UX Design Guide for Data Scientists and AI Products
Realizing that there is a legitimate knowledge gap between UX Designers and Data Scientists, I have decided to attempt addressing the needs from the Data Scientist’s perspective.
By Syed Sadat Nazrul, Analytic Scientist

When looking up UX design strategies for AI products, I found little to no relevant material. Among the few I found, most were either too domain specific or completely focused on visual designs of web UIs. The best articles I have came across on this subject matter were Vladimir Shapiro’s “UX for AI: Trust as a Design Challenge” and Dávid Pásztor’s “AI UX: 7 Principles of Designing Good AI Products”. Realizing that there is a legitimate knowledge gap between UX Designers and Data Scientists, I have decided to attempt addressing the needs from the Data Scientist’s perspective. Hence, my assumption is that the readers have some basic understanding of data science. For UX Designers with little to no data science background, I have avoided the use of complex mathematics and programming (though I do encourage reading Michael Galarnyk’s “How to Build a Data Science Portfolio” and my “Data Science Interview Guide”).
AI is taking over almost every aspect of our daily lives. This will change how we behave and what we expect from these products. As designers, we aim to create useful, easy-to-understand products in order to bring clarity to this shady new world. Most importantly, we want to use the power of AI to make people’s lives easier and more joyful.
Identifying Key Objectives
Even before we try to design our product, we need to understand the overall business model our product is trying to address. Some common questions to ask are:
- What business problem is the model trying to solving? Is it a classification or regression problem?
- Who are the end users? Are they technical or non-technical? What value are they expecting to derive from this product?
- Is the data static or dynamic? Is the model state-based or stateless? What is the granularity and quality of the data being collected? How do we best represent that information? Are there regulatory restrictions to data usage like PCI, HIPAA or GDPR?
- What are the larger implications of this model? How big is the market? Who are the other players in this market? Are they complimenting your product or direct competitors? What is the switching cost? What are the key regulatory, cultural, socioeconomic and technological trends to take into account?
Having a better understanding of the end product will allow us to address needs more effectively. Some books that I recommend on this topic are Bernard Marr’s “The Intelligent Company: Five Steps to Success with Evidence-Based Management” and Alexander Osterwalder’s Business Model Generation: A Handbook for Visionaries, Game Changers, and Challengers.
Building Interpretable Models
While most people aim for an accurate model, it is common to forget to understand “why” the model does what it does. What are the strengths and weaknesses of the model? Why is it providing the prediction for the given input features? While the question seems trivial, many industries are required to provide this answer as part of their product’s value proposition.
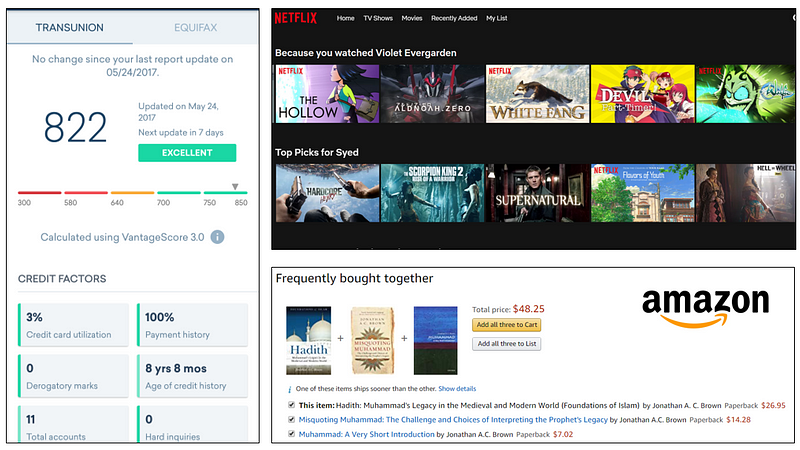
Model interpretation on Credit Karma, Netflix and Amazon
Here are a few of the real life use cases where model interpretation is demanded by the end user:
- Why is your credit score not higher than what it is now?
- Why is Amazon recommending me certain products for purchase?
- Why did the self-driving car crash even after identifying the pedestrian?
Most machine learning models like decision trees and logistic regression are explainable by nature. We can analyze the weight coefficients, visualize trees or calculate the entropy to anticipate major contributions to the final prediction (details here). While in the past, most business problems relied on simple explainable models, “black box” models like Neural Network have started becoming very popular. This is because Neural Networks provide much higher accuracy at lower costs for problems having complex decision boundaries (e.g. image and voice recognition). However, Neural Networks are a lot hard to explain compared to most traditional models. This is especially true for teams with non-technical players as analyzing a neural network is a non-trivial task.
Some Neural Network models are easier to interpret than others, such as the following image recognition model.

Visualizing Convolutional Neural Networks of an Image Classification Model (Source: Simonyan et al. 2013)
Other times, we can infer the engineered features based on the prediction and input. For example, the model may not have a feature for ice being present on the road. However, if the presence of water on the road and the road’s surface temperature are being picked up by the model as inputs, we can intuitively say that the existence of ice can be derived by the hidden layers through feature engineering. Tesla’s autopilot resulting in a fatal accident is just one example of why we need explainable AI in the field of self-driving vehicles.
