the feasible area for the portion of making small and large bookcases:
This is a very simple toy problem, typically there are many more constraints and the objective functions can get complicated. There are lots of classic problems in optimization such as routing algorithms to find the best path, scheduling algorithms to optimize staffing, or trying to find the best way to allocate a group of people to set of tasks. As a data scientist, you need to dissect what you are trying to maximize and identify the constraints in the form of equations. Once you can do this, we can hand this over to a computer to solve. So lets next walk through a bit more complicated example.
Fantasy Football
Over the last few years, fantasy sports have increasingly grown in popularity. One game is to pick a set of football players to make the best possible team. Each football player has a price and there is a salary cap limit. The challenge is to optimize your team to produce the highest total points while staying within a salary cap limit. This type of optimization problem is known as the knapsack problem or an assignment problem.
Simple Linear Optimization
Let's start by loading a dataset and taking a look at the raw data. You need to know both the salary as well as the expected points. Most football fans spend a lot of time trying to predict how many points a player will score. If you want to build a model for predicting the expected performance of a player, take a look at Ben's blog post.


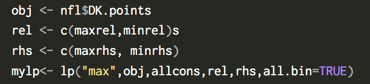
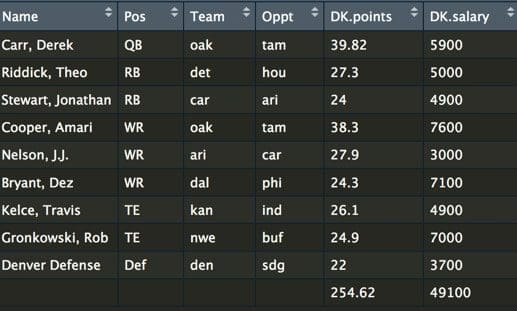
So far, we have built a very simple optimization to solve the problem. There are several other strategies to further improve the optimizer. First, the variance of our teams can be increased by using a strategy called stacking, where you make sure your QB and WR are on the same team. A simple optimization is a constraint for selecting a QB and WR from the same team. Another strategy is using an overlap constraint for selecting multiple lineups. An overlap constraint ensures a diversity of players and not the same set of players for each optimized team. This strategy is particularly effective when submitting multiple lineups. You can read more about these strategies here and run the code in Julia here. A code snippet of the stacking constraint (this is for a hockey optimization):

Last year, at Sloan sports conference, Haugh and Sighal , presented a paper with additional optimization constraints. They include what an opponent’s team is likely to look like. After all, there are some players that are much more popular. Using this knowledge, you can predict the likely teams that will oppose your team. The approach here used Dirichlet regressions for modeling players. The result was a much-improved optimizer that was capable of consistently winning!
I hope this post has shown you how optimization strategies can help you find the best possible solution.
Bio: Rajiv Shah is a data scientist at DataRobot, where he works with customers to make and implement predictions. Previously, Rajiv has been part of data science teams at Caterpillar and State Farm. He enjoys data science and spends time mentoring data scientists, speaking at events, and having fun with blog posts. He has a Ph.D. from the University of Illinois at Urbana Champaign.
Related: