Deep Learning on the Edge
Detailed analysis into utilizing deep learning on the edge, covering both advantages and disadvantages and comparing this against more traditional cloud computing methods.
By Bharath Raj.

Scalable Deep Learning services are contingent on several constraints. Depending on your target application, you may require low latency, enhanced security or long-term cost effectiveness. Hosting your Deep Learning model on the cloud may not be the best solution in such cases.
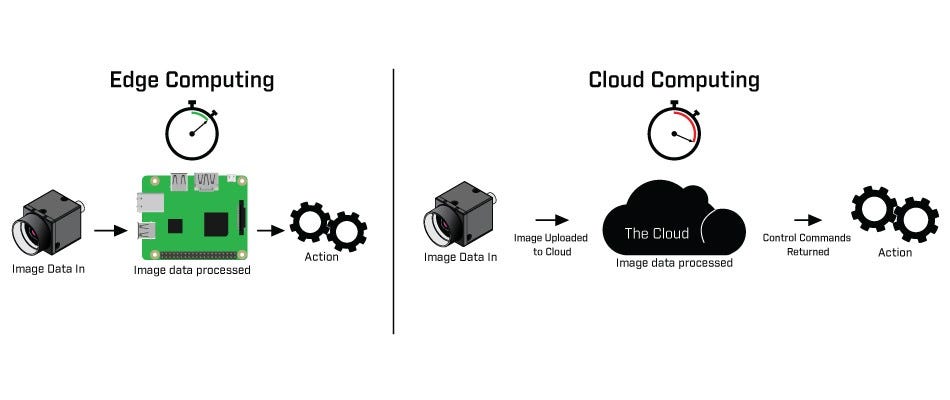
Deep Learning on the edge alleviates the above issues, and provides other benefits. Edge here refers to the computation that is performed locally on the consumer’s products. This blog explores the benefits of using edge computing for Deep Learning, and the problems associated with it.
Why edge? Why not use the cloud?
There is a plethora of compelling reasons to favor edge computing over cloud computing.
1. Bandwidth and Latency
It’s no doubt that there’s a tangible Round Trip Time (RTT) associated with API calls to a remote server. Applications that demand near instantaneous inference can not function properly with the latency.

Take self driving cars for example. A large enough latency could significantly increase the risk of accidents. Moreover, unexpected events such as animal crossing or jay walking can happen over just a few frames. In these cases, response time is extremely critical. This is why Nvidia has their custom on-board compute devices to perform inference on the edge.
Moreover, when you have a large number of devices connected to the same network, the effective bandwidth is reduced. This is because of the inherent competition to use the communication channel. This can be significantly reduced if computation is done on the edge.
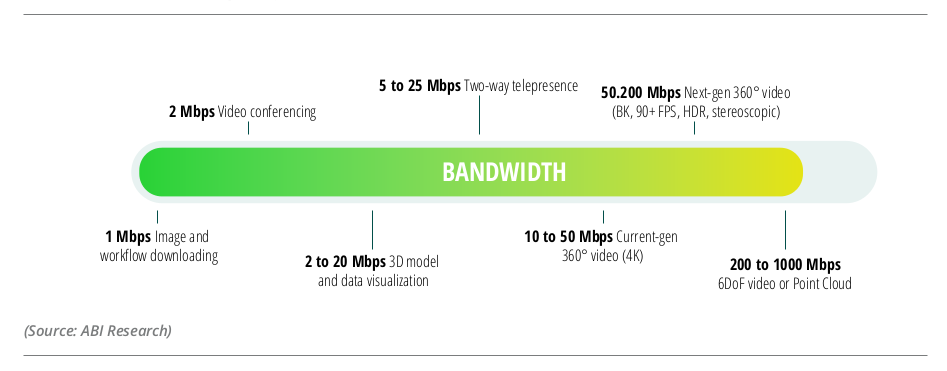
Take the case of processing 4K HD videos on multiple devices. Processing them locally would heavily save bandwidth usage. This is because we do not need to upload data to the cloud for inference. Due to this, we can scale this network relatively easily.
2. Security and Decentralization
Commercial servers are prone to attacks and hacks. Of course, the risk is negligible if you use a trusted vendor. But, you are required to trust a third party for the security of the data you collect and your intellectual property (IP). Having devices on the edge gives you absolute control over your IP.

If you’ve heard about blockchain, decentralization or distribution may be familiar to you. Nonetheless, having several devices on the edge reaps all the benefits of decentralization. It’s harder to bring down an entire network of hidden devices using a single DDoS attack, than a centralized server. This is especially useful for applications such as using drones for border patrol.
3. Job Specific Usage (Customization)
Imagine you have a factory that produces toys. It has a couple hundred work stations. You require an image classification service at every work station. Problem is, each work station has a different set of objects, and training a single classifier may not be effective. Moreover, hosting multiple classifierson the cloud would be expensive.
The cost effective solution is to train classifiers specific to each part on the cloud, and ship the trained models to the edge devices. Now, these devices are customized to their work station. They would have better performance than a classifier predicting across all work stations.
4. Swarm Intelligence
Continuing with the idea mentioned above, edge devices can aid in training machine learning models too. This is especially useful for Reinforcement Learning, for which you could simulate a large number of “episodes” in parallel.

Moreover, edge devices can be used to collect data for Online Learning (or Continuous Learning). For instance, we can use multiple drones to survey an area for classification. Using optimization techniques such as Asynchronous SGD, a single model can be trained in parallel among all edge devices. It can also be merely used for aggregating and processing data from various sources.
5. Redundancy
Redundancy is extremely vital for robust memory and network architectures. Failure of one node in a network could have serious impacts on the other nodes. In our case, edge devices can provide a good level of redundancy. If one of the our edge devices (here, a node) fail, its neighbor can take over temporarily. This greatly ensures reliability and heavily reduces downtime.
6. Cost effective in the long run
In the long run, cloud services will turn out to be more expensive than having a dedicated set of inference devices. This is especially true if your devices have a large duty cycle (that is, they are working most of the time). Moreover, edge devices are much cheaper if they’re fabricated in bulk, reducing the cost significantly.
Constraints for Deep Learning on the Edge
Deep Learning models are known for being large and computationally expensive. It’s a challenge to fit these models into edge devices which usually have frugal memory. There are a number of ways by which we can approach these problems.
1. Parameter Efficient Neural Networks
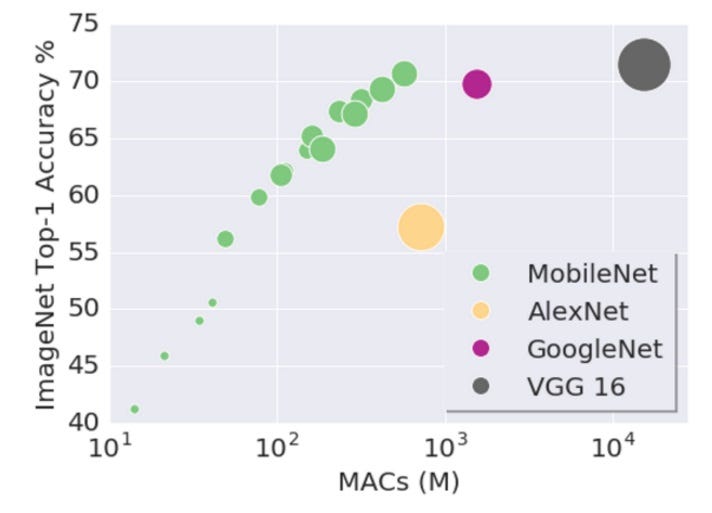
A striking feature about neural networks is their enormous size. Edge devices typically can not handle large neural networks. This motivated researchers to minimize the size of the neural networks, while maintaining accuracy. Two popular parameter efficient neural networks are the MobileNet and the SqueezeNet.
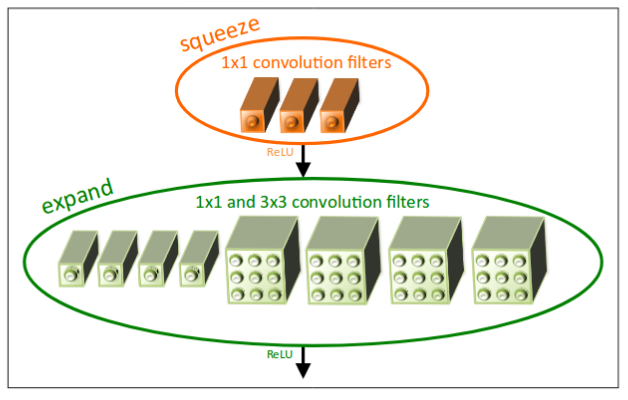
The SqueezeNet incorporates a lot of strategies such as late down-sampling and filter count reduction, to get high performance at a low parameter count. They introduce “Fire modules” that have “squeeze” and “expand” layers that optimize the parameter efficiency of the network.
The MobileNet factorizes normal convolutions into a combination of depth wise convolutions and 1x1 convolutions. This arrangement greatly reduces the number of parameters involved.
2. Pruning and Truncation
A large number of neurons in trained networks are benign and do not contribute to the final accuracy. In this case, we can prune such neurons to save some space. Google’s Learn2Compress has found that we can obtain asize reduction by factor of 2, while retaining 97% of the accuracy.
Moreover, most neural network parameters are 32 bit float values. Edge devices on the other hand can be designed to work on 8 bit values, or less. Reducing precision can significantly reduce the model size. For instance, reducing a 32 bit model to 8 bit model ideally reduces model size by a factor of 4.
3. Distillation
Distillation is the process of teaching smaller networks using a larger “teacher” network. Google’s Learn2Compress incorporates this in their size reduction process. Combined with transfer learning, this becomes a powerful method to reduce model size without losing much accuracy.
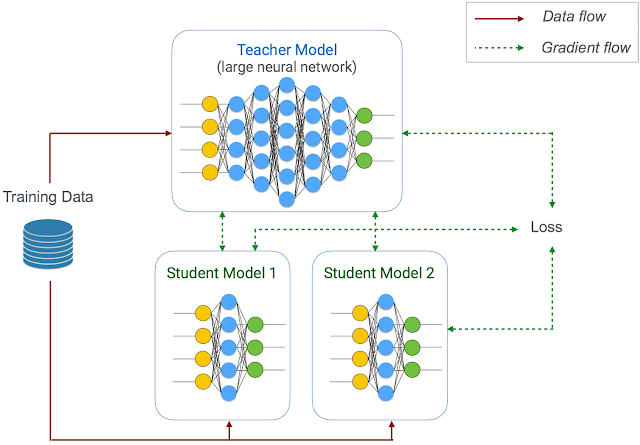
4. Optimized Microprocessor Designs
So far we have discussed way to scale down neural networks to fit in our edge devices. An alternate (or complementary) method would be to scale up the performance of the microprocessor.
The simplest solution would be to have a GPU on a microprocessor, such as the popular Nvidia Jetson. However, these devices may not be cost effective when deployed on a large scale.

