The 4 Levels of Data Usage in Data Science
This is an overview of the 4 levels, or "buckets," of data usage in business, starting at monitoring and progressing to automation.
On a recent episode of the O'Reilly Data Show Podcast with Ben Lorica, guest Jerry Overton of DXC Technology discussed, among other things, some of the more non-technical issues which data practitioners must tend with, such as privacy, security, and ethics, as well as the current state of data science in businesses.
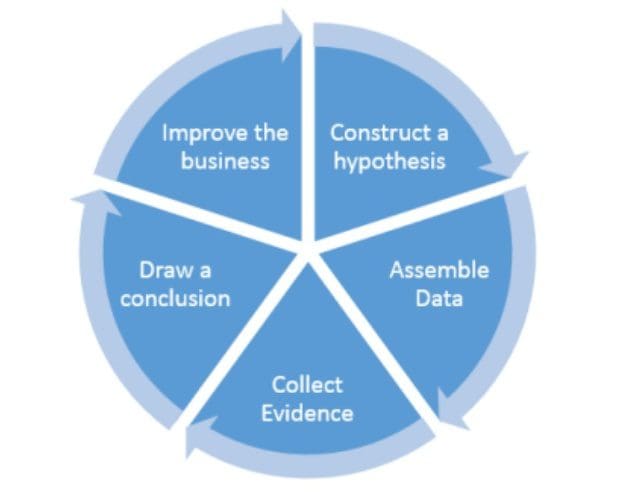
Figure 1: The process of accumulating competitive advantages using data science (Source: Going Pro in Data Science)
Overton noted that 5 years ago the idea of extracting value from data was new to businesses, and that businesses had to be convinced that it was worth their effort to collect data and analyze it for meaningful patterns from which they could benefit. He then contrasted that with the views of today, noted that it is now understood that not using data is losing out on a potential competitive edge. It seems a forgone conclusion that data science is necessary to some degree, yet businesses now have a different set of questions. What should our data scientists be doing? What areas of our business should we be focusing on? How exactly can our data add value?
One topic that Ben and Jerry then discussed were the levels, or "buckets," of data usage in business, where Jerry defined and outlined 4 such categories. The discussion was interesting, and the description of the levels, while intuitive, was useful, in my view. Below I have summarized the basics of these categories, and I would encourage everyone to listen to the entire episode for more solid discussion.
1 - Monitor & Predict
This level entails implementing end-to-end capabilities to see what's going on, and see if something is going to go wrong.
- Monitor the business and predict problems
- Collect information on what's going on
- This information collected is what Overton dubs "digital data exhaust"
- We are able to answer the question "Is there a problem?"
2 - Improve Efficiency
Now that you know that a problem exists, what can be done to minimize the risk associated with that problem?
3 - Augment Decision Making
At this level, we should already know what is going wrong, and should (hopefully) be in a much better position when it comes to predicting when something will go wrong.
- Get this information to the decision makers
- Instead of sitting on data, or using it in a transactional manner, we can leverage insights for business strategy
- This is a step short of automation, however, where the human is still needed as protagonist
4 - Automation
At this level, we hand over control of particular processes to machines, which runs those processes uninterrupted, and without constant human oversight.
- Machines alert humans when they encounter some phenomena with which they cannot cope
- Important to note that such automation occurs incrementally, not all at once
- This is not "full business automation," a la SkyNet
- Allows humans to do more meaningful work, focus on what the business needs humans for
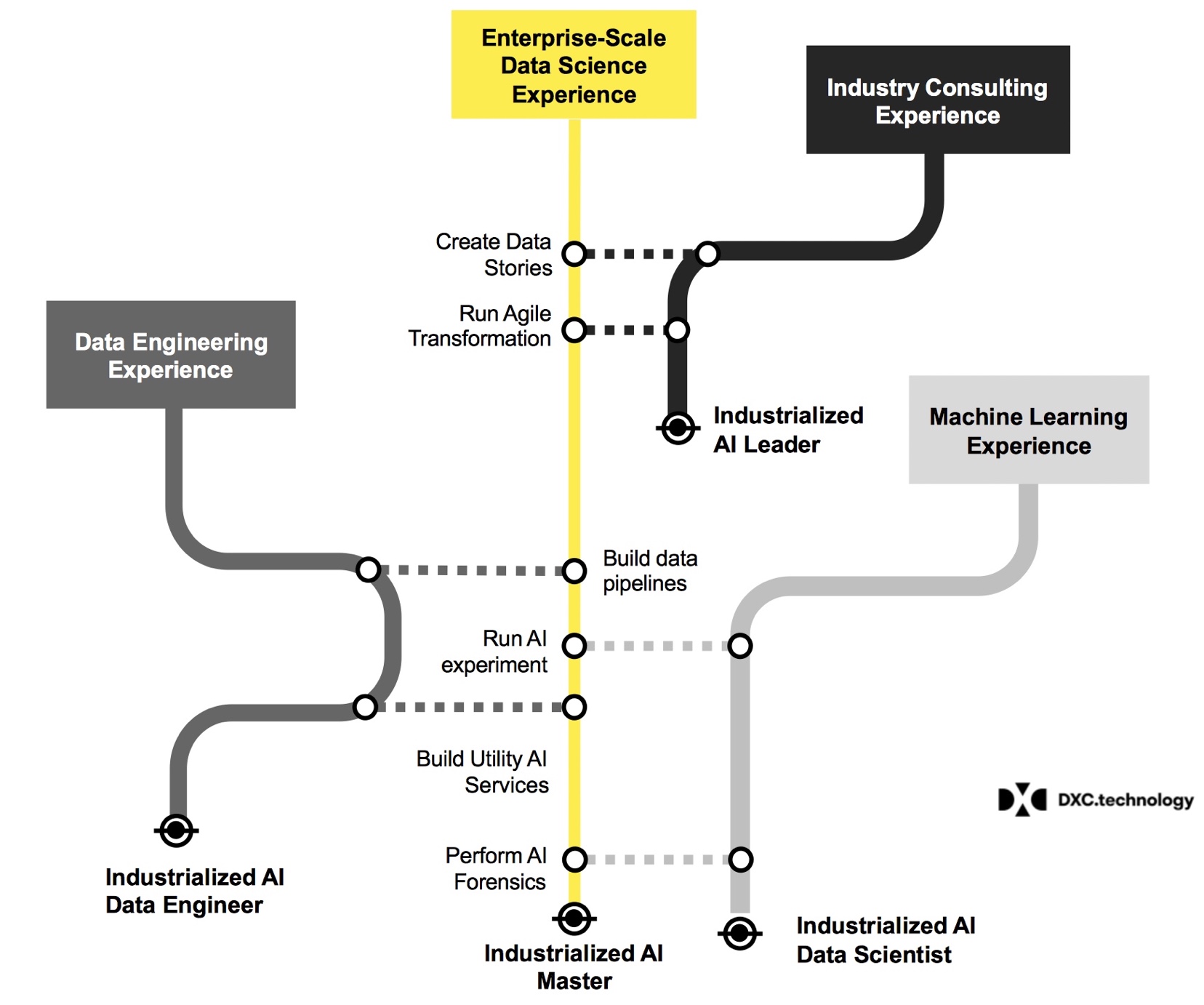
Figure 2: Enterprise data science (Credit: DXC Technology, as seen here)
Related:
- The What, Where and How of Data for Data Science
- Data Science: 4 Reasons Why Most Are Failing to Deliver
- The ways that AI can change your business