Deep Learning for the Masses (… and The Semantic Layer)
Deep learning is everywhere right now, in your watch, in your television, your phone, and in someway the platform you are using to read this article. Here I’ll talk about how can you start changing your business using Deep Learning in a very simple way. But first, you need to know about the Semantic Layer.
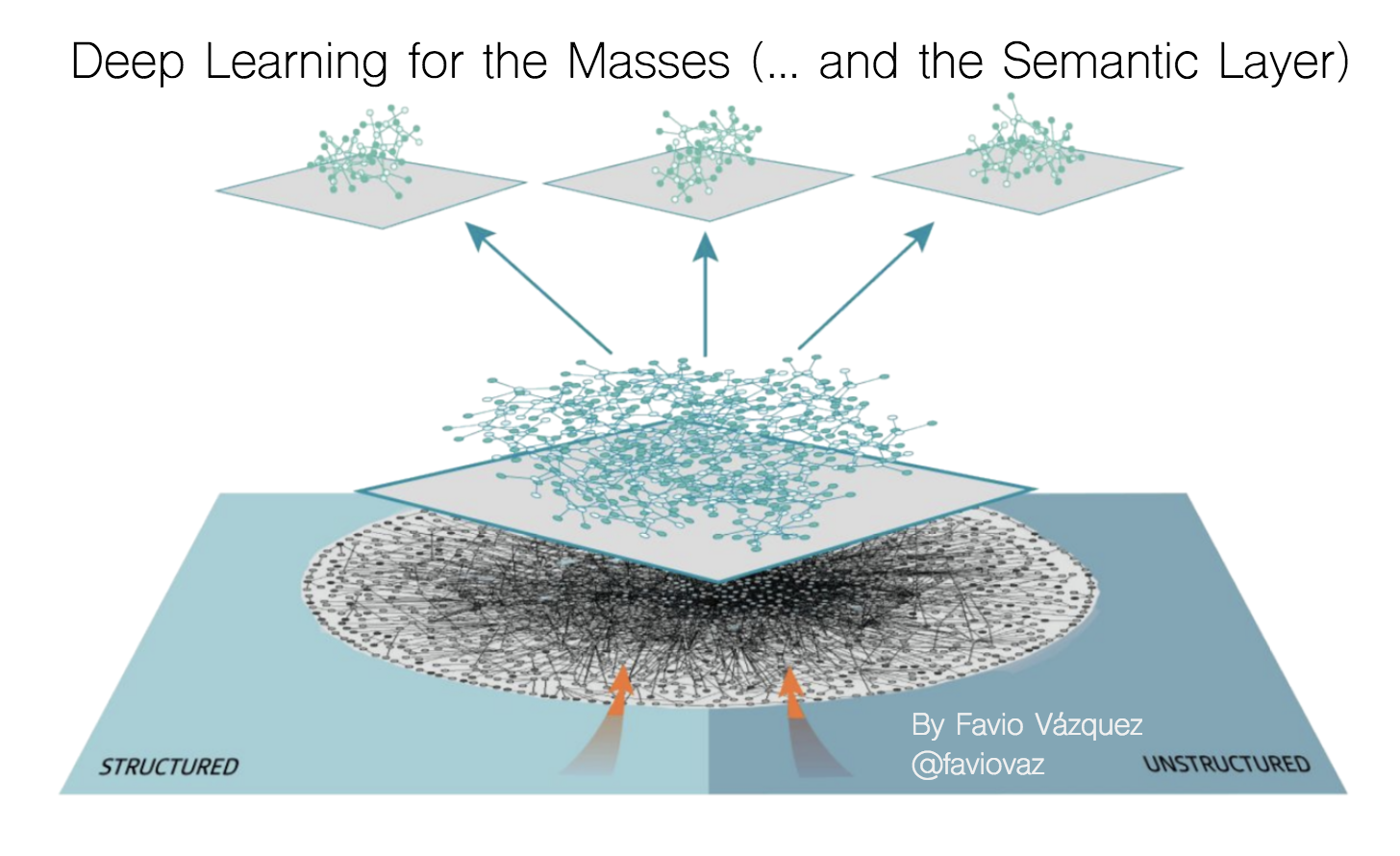
Introduction to Deep Learning
The scope of this article is not introducing Deep Learning, I’ve done that in other articles you can find here:
But if you want a taste of it from here this is what I can say to you:
… deep learning is representation learning using different kinds of neural networks [deep neural networks] and optimizing the hyperparameters of the nets to get (learn) the best representation for our data.
If you want to know where that comes from read the articles above.
Deep Learning is not that hard

This is harder
Right now deep learning for organizations is not that hard. I’m not saying that Deep Learning as a whole is easy, research in the field requires a lot of knowledge of mathematics, calculus, statistics, machine learning, computing and more. You can see where Deep Learning is coming from from this timeline I created a while ago.
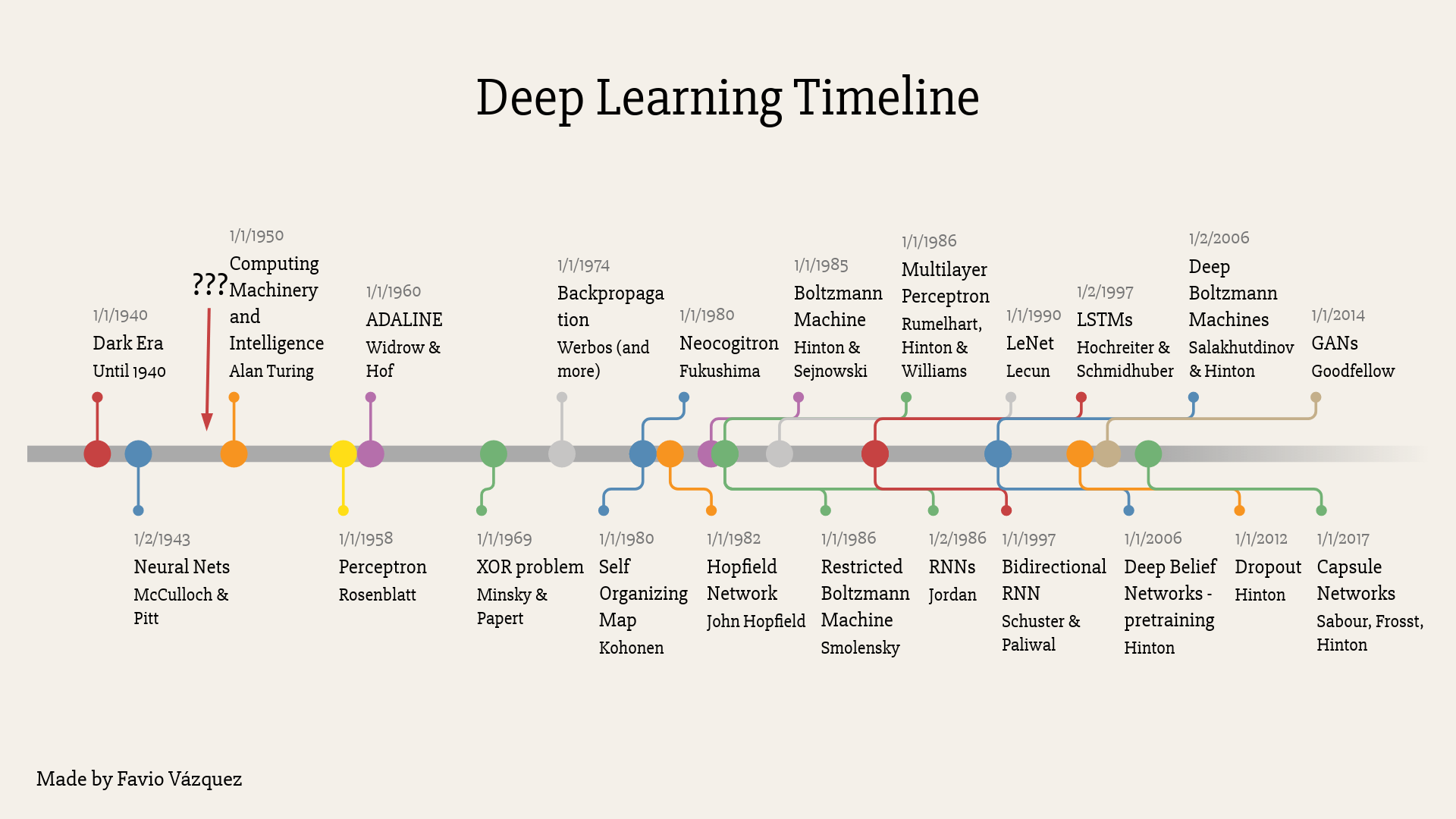
From there I can say the ideas of Back Propagation, better initialization of the parameters of the nets, better activation functions, the concept of Dropout, and some types of networks like Convolutional Neural Nets, Residual Nets, Region Bases CNNs, Recurrent Neural Networks and Generative Adversarial networks, are one of the most important advances we made in the Deep Learning world.
But how can you use Deep Learning right now?

hehe
Data comes first

Oh, you’d want to be them. Right?. Or maybe not, IDK.
Well do you want to know the secret? The secret sauce that the big technology companies use? It’s not only Deep Learning (maybe it’s not Deep Learning at all)
I’m not going to give a full speech here, but it all starts with the data. As you can image, data is an important asset (maybe the most important one) for companies right now. So before you can apply machine learning or deep learning, at all, you need to have it, know what you have, understand it, govern it, clean it, analyze it, standardize it (maybe more) and then you can think of using it.
Taking from Brian Godsey’s amazing article:
In whichever form, data is now ubiquitous, and rather than being merely a tool that analysts might use to draw conclusions, it has become a purpose of its own. Companies now seem to collect data as an end, not a means, though many of them claim to be planning to use the data in the future. Independent of other defining characteristics of the Information Age, data has gained its own role, its own organizations, and its own value.
So you can see that it’s not only applying the latest algorithms to your data, it’s to be able to have it in a good format and understand it to then use it.
The Semantic Layer

These layers mean something. Ok but this is not the semantic layer. Keep reading.
This is something unusual to hear from me, but I’ve been investigating a lot, and working with several companies, and they all seem to have the same problem. Their data.
Data availability, data quality, data ingestion, data integration and more are common problems that will affect not only the data science practice, but the organization as a whole.
There are ways for cleaning your data and prepare for machine learning and there are great tools and methodology for that, you can read more here:
But that asumes that you have a process for ingesting and integrating your data. Right now there are great tools to for AutoML, and I’ve talked about that before:
And other commercial tools like DataRobot:
But what about automatic ingestion and integration?
That’s one of the amazing benefits of the semantic layer. But what on earth is the semantic layer?
The word semantic itself implies meaning or understanding. As such, the semantic layer is related to data in concerning the meaning and not the structure of data.
Understanding it’s a very important process that I’ve talked about before:
Here I mention (from Lex Fridman) that:
Understanding is the ability to turn complex information into simple, useful information.
When we are understanding we are decoding the parts that form this complex thing, and transforming the raw data we got in the beginning to something useful and simple to see. We do this by modeling. And as you can imagine we need such models to understand the meaning of data.
Linked Data and the Knowledge Graph
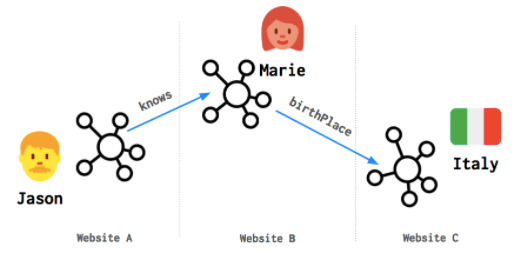
The first thing we need to do is Link Data. The goal of Linked Data is to publish structured data in such a way that it can be easily consumed and combined with other Linked Data.
Linked Data is the new de-facto standard for data publication and interoperability on the Web and is moving into enterprises as well. Big players such as Google, Facebook, Amazon and Microsoft, already adopted some of the principles behind it.
The process of linking data is the beginning of something called the Knowledge Graph. A knowledge graph is an advanced way to map all of knowledge on a particular topic to fill the gaps on how is the data related, or wormholes inside of databases.
The knowledge graph consists in integrated collections of data and information that also contains huge numbers of links between different data.
The key here is that instead of looking for possible answers, under this new model we’re seeking an answer. We want the facts — where those facts come from is less important.
The data here can represent concepts, objects, things, people and actually whatever you have in mind. The graph fills in the relationships, the connections between the concepts.
Here’s an amazing introduction to the knowledge graph by Google from 6 years ago (yep 6 years):
What does the Knowledge Graph mean for you and your company?
In the old-fashion way, the data model in the data warehouse, while an awesome achievement, cannot absorb the huge amount of data that is coming at us. The process of creating relational data models just can’t keep up. In addition, the extracts of data that are used to power data discovery are also too small.
Data Lakes, based on Hadoop or Cloud storage have therefore proliferated into data swamps — without the required management and governance capabilities.

https://timoelliott.com/blog/2014/12/from-data-lakes-to-data-swamps.html
Have you asked your data engineers and scientists if they understand all the data your organization has? Do it.
It’s extremely hard also to analyze all the data you have. And understand what relationships are behind it.
Because they are graphs, knowledge graphs are more intuitive. People don’t think in tables, but they do immediately understand graphs. When you draw the structure of a knowledge graph on a whiteboard, it is obvious what it means to most people.
Knowledge graphs also allow you to create structures for the relationships in the graph. You can tell a graph that parents have children and parents can be children and children can be brothers or sisters, and all of these are people. Providing such descriptive information allows new information to be inferred from the graph such as the fact that if two people have the same parents they must be siblings.