A more interesting solution would be to use Vision Processing Units (VPUs). Intel claims that their Movidius VPUs have “high speed performance at an ultra low power consumption”. Google’s AIY kits and Intel’s Neural Compute Stick internally use this VPU.

Alternatively, we could use FPGAs. They have low power consumption than GPUs and can accommodate lower bit (< 32 bit) architectures. However, there could be a slight drop in performance compared to GPUs owing to their lower FLOPs rating.
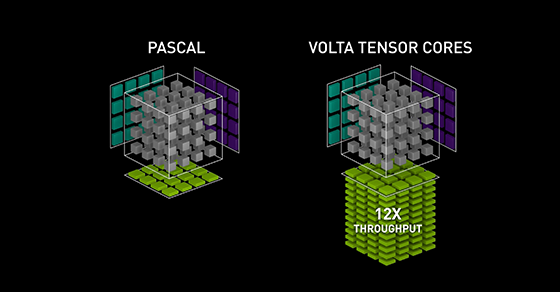
For large scale deployment, custom ASICs would be the best solution. Fabricating micro-architectures similar to Nvidia’s V100 to accelerate matrix multiplications could greatly boost performance.
Original. Reposted with permission.
Bio: Bharath Raj is an undergraduate student at SSN who loves to experiment with Machine Learning and Computer Vision concepts. Bharath writes code and tech blogs. You can check out his projects here.
Related:
- Top /r/MachineLearning posts, August 2018: Everybody Dance Now; Stanford class Machine Learning cheat sheets; Academic Torrents for sharing enormous datasets
- See NVIDIA Deep Learning In Action [Webinar Series]
- Machine Learning Cheat Sheets