Variational Autoencoders Explained in Detail
We explain how to implement VAE - including simple to understand tensorflow code using MNIST and a cool trick of how you can generate an image of a digit conditioned on the digit.

In the previous post of this series I introduced the Variational Autoencoder (VAE) framework, and explained the theory behind it.
In this post I’ll explain the VAE in more detail, or in other words — I’ll provide some code :)
After reading this post, you’ll understand the technical details needed to implement VAE.
As a bonus point, I’ll show you how by imposing a special role to some of the latent vector’s dimensions, the model can generate images conditioned on the digit type.
The model will be trained on MNIST — handwritten digits dataset. The input is an image in ℝ[28∙28].
Next we’ll define the hyperparameters we’re going to use.
Feel free to play with different values to get a feeling of how the model is affected. The notebook can be found here.
The model

The model is composed of three sub-networks:
- Given x(image), encode it into a distribution over the latent space — referred to as Q(z|x) in the previous post.
- Given zin latent space (code representation of an image), decode it into the image it represents — referred to as f(z) in the previous post.
- Given x, classify its digit by mapping it to a layer of size 10 where the i’th value contains the probability of the i’th digit.
The first two sub-networks are the vanilla VAE framework.
The third one is used as an auxiliary task, which will enforce some of the latent dimensions to encode the digit found in an image. Let me explain the motivation: in the previous post I explained that we don’t care what information each dimension of the latent space holds. The model can learn to encode whatever information it finds valuable for its task. Since we’re familiar with the dataset, we know the digit type should be important. We want to help the model by providing it with this information. Moreover, we’ll use this information to generate images conditioned on the digit type, as I’ll explain later.
Given the digit type, we’ll encode it using one hot encoding, that is, a vector of size 10. These 10 numbers will be concatenated into the latent vector, so when decoding that vector into an image, the model will make use of the digit information.
There are two ways to provide the model with a one hot encoding vector:
- Add it as an input to the model.
- Add it as a label so the model will have to predict it by itself: we’ll add another sub-network that predicts a vector of size 10 where the loss is the cross entropy with the expected one hot vector.
We’ll go with the second option. Why? Well, in test time we can use the model in two ways:
- Provide an image as input, and infer a latent vector.
- Provide a latent vector as input, and generate an image.
Since we want to support the first option too, we can’t provide the model with the digit as input, since we won’t know it in test time. Hence, the model must learn to predict it.
Now that we understand all the sub-networks composing the model, we can code them. The mathematical details behind the encoder and decoder can be found in the previous post.
Training

We’ll train the model to optimize the two losses — the VAE loss and the classification loss — using SGD.
At the end of every epoch we’ll sample latent vectors and decode them into images, so we can visualize how the generative power of the model improves over the epochs. The sampling method is as follows:
- Deterministically set the dimensions which are used for digit classification according to the digit we want to generate an image for. If for example we want to generate an image of the digit 2, these dimensions will be set to [0010000000].
- Randomly sample the other dimensions according to the prior — a multivariate Gaussian. We’ll use these sampled values for all the different digits we generate in a given epoch. This way we can have a feeling of what is encoded in the other dimensions, for example stroke style.
The intuition behind step 1 is that after convergence the model should be able to classify the digit in an input image using these dimensions. On the other hand, these dimensions are also used in the decoding step to generate the image. It means the decoder sub-network learns that when these dimensions have the values corresponding to the digit 2, it should generate an image of that digit. Therefore, if we manually set these dimensions to contain the information of the digit 2, we’ll get a generated image of that digit.
Let’s verify both losses look good, that is — decreasing:
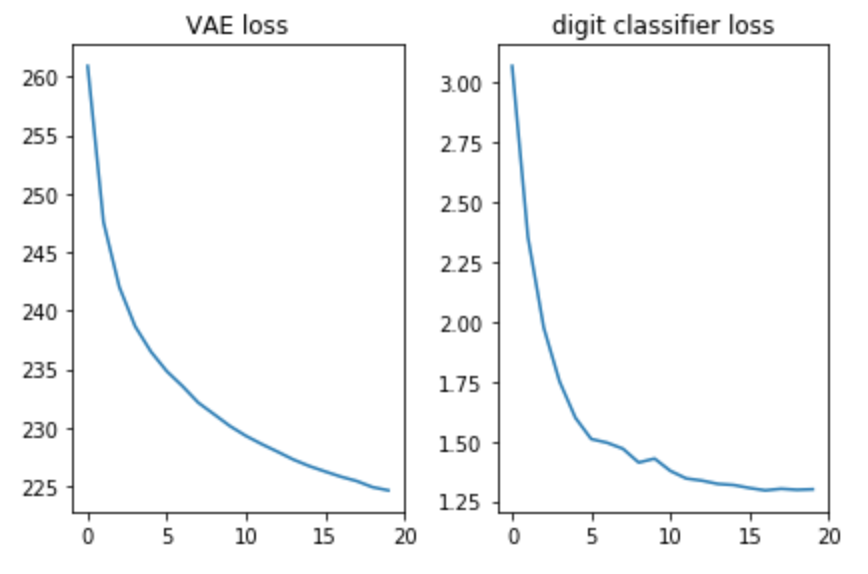
Additionally, let’s plot the generated images to see if indeed the model was able to generate images of digits:

Final thoughts
It’s nice to see that using a simple feed forward network (no fancy convolutions) we’re able to generate nice looking images after merely 20 epochs. The model learned to use the special digit dimensions quite fast — at epoch 9 we already see the sequence of digits we were trying to generate.
Every epoch used different random values for the other dimensions, so we can see how the style differs between epochs, and is similar inside every epoch — at least for some of the epochs. At epoch 18 for instance all the digits are bolder compared to epoch 20.
I invite you to open this notebook and play around with the VAE. The hyperparameter values for instance have a great effect over the generated images. Have fun :)
Bio: Yoel Zeldes is a Algorithms Engineer at Taboola and is also a Machine Learning enthusiast, who especially enjoys the insights of Deep Learning.
Original. Reposted with permission.
Resources:
- on-line and web-based: Analytics, Data Mining, Data Science, Machine Learning education
- Software for Analytics, Data Science, Data Mining, and Machine Learning
Related: