Neural Network Optimization with AIMET
Using AIMET, developers can incorporate advanced model compression and quantization algorithms into their PyTorch and TensorFlow model-building pipelines for automated post-training optimization, as well as for model fine-tuning.
To run neural networks efficiently at the edge on mobile, IoT, and other embedded devices, developers strive to optimize machine learning (ML) models' size and complexity while taking advantage of hardware acceleration for inference. For these devices, long battery life and thermal control are essential, and performance is measured on a per-watt basis. Optimized ML models can help achieve these goals by reducing computations, memory traffic, latency, and storage requirements while making more efficient use of hardware.
State-of-the-Art Model Optimization
While developers put effort into a model’s design, they can employ the following optimization techniques to reduce a model’s size and complexity:
- Quantization: reduces the number of bits used to represent a model’s weights and activations (e.g., reducing weights from 32-bit floating-point values to 8-bit integers).
- Compression: removes redundant parameters or computations with little or no influence on predictions.
The key to success with optimization techniques is implementing them without significantly affecting the model’s predictive performance. In practice, this can be done by hand through trial and error. This involves iterating on model optimizations, testing the model’s predictive and runtime performance, and repeating the process to compare results against past tests.
Given its importance on mobile, ML model optimization is an area where Qualcomm Innovation Center, Inc. does extensive research. But for these optimization techniques, we released our AI Model Efficiency Toolkit (AIMET). AIMET provides a collection of advanced model compression and quantization techniques for trained neural network models.
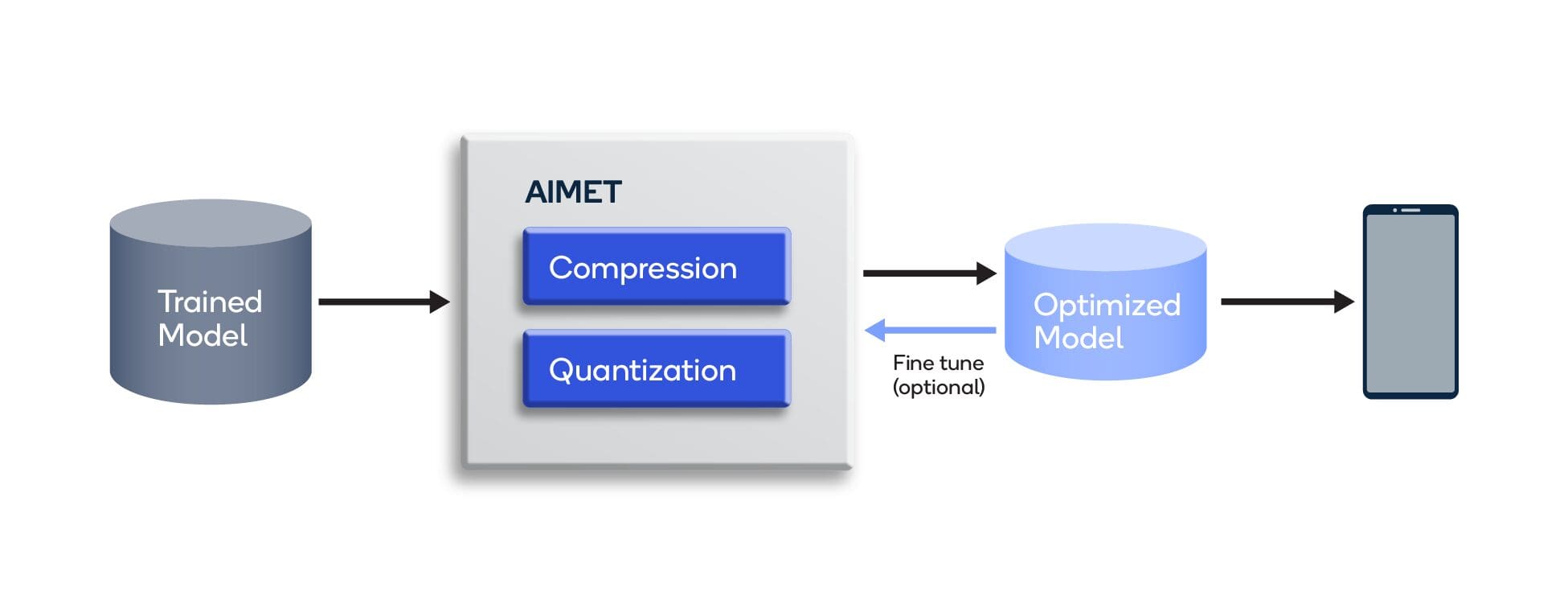
Using AIMET, developers can incorporate advanced model compression and quantization algorithms into their PyTorch and TensorFlow model-building pipelines for automated post-training optimization, as well as for model fine-tuning. Automating algorithms helps eliminate the need for hand-optimizing neural networks that can be time consuming, error prone, and difficult to repeat.