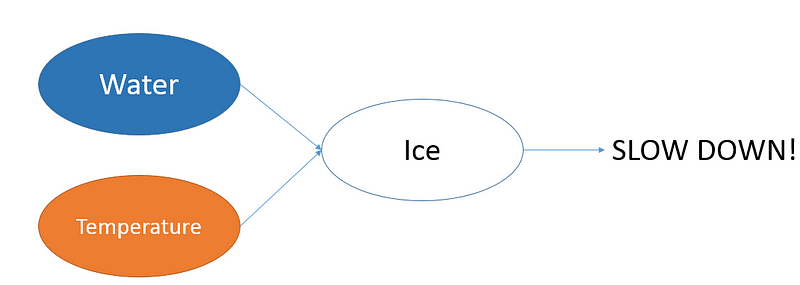
Example of how Neural Networks create higher order features in their hidden layers on a self driving vehicles
For more information on interpretable models, check out Lars Hulstaer’s “Interpreting machine learning models”.
Model interpretation doesn’t always need to be mathematical. Qualitatively looking at the inputs and their corresponding outputs can often provide valuable insight. Below is a smart security camera misidentifying a burglar as someone taking a selfie, simply because he is holding the bar like a selfie stick.
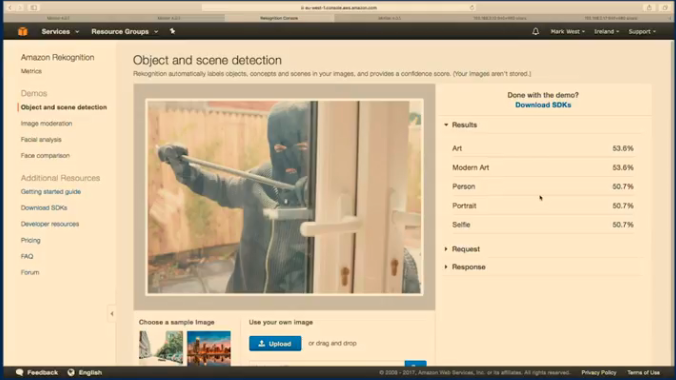
Source: Mark West — Building a Smart Security Camera with Raspberry Pi Zero, Node.js and The Cloud
Handling Edge Cases
AI can generate content and take actions no one had thought of before. For such unpredictable cases, we have to spend more time testing the products and finding weird, funny, or even disturbingly unpleasant edge cases. One example is the misinterpretation of chatbots ٍbelow.
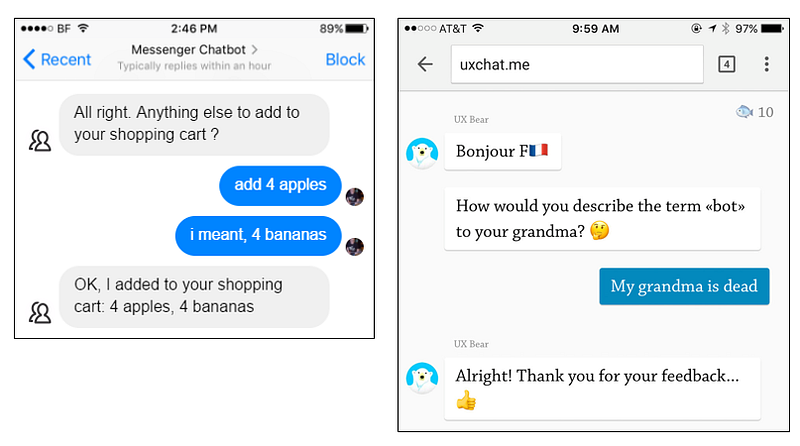
Chatbot fails to unexpected user commands
Extensive testing in the field can help minimize these errors. Collecting clear logs on the production model can help debug unexpected issues when they arise. For more information on testing and DevOps related topics, read my “DevOps for Data Scientists: Taming the Unicorn”.
From the end user’s perspective, clear communication about the product’s capabilities can help them understand these unexpected situations. For example, in many cases, the model has to make a trade-off between precision and recall.
- Optimizing for recall means the machine-learning product will use all the right answers it finds, even if it displays a few wrong answers. Let’s say we build an AI that can identify cat pictures. If we optimize for recall, the algorithm will list all the cats, but dogs will appear in the results too.
- Optimizing for precision means the machine learning algorithm will use only the clearly correct answers, but it will miss some borderline positive cases (cats that kinda look like dogs?). It will show only cats, but it will miss some cats. It won’t find all the correct answers, only the clear cases.
When we work on AI UX, we help developers decide what to optimize for. Providing meaningful insights about human reactions and human priorities can prove the most important job of a designer in an AI project.
