5 Things to Know About A/B Testing
This article presents 5 things to know about A/B testing, from appropriate sample sizes, to statistical confidence, to A/B testing usefulness, and more.
An A/B test is a randomized experiment, in which the "A" and "B" refer to 2 variants, undertaken in order to determine which variant is the more "effective." A popular tool in web analytics, A/B testing is not well understood by everyone, including those who utilize it regularly. Sound A/B testing should be firmly rooted in statistical hypothesis testing, yet this is not always the case.
Beyond hypothesis testing, there are all sorts of additional concerns when designing, executing, and interpreting the results of A/B testing. You can read about the basics in this article.
This article presents 5 things to know about A/B testing.
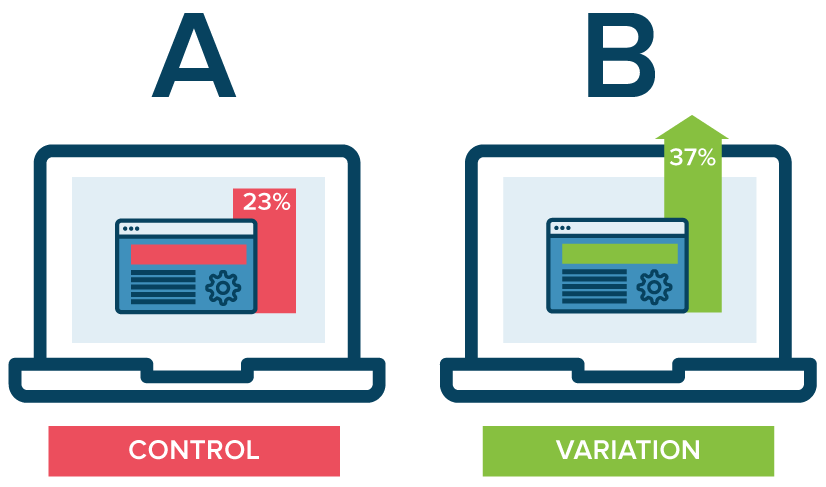
Source: Optimizely
1. Don't make conclusions based on small sample sizes
This should seem obvious to anyone with an inkling of statistical understanding, but it's so important that it's worth including, and putting first.
Sample sizes for A/B testing is a tricky business, and not as straightforward as most think (or would hope). But this is really only one piece of a larger puzzle related to statistical confidence, which can only come with both the necessary number of samples and required time for the experiment to play out. Properly experiment design will take into account the number of samples and conversions required for a desired statistical confidence, and will allow the experiment to play out fully, without pulling the plug ahead of time because there appears to be a winner.
You can read more about sample size and calculating statistical confidence for A/B tests here.
2. Don't overlook the psychology of A/B testing
Let's say you are putting together an email A/B test. The experiment is set up so that both groups have the same email content, but differ in their subject lines. These subject line variants are what are being tested, and since these subject lines are visible to the user prior to opening the email (and are, in fact, being used to measure the effectiveness of the email), the metric here to test is obviously email open rate, right?
That depends. What is the goal of the campaign? Are you interested in only having it opened (or, indirectly, read)? More likely, the goal is to get the user to follow through on some call to action (a click, for example), and so this CTA, click rate, is likely the better metric.
But how can the already-visible subject line lead to differing click rates after they have opened the email? It's all about psychology. Take an example: your email is a campaign for a data science conference, which is to be headlined by data science superstar Jane Q. Public, and is being held in Boston. You have 2 competing subject lines:
- Learn data science from the very best!
- Join Jane Q. Public this November in Boston for Data Conference 2018
You have set expectations with these subjects, and only one of them is realistically specific. Fishing for opens with the first has not prepared the reader for what might be inside, and there is a much higher chance of disappointment or of their expectations not being met, and so clicks will undoubtedly suffer. The second, on the other hand, has set the expectation that the email contains information which it actually does, and those who have opened are much more likely to click through.

3. Beware the local minima; A/B testing isn't for everything
A/B testing won't fix everything, as it is not suited for everything.
Changing a landing page is probably a good A/B testing candidate. Changing a button position on your website or form may be a good AB test. A complete website redesign may or may not be a good AB test, depending on how the experiment is approached.
