Building an image search service from scratch
By the end of this post, you should be able to build a quick semantic search model from scratch, no matter the size of your dataset.
By Emmanuel Ameisen, Head of AI at Insight Data Science

Teaching computers to look at pictures the way we do
Want to learn applied Artificial Intelligence from top professionals in Silicon Valley or New York? Learn more about the Artificial Intelligence program at Insight.
Are you a company working in AI and would like to get involved in the Insight AI Fellows Program? Feel free to get in touch.
For more content like this, follow Insight and Emmanuel on Twitter.
Why similarity search?
An image is worth a thousand words, and even more lines of code.
Many products fundamentally appeal to our perception. When browsing through outfits on clothing sites, looking for a vacation rental on Airbnb, or choosing a pet to adopt, the way something looks is often an important factor in our decision. The way we perceive things is a strong predictor of what kind of items we will like, and therefore a valuable quality to measure.
However, making computers understand images the way humans do has been a computer science challenge for quite some time. Since 2012, Deep Learning has slowly started overtaking classical methods such as Histograms of Oriented Gradients (HOG) in perception tasks like image classification or object detection. One of the main reasons often credited for this shift is deep learning’s ability to automatically extract meaningful representations when trained on a large enough dataset.
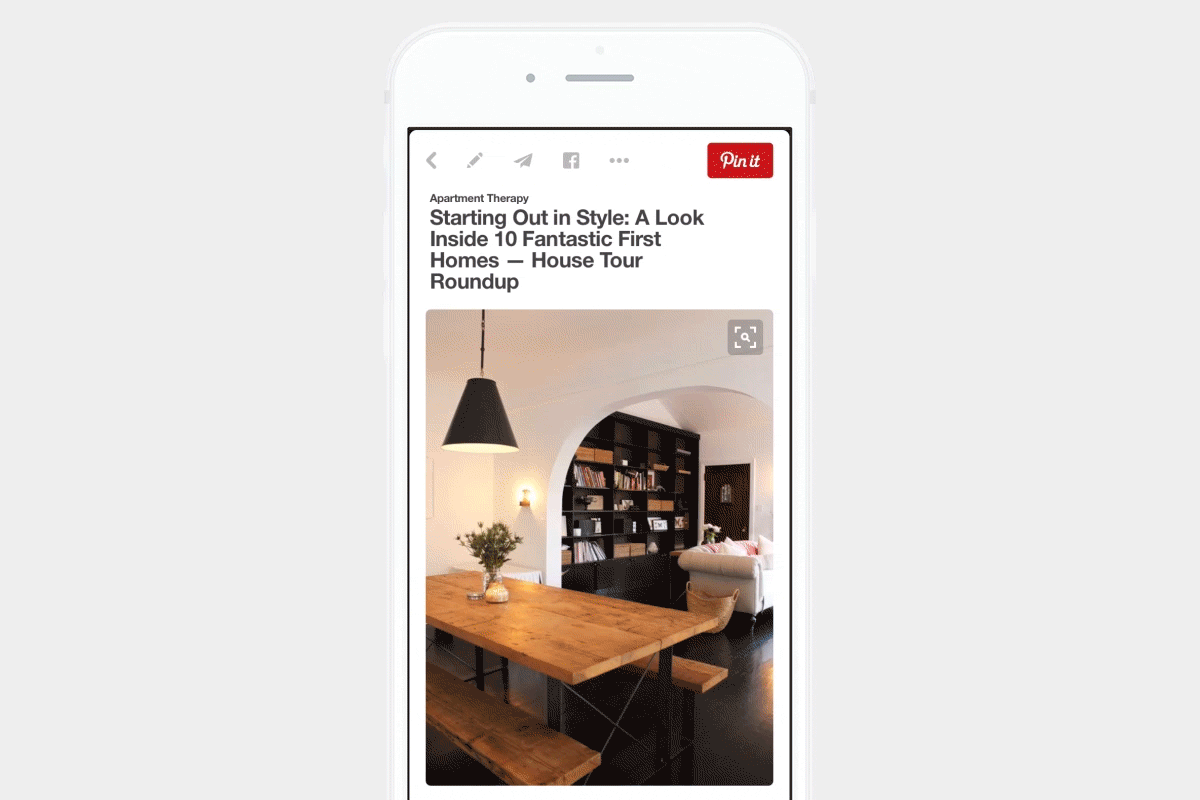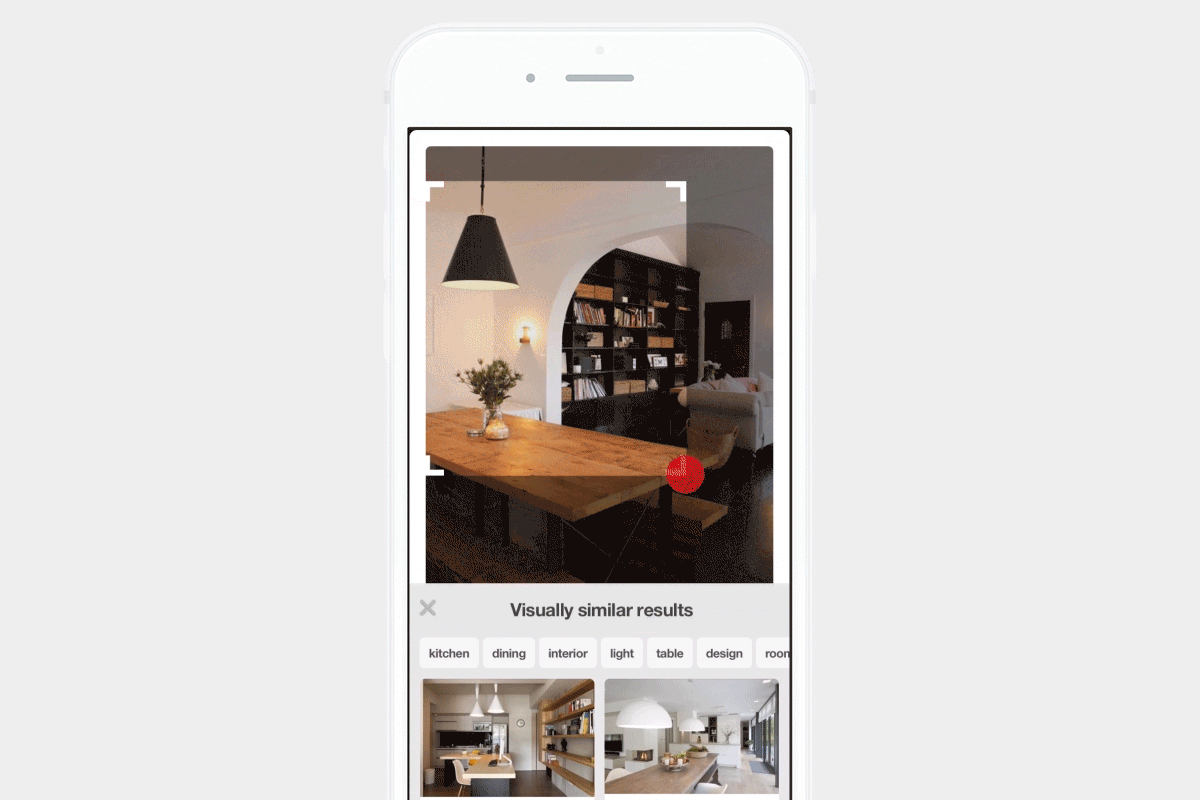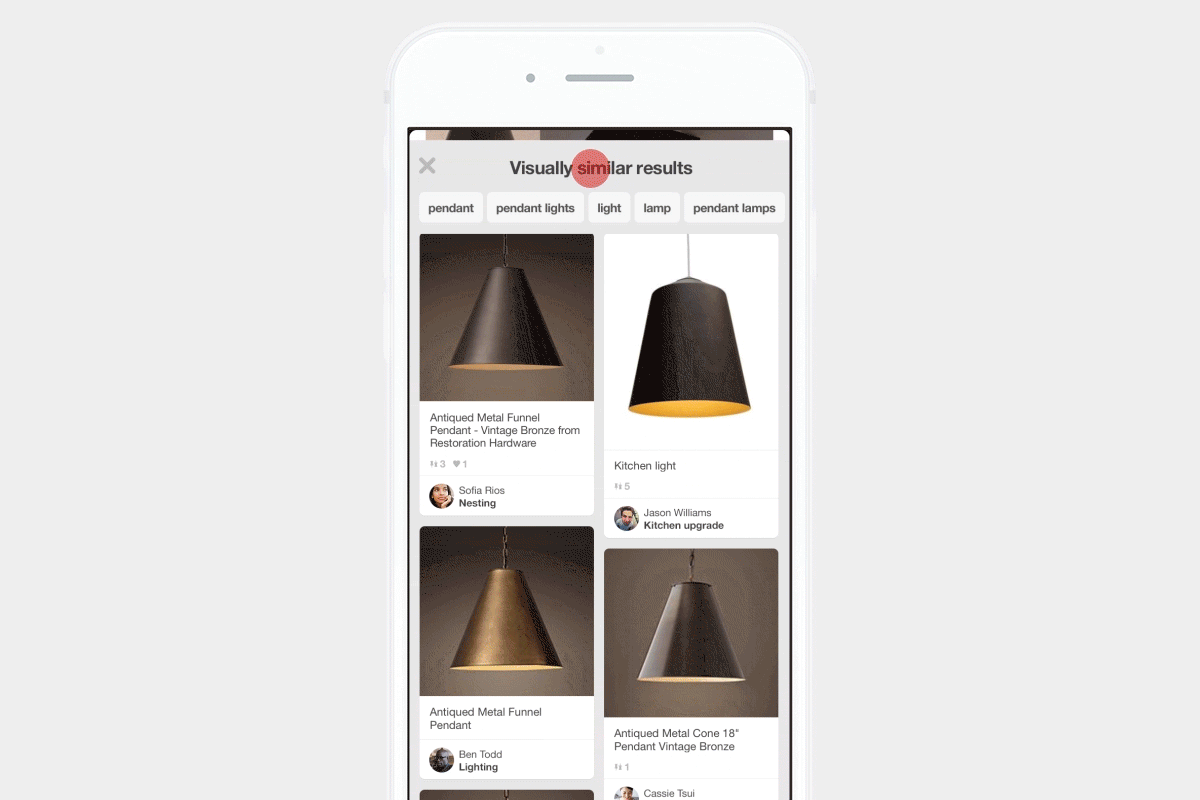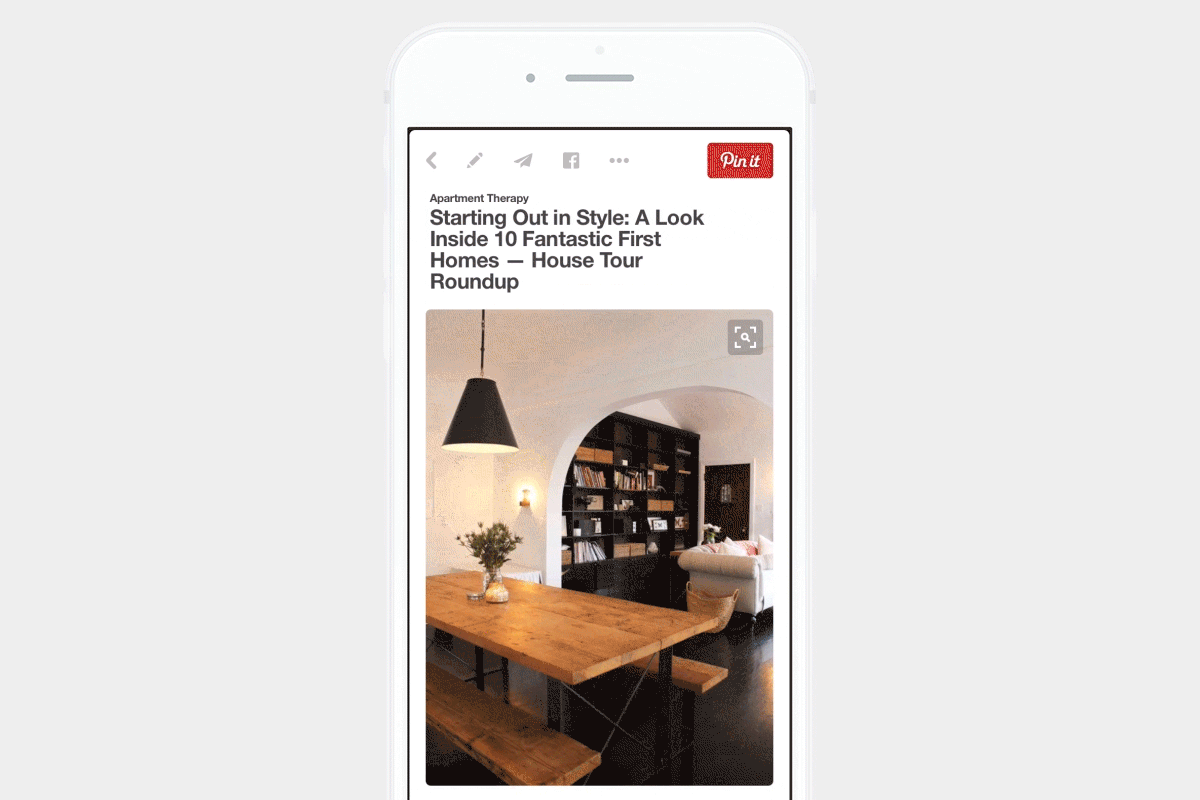
Visual search at Pinterest
This is why many teams — like at Pinterest, StitchFix, and Flickr — started using Deep Learning to learn representations of their images, and provide recommendations based on the content users find visually pleasing. Similarly, Fellows at Insight have used deep learning to build models for applications such as helping people find cats to adopt, recommending sunglasses to buy, and searching for art styles.
Many recommendation systems are based on collaborative filtering: leveraging user correlations to make recommendations (“users that liked the items you have liked have also liked…”). However, these models require a significant amount of data to be accurate, and struggle to handle new itemsthat have not yet been viewed by anyone. Item representation can be used in what’s called content-based recommendation systems, which do not suffer from the problem above.
In addition, these representations allow consumers to efficiently search photo libraries for images that are similar to the selfie they just took (querying by image), or for photos of particular items such as cars (querying by text). Common examples of this include Google Reverse Image Search, as well as Google Image Search.
Based on our experience providing technical mentorship for many semantic understanding projects, we wanted to write a tutorial on how you would go about building your own representations, both for image and text data, and efficiently do similarity search. By the end of this post, you should be able to build a quick semantic search model from scratch, no matter the size of your dataset.
This post is accompanied by an annotated code notebook using streamlit and a self-standing codebase demonstrating and applying all these techniques. Feel free to run the code and follow along!
What’s our plan?
A break to chat about optimization
In machine learning, just like in software engineering, there are many ways to tackle a problem, each with different tradeoffs. If we are doing research or local prototyping, we can get away with very inefficient solutions. But if we are building an image similarity search engine that needs to be maintainable and scalable, we have to consider both how we can adapt to data evolution, and how fast our model can run.