Managing Expectations
While it is tempting to believe that a given model can solve any scenario in the world, it is important to understand limitations and being upfront with the end user regarding those limitations. In her talk “What we don’t understand about trust”, the British philosopher Onora O’Neil points to the three components of trust: competence, honesty and reliability. Being upfront shows the client that we are competent, honest and reliable enough to maintain the long term relationship needed for successful businesses. Otherwise, it is far more difficult to meet overly inflated expectations and lose trust when the product fails to deliver.
Financial products are good examples. As per government regulations, your credit score may only be taking assets of value larger than $2000 into account. Hence, any asset lower than $2000 will not be taken into account by the model when calculating your score. Similar case with cyber-security products. You cannot expect the model to monitor DDoS attacks if it is collecting data at a daily or weekly rate.
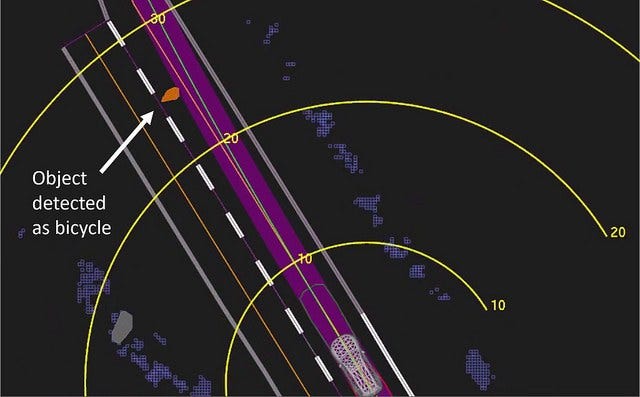
At 1.3 seconds before impact, Uber’s car decided emergency braking was necessary — but didn’t have the ability to do that on its own. The yellow bands show distance in meters, and the purple indicates the car’s path. (Source: National Transport Safety Board)
This case was especially true with the recent Uber self-driving car accident:
About a second before impact, the report says “the self-driving system determined that an emergency braking maneuver was needed to mitigate a collision.” Uber, however, does not allow its system to make emergency braking maneuvers on its own. Rather than risk “erratic vehicle behavior” — like slamming on the brakes or swerving to avoid a plastic bag — Uber relies on its human operator to watch the road and take control when trouble arises.
A natural reaction would be that the camera did not pick up on the bicycle. However, the camera did recognize the pedestrian but the system chose not to stop. This is because the model was not designed to completely replace the driver.
Providing Opportunities for Feedback
The goal of a good UX design is to deliver a product that the end user is satisfied with In order to ensure that your users are getting what they wants, provide them the opportunity to give feedback about the AI content. This can include the rating system on movies or letting banks know that their credit card transaction is not fraudulent. Below is an example from Google Now.
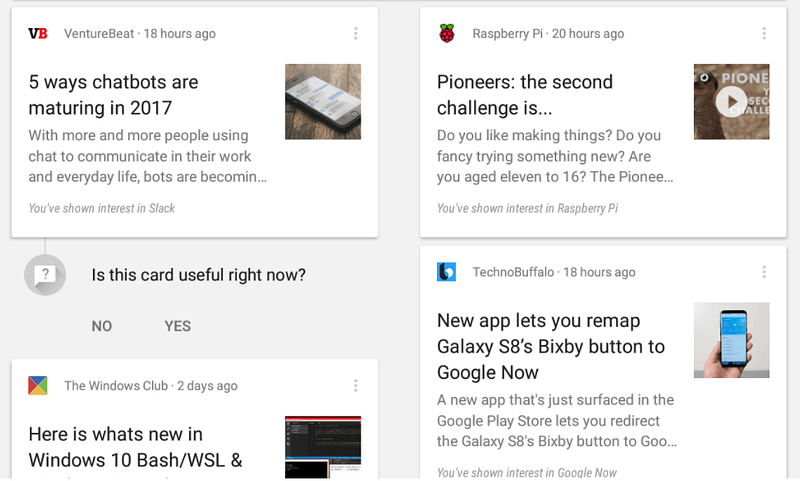
Google Now asking for feedback on the Recommendation System’ s predictions
Remember that user feedback can also act as training data for your model. The user experience of AI products gets better and better if we feed more data into the machine learning algorithms.
Final Takeaways
At the end of the day, AI is being designed to solve a problem and make lives easier. The human-centric design must be kept at its core at all times while developing a successful product. Not addressing client needs is the reason why major industries go bankrupt and get replaced by better service providers. Understanding clients needs is key to moving forward.
If you have thoughts or comments, feel free to subscribe to my blogs and follow me on Twitter.
Thanks to Wendy Wong.
Bio: Syed Sadat Nazrul is using Machine Learning to catch cyber and financial criminals by day... and writing cool blogs by night.
Original. Reposted with permission.
Related:
- DevOps for Data Scientists: Taming the Unicorn
- View from Google Assistant: Are we becoming reliant on AI?
- Top 10 roles in AI and data science