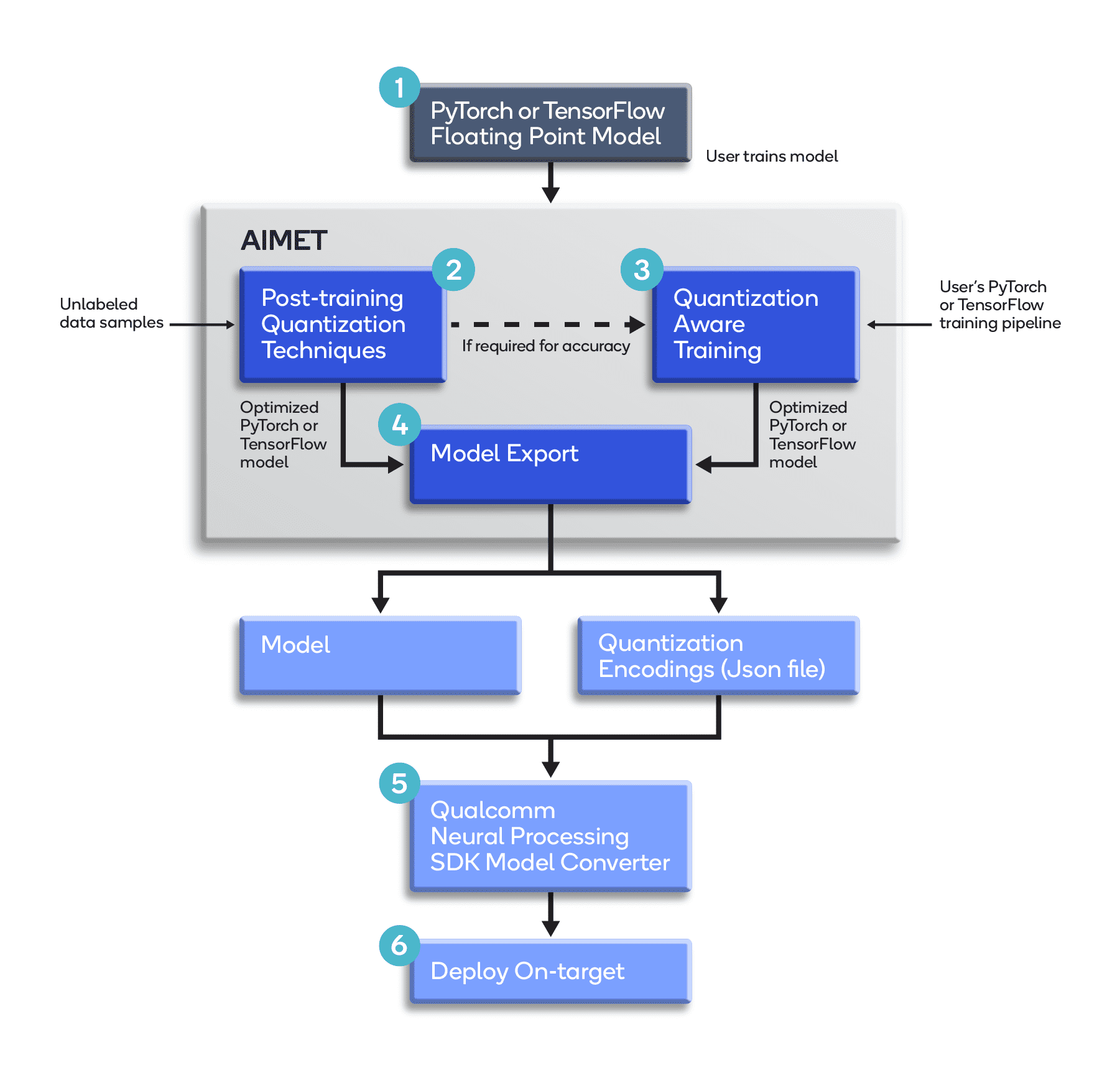
Quantization Workflow
Prior to exporting a model to the target Snapdragon hardware, AIMET can be used to optimize the model for quantized accuracy.
Conclusion
AIMET allows developers to utilize cutting-edge neural network optimizations to improve the run-time performance of a model without sacrificing accuracy. Its collection of state-of-the-art optimization algorithms removes a developer’s need to optimize manually and, thanks to open-sourcing the algorithms, can be continually improved.
To read more, be sure to visit the blog post, Neural Network Optimization with AIMET, hosted on Qualcomm Developer Network.
Snapdragon is a product of Qualcomm Technologies, Inc. and/or its subsidiaries. AIMET is a product of Qualcomm Innovation Center, Inc.