Generally, incremental change is well-suited to A/B testing. However, incremental changes, which may in and of themselves make valid A/B testing variant candidates, may not accomplish what you want, simply because you are assuming that you are starting out from a good place. Conceptualizing your product as a mathematical function, the local minima would be analogous to a design rut which has been reached. Your product can become firmly entrenched in this design local minima when you fail to consider that tweaking your existing product (the starting point, within which one of your A/B test variants currently dwells) may be going for the fool's gold when a global minima (or even a more desirable local minima) could be achieved by taking a more comprehensive approach to product redesign. We all know about putting lipstick on pigs.
The point is that jumping head first into A/B testing is not a good idea. Define your goals, first, and once you decide that A/B testing may be able to help you with your goals, then decide on your experiments. After that, design your experiments. Only then should you implement A/B tests.
4. It's all about the buckets
First, let’s consider how we can best ensure comparability between buckets prior to bucket assignment, without knowledge of any distribution of attributes in the population.
The answer here is simple: random selection and bucket assignment. Random selection and assignment to buckets without regard to any attribute of the population is a statistically sound approach, given a large enough population to draw from.
For example, let’s say you are testing a change to a website feature and are interested in response from only a particular region, the US. By first splitting into 2 groups (control and treatment) without regard to user region (and given a large enough population size), assignment of US visitors should be split between these groups. From these 2 buckets, visitor attributes can then be inspected for the purposes of testing, such as:
if (region == "US" && bucket == "treatment"):
# do something treatment-related here
else:
if (region == "US" && bucket == "control"):
# do something control-related here
else:
# catch-all for non-US (and not relevant to testing scenario)
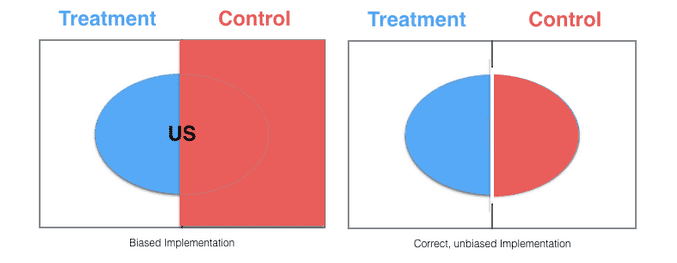
Source: Twitter Engineering
A second concern is bucket skew. Data scientist Emily Robinson, formerly involved in A/B testing at Etsy, writes:
Bucketing skew, also known as sample ratio mismatch, is where the split of people between your variants does not match what you planned. For example, maybe you wanted to split people between the control and treatment 50/50 but after a few days, you find 40% are in the treatment and 60% in the control. That’s a problem! If you have lots of users, even observing 49.9% in the control and 50.1% in the treatment can indicate a problem with your set-up. To check if you have an issue, run a proportion test with the number of visitors in each group and check if your p-value is less than .05. If you do have bucketing skew, you have a bug. Unfortunately, it can be difficult to find it, but a good place to start is checking is if the skew differs based on web browser, country, or another visitor factor.
The rest of Emily's article is also fantastic, and I encourage you to read it.
5. Only include people in your analysis who could have been affected by the change
Point #11 in Emily's article (mentioned above) tackles this idea:
If you have users in your experiment whose experience could not have been impacted by your change, you’re adding noise and reducing your ability to detect an effect.
Great advice! Emily then presents a pair of intuitive examples:
- If you change a particular page layout, only add users to the experiment if they actually visit that page
- If you experiment with lowering your free shipping threshold from $X to $Y, you should only include in the experiment those users who have cart sizes between $X and $Y; they would be the only users to see a difference in the treatment vs control group
Emily follows this up with related advice: only start tracking your metrics after a user visits a relevant web page:
Imagine you’re running an experiment on the search page, and someone visits your sites, buys something from the homepage, and then visits the search page, entering the experiment.
It should be evident that A/B testing is a speciality in its own right, and entering into experiments without due process is an exercise in confoundment. Hopefully within these 5 simple points you were able to find something useful to further explore.
Related:
- 5 Tricks When A/B Testing Is Off The Table
- Must-Know: Key issues and problems with A/B testing
- Deep Conversations: Lisha Li, Principal at Amplify Partners