 Top 10 roles in AI and data science
Top 10 roles in AI and data science
 Top 10 roles in AI and data science
Top 10 roles in AI and data scienceWhen you think of the perfect data science team, are you imagining 10 copies of the same professor of computer science and statistics, hands delicately stained with whiteboard marker? We hope not!

Applied data science is a team sport that’s highly interdisciplinary. Diversity of perspective matters! In fact, perspective and attitude matter at least as much as education and experience.
If you’re keen to make your data useful with a decision intelligence engineering approach, here’s my take on the order in which to grow your team.
#0 Data Engineer
We start counting at zero, of course, since you need to have the ability to get data before it makes sense to talk about data analysis. If you’re dealing with small datasets, data engineering is essentially entering some numbers into a spreadsheet. When you operate at a more impressive scale, data engineering becomes a sophisticated discipline in its own right. Someone on your team will need to take responsibility for dealing with the tricky engineering aspects of delivering data that the rest of your staff can work with.
#1 Decision-Maker
Before hiring that PhD-trained data scientist, make sure you have a decision-maker who understands the art and science of data-driven decision-making.
Decision-making skills have to be in place before a team can get value out of data.
This individual is responsible for identifying decisions worth making with data, framing them (everything from designing metrics to calling the shots on statistical assumptions), and determining the required level of analytical rigor based on potential impact on the business. Look for a deep thinker who doesn’t keep saying, “Oh, whoops, that didn’t even occur to me as I was thinking through this decision.” They’ve already thought of it. And that. And that too.
#2 Analyst
Then the next hire is… everyone already working with you. Everyone is qualified to look at data and get inspired, the only thing that might be missing is a bit of familiarity with software that’s well-suited for the job. If you’ve ever looked at a digital photograph, you’ve done data visualization and analytics.
Learning to use tools like R and Python is just an upgrade over MS Paint for data visualization; they’re simply more versatile tools for looking at a wider variety of datasets than just red-green-blue pixel matrices
If you’ve ever looked at a digital photograph, you’ve done data visualization and analytics. It’s the same thing.
And hey, if all you have the stomach for is looking at the first five rows of data in a spreadsheet, well, that’s still better than nothing. If the entire workforce is empowered to do that, you’ll have a much better finger on the pulse of your business than if no one is looking at any data at all.

The important thing to remember is that you shouldn’t come to conclusions beyond your data. That takes specialist training. Just as with the photo above, here’s all you can say about it: “This is what is in my dataset.” Please don’t use it conclude that the Loch Ness Monster is real.
#3 Expert Analyst
Enter the lightning-fast version! This person can look at more data faster. The game here is speed, exploration, discovery… fun! This is not the role concerned with rigor and careful conclusions. Instead, this is the person who helps your team get eyes on as much of your data as possible so that your decision-maker can get a sense of what’s worth pursuing with more care.
The job here is speed, encountering potential insights as quickly as possible.
This may be counterintuitive, but don’t staff this role with your most reliable engineers who write gorgeous, robust code. The job here is speed, encountering potential insights as quickly as possible, and unfortunately those who obsess over code quality may find it too difficult to zoom through the data fast enough to be useful in this role.
Those who obsess over code quality may find it difficult to be useful in this role.
I’ve seen analysts on engineering-oriented teams bullied because their peers don’t realize what “great code” means for descriptive analytics. Great is “fast and humble” here. If fast-but-sloppy coders don’t get much love, they’ll leave your company and you’ll wonder why you don’t have a finger on the pulse of your business.

#4 Statistician
Now that we’ve got all these folks cheerfully exploring data, we’d better have someone around to put a damper on the feeding frenzy. It’s safe to look at that “photo” of Nessie as long as you have the discipline to keep yourself from learning more than what’s actually there… but do you? While people are pretty good at thinking reasonably about photos, other data types seem to send common sense out the window. It might be a good idea to have someone around who can prevent the team from making unwarranted conclusions.
Inspiration is cheap, but rigor is expensive.
Lifehack: don’t make conclusions and you won’t need to worry. I’m only half-joking. Inspiration is cheap, but rigor is expensive. Pay up or content yourself with mere inspiration.
Statisticians help decision-makers come to conclusions safely beyond the data.
For example, if your machine learning system worked in one dataset, all you can safely conclude is that it worked in that dataset. Will it work when it’s running in production? Should you launch it? You need some extra skills to deal with those questions. Statistical skills.
If we’re want to make serious decisions where we don’t have perfect facts, let’s slow down and take a careful approach. Statisticians help decision-makers come to conclusions safely beyond the data analyzed.
#5 Applied Machine Learning Engineer
An applied AI / machine learning engineer’s best attribute is not an understanding of how algorithms work. Their job is to use them, not build them. (That’s what researchers do.) Expertise at wrangling code that gets existing algorithms to accept and churn through your datasets is what you’re looking for.
Besides quick coding fingers, look for a personality that can cope with failure. You almost never know what you’re doing, even if you think you do. You run the data through a bunch of algorithms as quickly as possible and see if it seems to be working… with the reasonable expectation that you’ll fail a lot before you succeed. A huge part of the job is dabbling blindly, and it takes a certain kind of personality to enjoy that.
Perfectionists tend to struggle as ML engineers.
Because your business problem’s not in a textbook, you can’t know in advance what will work, so you can’t expect to get a perfect result on the first go. That’s okay, just try lots of approaches as quickly as possible and iterate towards a solution.
Speaking of “running the data through algorithms”… what data? The inputs your analysts identified as potentially interesting, of course. That’s why analysts make sense as an earlier hire.
Although there’s a lot of tinkering, it’s important for the machine learning engineer to have a deep respect for the part of the process where rigor is vital: assessment. Does the solution actually work on new data? Luckily, you made a wise choice with your previous hire, so all you have to do is pass the baton to the statistician.
The strongest applied ML engineers have a very good sense of how long it takes to apply various approaches.
When a potential ML hire can rank options by the time it takes to try them on various kinds of datasets, be impressed.

