How will automation tools change data science?
This article provides an overview of recent trends in machine learning and data science automation tools and addresses how those tools will change data science.
By Dr. Ryohei Fujimaki, CEO and Founder of dotData
Data science is now a major area of technology investment, given its impact on customer experience, revenue, operations, supply chain, risk management and many other business functions. Data science enables a data-centric decision-making process for organizations, accelerating digital transformation and AI initiatives. According to Gartner, Inc. only four percent of CIOs have implemented AI, and only 46 percent have plans to do so. While investments continue to grow, many enterprises find it increasingly challenging to implement and accelerate data science practices. This article provides an overview of recent trends in machine learning and data science automation tools and addresses how those tools will change data science.
Traditional Data Science Process
So what is preventing the adoption and acceleration of data science in enterprises? A typical enterprise data science project is highly complex and involves many steps, including data collection, last-mile ETL* (data wrangling), feature engineering, machine learning, visualization and production (see illustration below). A traditional data science project takes several months to complete even for an experienced team. It is a highly involved and collaborative process that requires a wide range of specialized skill sets, such as domain experts, data engineers, data scientists, business intelligence engineers, and software architects. In addition, the outcome of most enterprise data science projects are hard to interpret, making it difficult for business users to implement the results.
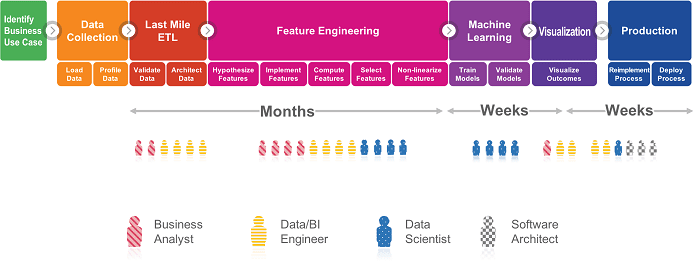
Traditional Data Science Process
What Makes Data Science Hard?
Playing with machine learning (ML) models is considered to be the fun part, but the real pain point of any data science project is often last-mile ETL and feature engineering. As illustrated below, machine learning requires a single flat table called a feature table. Given a feature table, data scientists can play with ML algorithms. But actual enterprise data is never a single flat table. Instead, it’s a collection of many data tables with complex relationships.
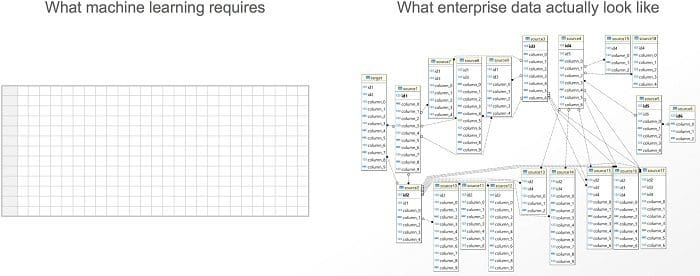
Data required by machine learning (left) vs. Actual enterprise source data (right)
Last-mile ETL and feature engineering are necessary steps to transform the collection of tables into a feature table. These are the most challenging and time-consuming steps in a data science project and require highly skilled data scientists and domain experts – expensive and scarce resources.
“… Feature engineering is typically where most of the effort in a machine learning project goes … and where intuition, creativity and “black art” are as important as the technical stuff…”. - Dr. Pedro Domingos**
Data Science and Machine Learning Automation Tools
Trials to automate machine learning have started in early 2010’s (e.g. AutoWEKA in 2013) and has become very trendy. DataRobot and H2O.ai are leading startups in machine learning automation.
The fundamental idea of machine learning automation is to train scoring models using different algorithms (including preprocessing like missing value imputation) with different hyper-parameters, and validate their accuracy to select the best model. Recently, companies like Microsoft have also started to support machine learning automation tools (more details can be found here or here). These great tools significantly simplify building machine learning models. On the other hand, last-mile ETL and feature engineering is still a manual process and requires the substantial involvement of domain experts and data scientists.
Although there have been efforts to automate feature engineering, most of them focus on non-linear transformations of a given feature table, which is just a small component of the feature engineering process and relies on manual creation of the feature table. dotData released a platform that not only automates feature engineering from source data but also automates machine learning as well. dotData calls it “data science automation”. Its AI-powered feature engineering automatically designs and generates important and interpretable features without domain knowledge. This platform covers a wide range of tasks as it pertains to the data science process and make it easier and faster to build and implement data science projects.
How will Automation Tools Change Data Science?
Will data scientists or domain experts be replaced with automation tools? The answer is obviously no. No tool can truly replace skilled experts. Instead it makes them more productive. Automation will affect data science in three major ways:
- Agility: Traditional data science processes often follow “waterfall” approaches, which involves significant upfront efforts in data cleansing, ETL, and feature engineering because each individual step requires heavily manual and time-consuming efforts. Automation tools make it much easier and faster to try ideas, so data scientists can explore high impact use cases.
- Democratization: There are hundreds of potential analytics use cases in a large enterprise (or maybe even more). Automation tools enable people with different skill sets to execute on data science and they enable seasoned data science teams, which are hard to hire, to focus on high-value-creation use cases.
- Operationalization: As stated at the beginning of this blog, most enterprises have not yet implemented AI and data science. Many enterprise-grade automation tools such as dotData automatically produce APIs or executable packages that can be immediately operationalized in production. This significantly shortens the time and barrier to implement data science in enterprises (the last step of the first illustration above).
As enterprises move to a data-driven culture, data science becomes more critical. Automation tools help accelerating data science and business innovation.
Footnotes:
* There are two types of ETL (including data cleansing) in enterprises. One is “master data ETL” which prepare data for general purposes in the organization. There are many great tools to support this process such as informatica. On the other hand, even if the master data are well prepared, we still need customized ETL work for each analytics use case, which is referred to as “last-mile ETL”.
** Communications of the ACM, Volume 55 Issue 10, October 2012
Bio: Dr. Ryohei Fujimaki is the Founder & CEO of dotData. Prior to founding dotData, he was the youngest research fellow ever in NEC Corporation’s 119-year history, the title was honored for only six individuals among 1000+ researchers. During his tenure at NEC, Ryohei was heavily involved in developing many cutting-edge data science solutions with NEC's global business clients, and was instrumental in the successful delivery of several high-profile analytical solutions that are now widely used in industry.
Resources:
- On-line and web-based: Analytics, Data Mining, Data Science, Machine Learning education
- Software for Analytics, Data Science, Data Mining, and Machine Learning
Related:
- AI, Data Science, Analytics Main Developments in 2018 and Key Trends for 2019
- AI Solutionism
- The 4 Levels of Data Usage in Data Science