Let’s imagine a few approaches:
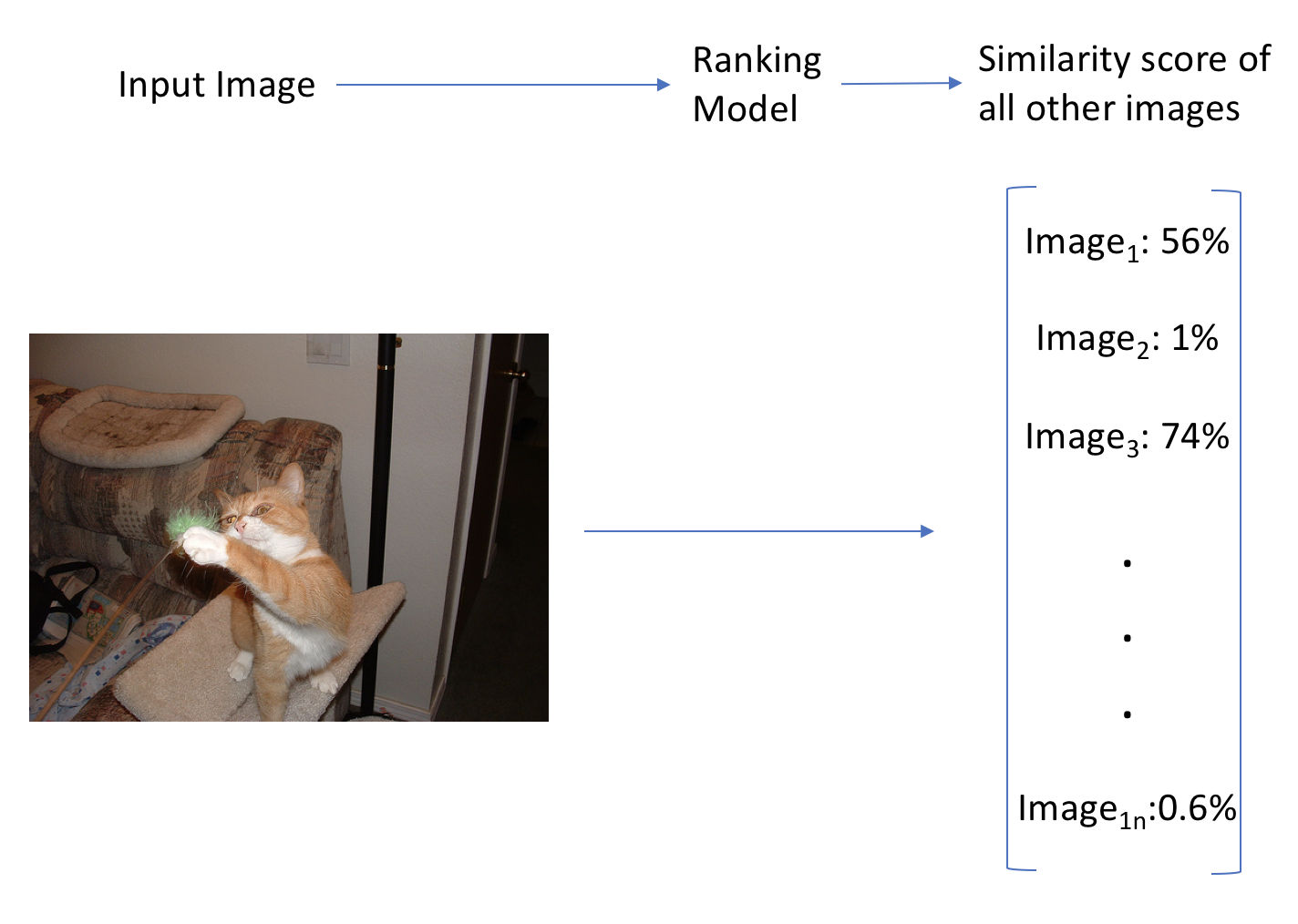
Workflow for approach 1
1/ We build an end-to-end model that is trained on all our images to take an image as an input, and output a similarity score over all of our images. Predictions happen quickly (one forward pass), but we would need to train a new model every time we add a new image. We would also quickly reach a state with so many classes that it would be extremely hard to optimize it correctly. This approach is fast, but does not scale to large datasets. In addition, we would have to label our dataset by hand with image similarities, which could be extremely time consuming.
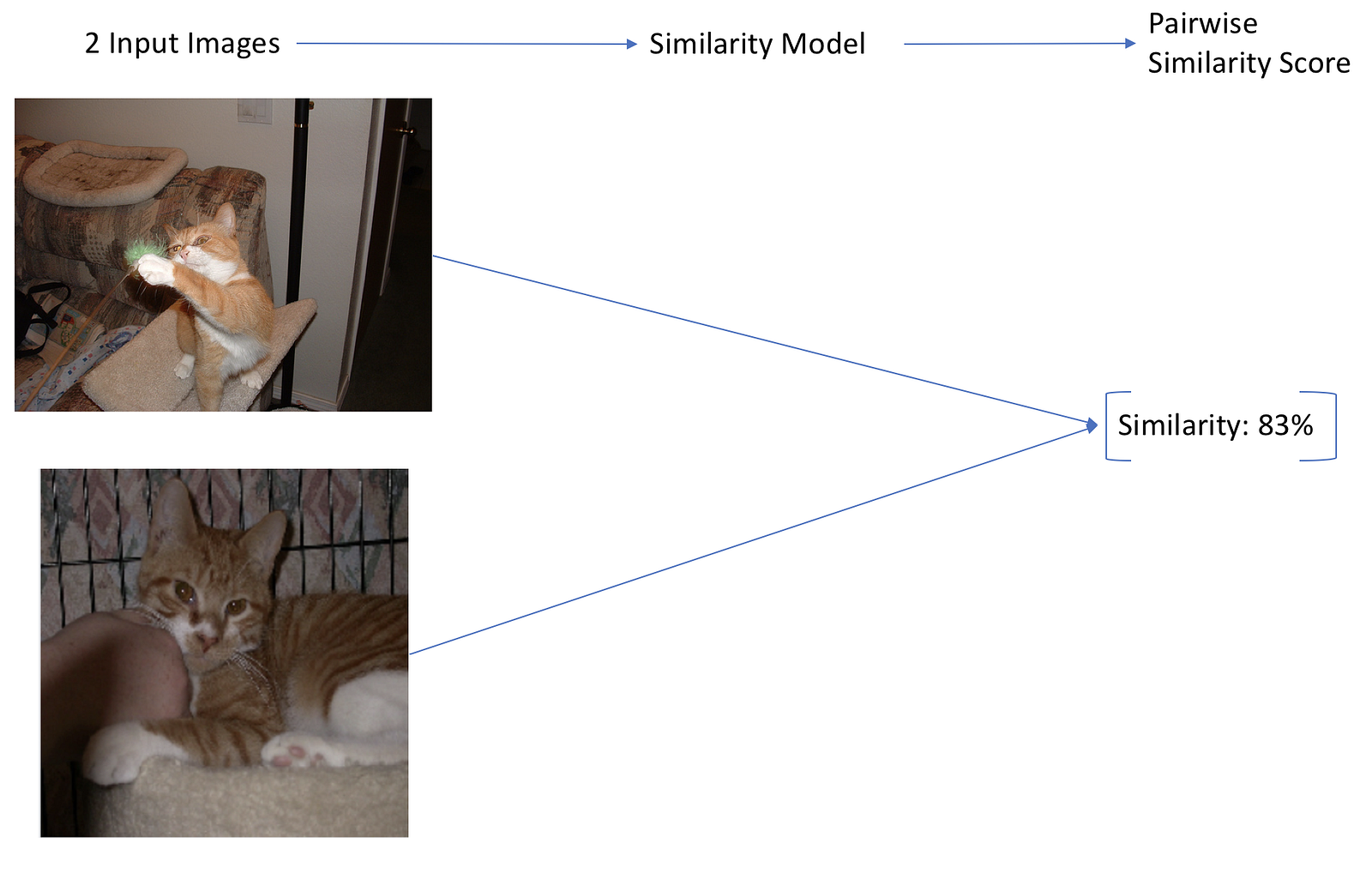
Workflow for approach 2
2/ Another approach is to build a model that takes in two images, and outputs a pairwise similarity score between 0 and 1 (Siamese Networks[PDF], for example). These models are accurate for large datasets, but lead to another scalability issue. We usually want to find a similar image by looking through a vast collection of images, so we have to run our similarity model once for each image pair in our dataset. If our model is a CNN, and we have more than a dozen images, this becomes too slow to even be considered. In addition, this only works for image similarity, not text search. This method scales to large datasets, but is slow.
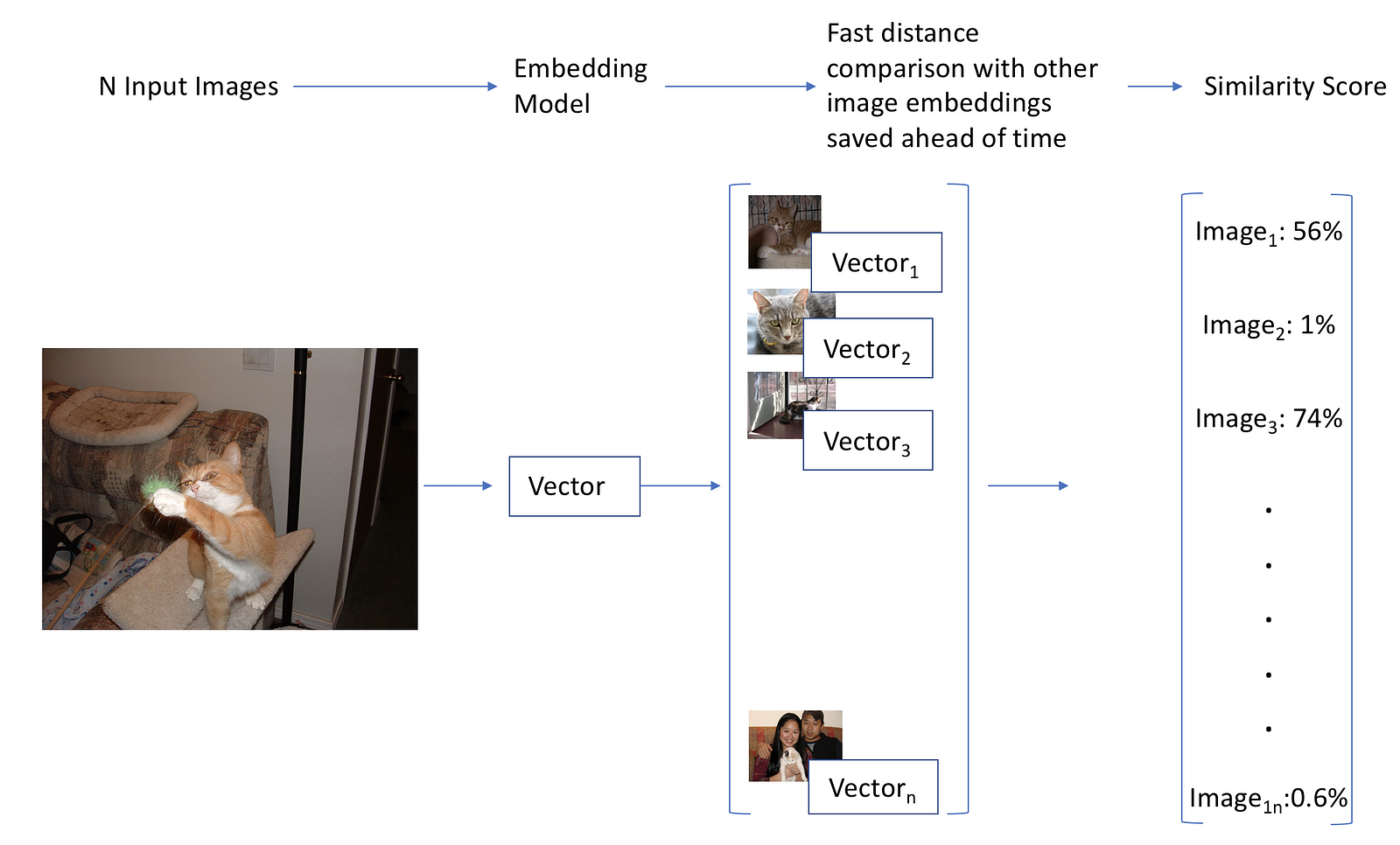
Workflow for approach 3
3/ There is a simpler method, which is similar to word embeddings. If we find an expressive vector representation, or embedding for images, we can then calculate their similarity by looking at how close their vectors are to each other. This type of search is a common problem that is well studied, and many libraries implement fast solutions (we will use Annoy here). In addition, if we calculate these vectors for all images in our database ahead of time, this approach is both fast (one forward pass, and an efficient similarity search), and scalable. Finally, if we manage to find common embeddings for our images and our words, we could use them to do text to image search!
Because of its simplicity and efficiency, the third method will be the focus of this post.
How do we get there?
So, how do we actually use deep learning representations to create a search engine?
Our final goal is to have a search engine that can take in images and output either similar images or tags, and take in text and output similar words, or images. To get there, we will go through three successive steps:
- Searching for similar images to an input image (Image → Image)
- Searching for similar words to an input word (Text → Text)
- Generating tags for images, and searching images using text (Image ↔ Text)
To do this, we will use embeddings, vector representations of images and text. Once we have embeddings, searching simply becomes a matter of finding vectors close to our input vector.
The way we find these is by calculating the cosine similarity between our image embedding, and embeddings for other images. Similar images will have similar embeddings, meaning a high cosine similarity between embeddings.
Let’s start with a dataset to experiment with.
Dataset
Images
Our image dataset consists of a total of a 1000 images, divided in 20 classes with 50 images for each. This dataset can be found here. Feel free to use the script in the linked code to automatically download all image files. Credit to Cyrus Rashtchian, Peter Young, Micah Hodosh, and Julia Hockenmaier for the dataset.
This dataset contains a category and a set of captions for every image. To make this problem harder, and to show how well our approach generalizes, we will only use the categories, and disregard the captions. We have a total of 20 classes, which I’ve listed out below:
aeroplane bicycle bird boat bottle bus car cat chair cow dining_table dog horse motorbike person potted_plant sheep sofa train tv_monitor

Image examples. As we can see, the labels are quite noisy.
We can see our labels are pretty noisy: many photos contain multiple categories, and the label is not always from the most prominent one. For example, on the bottom right, the image is labeled chair and not personeven though 3 people stand in the center of the image, and the chair is barely visible.
Text
In addition, we load word embeddings that have been pre-trained on Wikipedia (this tutorial will use the ones from the GloVe model). We will use these vectors to incorporate text to our semantic search. For more information on how these word vectors work, see Step 7 of our NLP tutorial.
Image -> Image
Starting simple
We are now going to load a model that was pre-trained on a large data set (Imagenet), and is freely available online. We use VGG16 here, but this approach would work with any recent CNN architecture. We use this model to generate embeddings for our images.

VGG16 (credit to Data Wow Blog)
What do we mean by generating embeddings? We will use our pre-trained model up to the penultimate layer, and store the value of the activations. In the image below, this is represented by the embedding layer highlighted in green, which is before the final classification layer.
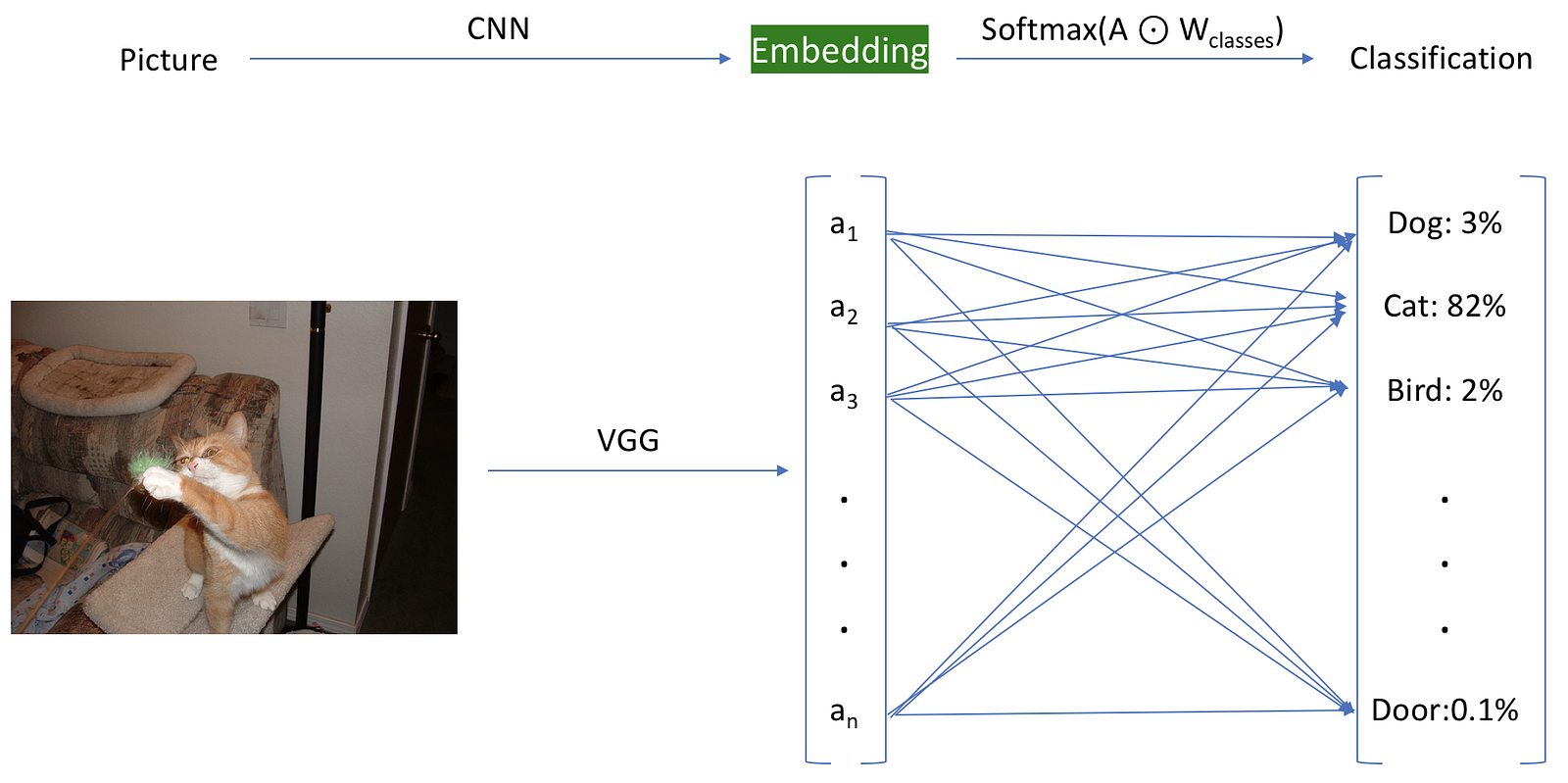
For our embeddings, we use the layer before the final classification layer.
Once we’ve used the model to generate image features, we can then store them to disk and re-use them without needing to do inference again! This is one of the reasons that embeddings are so popular in practical applications, as they allow for huge efficiency gains. On top of storing them to disk, we will build a fast index of the embeddings using Annoy, which will allow us to very quickly find the nearest embeddings to any given embedding.
Below are our embeddings. Each image is now represented by a sparse vector of size 4096. Note: the reason the vector is sparse is that we have taken the values after the activation function, which zeros out negatives.
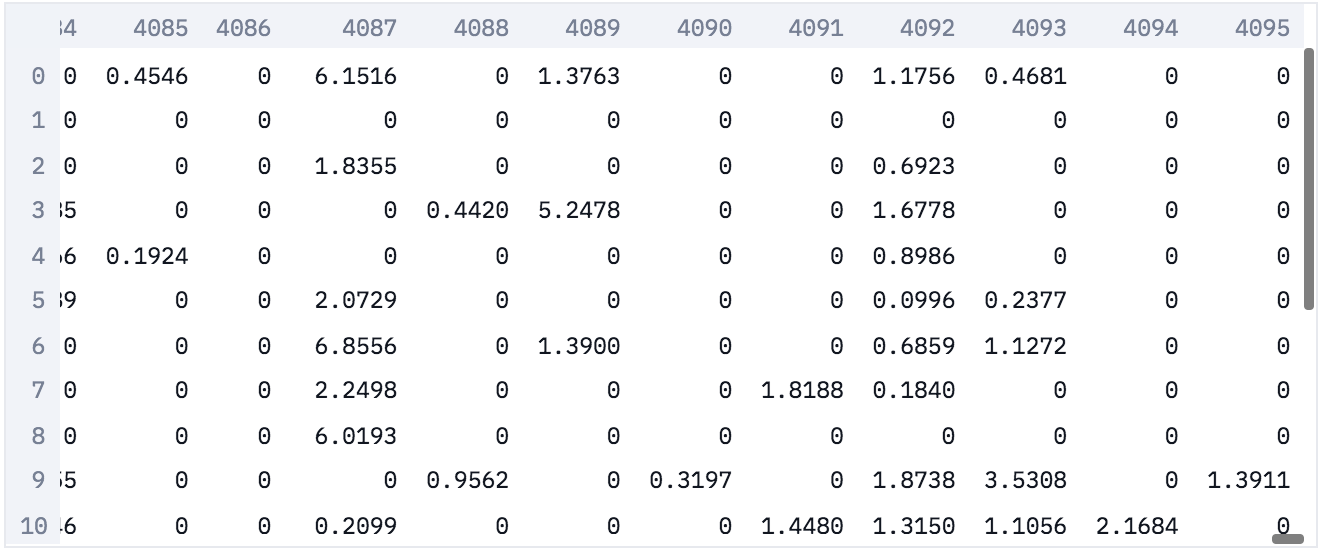
Image Embeddings
Using our embeddings to search through images
We can now simply take in an image, get its embedding, and look in our fast index to find similar embeddings, and thus similar images.
This is especially useful since image labels are often noisy, and there is more to an image than its label.
For example, in our dataset, we have both a class cat, and a class bottle.
Which class do you think this image is labeled as?

Cat or Bottle? (Image rescaled to 224x224, which is what the neural network sees.)
The correct answer is bottle … This is an actual issue that comes up often in real datasets. Labeling images as unique categories is quite limiting, which is why we hope to use more nuanced representations. Luckily, this is exactly what deep learning is good at!
Let’s see if our image search using embeddings does better than human labels.
Searching for similar images todataset/bottle/2008_000112.jpg…

Great — we mostly get more images of cats, which seems very reasonable! Our pre-trained network has been trained on a wide variety of images, including cats, and so it is able to accurately find similar images, even though it has never been trained on this particular dataset before.
However, one image in the middle of the bottom row shows a shelf of bottles. This approach perform wells to find similar images, in general, but sometimes we are only interested in part of the image.
For example, given an image of a cat and a bottle, we might be only interested in similar cats, not similar bottles.
Semi-supervised search
A common approach to solve this issue is to use an object detection model first, detect our cat, and do image search on a cropped version of the original image.
This adds a huge computing overhead, which we would like to avoid if possible.
There is a simpler “hacky” approach, which consists of re-weighing the activations. We do this by loading the last layer of weights we had initially discarded, and only use the weights tied to the index of the class we are looking for to re-weigh our embedding. This cool trick was initially brought to my attention by Insight Fellow Daweon Ryu. For example, in the image below, we use the weights of the Siamese cat class to re-weigh the activations on our dataset (highlighted in green). Feel free to check out the attached notebook to see the implementation details.
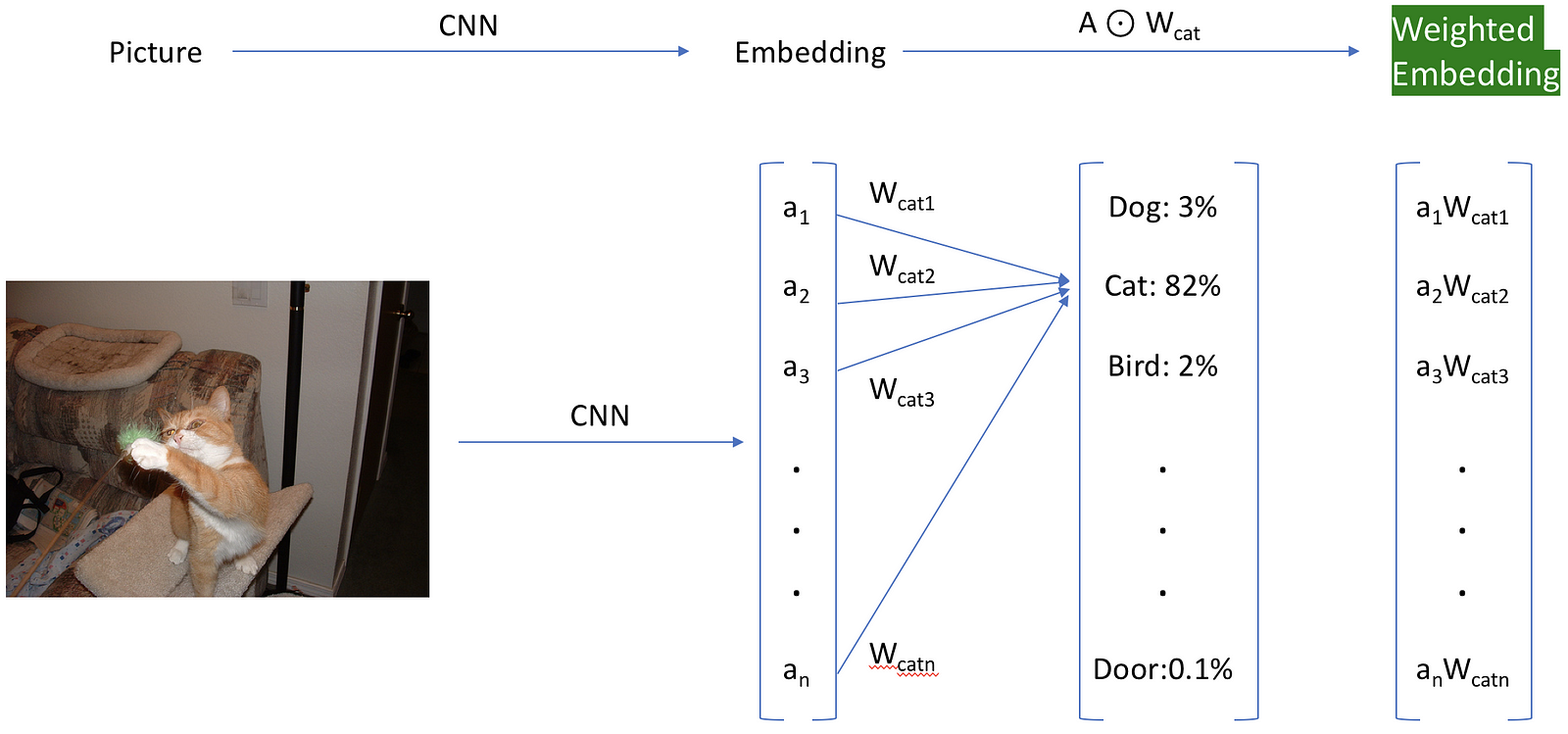
The hack to get weighted embeddings. The classification layer is shown for reference only.
Let’s examine how this works by weighing our activations according to class 284 in Imagenet, Siamese cat.
Searching for similar images todataset/bottle/2008_000112.jpg using weighted features…

We can see that the search has been biased to look for Siamese cat-like things. We no longer show any bottles, which is great. You might however notice that our last image is of a sheep! This is very interesting, as biasing our model has led to a different kind of error, which is more appropriate for our current domain.
We have seen we can search for similar images in a broad way, or by conditioning on a particular class our model was trained on.
This is a great step forward, but since we are using a model pre-trained on Imagenet, we are thus limited to the 1000 Imagenet classes. These classes are far from all-encompassing (they lack a category for people, for example), so we would ideally like to find something more flexible. In addition, what if we simply wanted to search for cats without providing an input image?
In order to do this, we are going to use more than simple tricks, and leverage a model that can understand the semantic power of words.