#6 Data Scientist
The way I use the word, a data scientist is someone who is a full expert in all of the three preceding roles. Not everyone uses my definition: you’ll see job applications out there with people calling themselves “data scientist” when they have only really mastered one of the three, so it’s worth checking.
Data scientist are full experts in all of the three previous roles.
This role is in position #6 because hiring the true three-in-one is an expensive option. If you can hire one within budget, it’s a great idea, but if you’re on a tight budget, consider upskilling and growing your existing single-role specialists.
#7 Analytics Manager / Data Science Leader
The analytics manager is the goose that lays the golden egg: they’re a hybrid between the data scientist and the decision-maker. Their presence on the team acts as a force-multiplier, ensuring that your data science team isn’t off in the weeds instead of adding value to your business.
The decision-maker + data scientist hybrid is a force-multiplier. Unfortunately, they’re rare and hard to hire.
This person is kept awake at night by questions like, “How do we design the right questions? How do we make decisions? How do we best allocate our experts? What’s worth doing? Will the skills and data match the requirements? How do we ensure good input data?”
If you’re lucky enough to hire one of these, hold on to them and never let them go. Learn more about this role here.
#8 Qualitative Expert / Social Scientist
Sometimes your decision-maker is a brilliant leader, manager, motivator, influencer, or navigator of organizational politics… but unskilled in the art and science of decision-making. Decision-making is so much more than a talent. If your decision-maker hasn’t honed their craft, they might do more damage than good.
Instead of firing an unskilled decision-maker, you can augment them with a qualitative expert.
Don’t fire an unskilled decision-maker, augment them. You can hire them an upgrade in the form of a helper. The qualitative expert is here to supplement their skills.
This person typically has a social science and data background — behavioral economists, neuroeconomists, and JDM psychologists receive the most specialized training, but self-taught folk can also be good at it. The job is to help the decision maker clarify ideas, examine all the angles, and turn ambiguous intuitions into well-thought-through instructions in language that makes it easy for the rest of the team to execute on.
We don’t realize how valuable social scientists are. They’re usually better equipped than data scientists to translate the intuitions and intentions of a decision-maker into concrete metrics.
The qualitative expert doesn’t call any of the shots. Instead, they ensure that the decision-maker has fully grasped the shots available for calling. They’re also a trusted advisor, a brainstorming companion, and a sounding board for a decision-maker. Having them on board is a great way to ensure that the project starts out in the right direction.
#9 Researcher
Many hiring managers think their first team member needs to be the ex-professor, but actually you don’t need those PhD folk unless you already know that the industry is not going to supply the algorithms that you need. Most teams won’t know that in advance, so it makes more sense to do things in the right order: before building yourself that space pen, first check whether a pencil will get the job done. Get started first and if you find that the available off-the-shelf solutions aren’t giving you much love, then you should consider hiring researchers.
If a researcher is your first hire, you probably won’t have the right environment to make good use of them.
Don’t bring them in right off the bat. It’s better to wait until your team is developed enough to have figured out that what they need a researcher for. Wait till you’ve exhausted all the available tools before hiring someone to build you expensive new ones.

#10+ Additional personnel
Besides the roles we looked at, here are some of my favorite people to welcome to a decision intelligence project:
- Domain expert
- Ethicist
- Software engineer
- Reliability engineer
- UX designer
- Interactive visualizer / graphic designer
- Data collection specialist
- Data product manager
- Project / program manager
Many projects can’t do without them — the only reason they aren’t listed in my top 10 is that decision intelligence is not their primary business. Instead, they are geniuses at their own discipline and have learned enough about data and decision-making to be remarkably useful to your project. Think of them as having their own major or specialization, but enough love for decision intelligence that they chose to minor in it.
Huge team or small team?
After reading all that, you might feel overwhelmed. So many roles! Take a deep breath. Depending on your needs, you may get enough value from the first few roles.
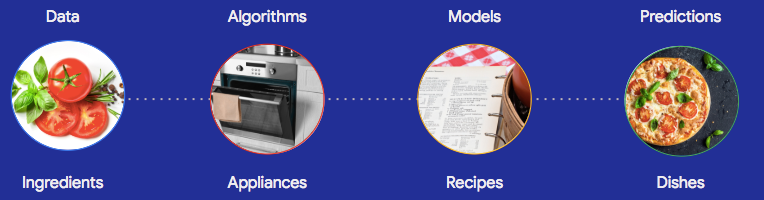
Revisiting my analogy of applied machine learning as innovating in the kitchen, if you personally want to open an industrial-scale pizzeria that makes innovative pizzas, you need the big team or you need to partner with providers/consultants. If you want to make a unique pizza or two this weekend — caramelized anchovy surprise, anyone? — then you still need to think about all the components we mentioned. You’re going to decide what to make (role 1), which ingredients to use (roles 2 and 3), where to get ingredients (role 0), how to customize the recipe (role 5), and how to give it a taste test (role 4) before serving someone you want to impress, but for the casual version with less at stake, you can do it all on your own. And if your goal is just to make standard traditional pizza, you don’t even need all that: get hold of someone else’s tried and tested recipe (no need to reinvent your own) along with ingredients and start cooking!
Bio: Cassie Kozyrkov, Chief Decision Engineer at Google Cloud. Love Stats, AI, data,puns, art, sci-fi, theatre, decision science.
Original. Reposted with permission.
Related: