Are BERT Features InterBERTible?
This is a short analysis of the interpretability of BERT contextual word representations. Does BERT learn a semantic vector representation like Word2Vec?
By Davis Liang, Scientist at Amazon AI
From BOW to BERT
We’ve come a long way in the word embedding space since the introduction of Word2Vec (Mikolov et. al) in 2013. These days, it seems that every single machine learning practitioner can recite the “king minus man plus woman equals queen” mantra. In present, these interpretable word embeddings have become an essential part in many deep-learning based NLP systems.
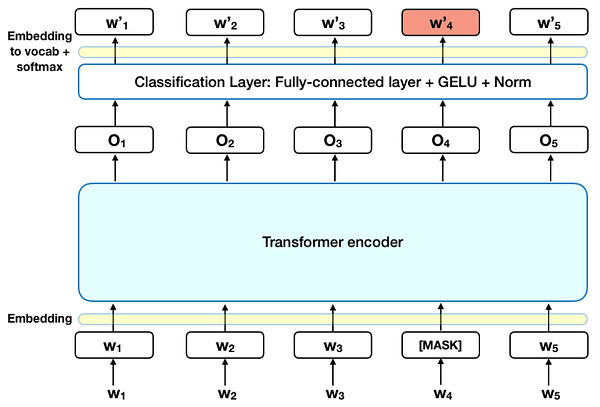
Earlier last October, Google AI introduced BERT: Bidirectional Encoder Representations from Transformers (paper, source). Seemingly, the researchers at Google have done it again: they’ve come up with a model to learn contextual word representations that redefined the state of the art for 11 NLP tasks, ‘even surpassing human performance in the challenging area of question answering’. But a question remained: what exactly do these contextual word representations encode? Are they as interpretable as the word embeddings from Word2Vec?
In this post, we’ll begin to explore just this: the interpretability of these fixed BERT representations. We find that we don’t need to go too deep in order to start seeing interesting results.
Analyzing BERT Representations
Context-Free Approach
Let’s begin with a simple case, devoid of any context. Here, we ignore the fact that we are evaluating BERT off its original domain of being trained on a contiguous span of tokens. For this, and the rest of our experiments, we’ll
- Extract the representation of the target words.
- Compute the cosine distance between words.
Extracting the vectors for “man”, “woman”, “king”, and “queen” we find that king actually moves further from queen once we apply the classic reconstruction (king minus man plus woman).
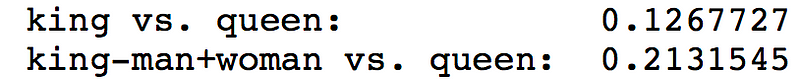
But perhaps we’re evaluating this model off-domain. BERT was originally trained to perform tasks such as Masked-LM and Next-Sentence-Prediction. In other words BERT weights are learned such that context is used in building the representation of the word, not just as a loss function to help learn a context-independent representation.
Contextual Approach
To mitigate this off-domain effect, we can construct sentences that use our words in their appropriate contexts such as “the king passed a law”, “the queen passed a law”, and “the refrigerator was cold”. Under these new conditions, we begin exploring
- How representations of a particular word changes as it is used in different contexts (e.g. as the subject vs. the object, conditioned against different descriptive adjectives, and against the context-free word itself).
- If the semantic vector space hypothesis holds up when we extract representations from the proper context.
We begin with a simple experiment with the word “refrigerator”. We generate 5 sentences:
- refrigerator (using refrigerator without any context)
- the refrigerator is in the kitchen (using refrigerator as the subject of the sentence)
- the refrigerator is cold (again using refrigerator as the subject of the sentence)
- he kept the food inside the refrigerator (using refrigerator as an object against the preposition ‘inside’)
- the refrigerator passed a law (using refrigerator in a non-admissable context)
Here, we confirm our previous hypothesis and find that using refrigerator without any context returns a representation that is very different from using refrigerator inside a proper context. Additionally, using refrigerator as the subject of a sentence that admits it (sentence 2, 3) returns representations that are much more similar than against sentences that use refrigerator as an object (sentence 4), and in non-admissable contexts (sentence 5).

Let’s take a look at another example, this time using the word pie. We generate the 5 sentences:
- pie (using pie without any context)
- the man ate a pie (using pie as the object)
- the man threw a pie (using pie as the object)
- the pie was delicious (using pie as the subject)
- the pie ate a man (using pie in a non-admissable context)
We observe a trend that’s very similar to what we saw in our previous refrigerator example.

Next, let’s take a look at our original example with the words king, queen, man, and woman. We construct 4 nearly identical sentences, swapping out their subjects.
- the king passed a law
- the queen passed a law
- the man passed a law
- the woman passed a law
From these sentences, we extract the BERT representation of the subject. In this case, we get a better result: subtracting man from king and adding woman shifts us very slightly closer towards queen.

Finally, we explore how word representations change when the structure of the sentence is fixed but the sentiment is not. Here, we construct 3 sentences:
- math is a difficult subject
- math is a hard subject
- math is a simple subject
Using these sentences, we would like to probe what happens to the subject and adjective representations as we vary the sentiment. Interestingly enough, we find that the adjective that are synonymous (i.e. difficult and hard) have similar representations but the adjectives that are antonymous (i.e. difficultand simple) have very different representations.
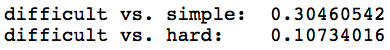
Additionally, as we vary the sentiment, we find that the subject, math, is more similar when the contexts have the same sentiment (i.e. difficult and hard) than if the contexts have different sentiments (i.e. difficult and simple).
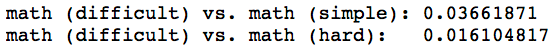
Conclusion
In conclusion, the results seem to signal that, that like Word2Vec, BERT may also learn a semantic vector representation (albeit much less pronounced). It also seems that BERT really does rely heavily on contextual information: words without any context are very different than the same word with some context and shifting contexts (like changing sentiments) also shift subject representation.
Keep in mind that there is always the danger of overgeneralizing with limited evidence. These experiments are not complete and this is just the beginning. We use a very small sample size (out of the vast lexicon of english words), while evaluating on a very specific distance metric (cosine distance), on a very ad-hoc set of experiments. Future work on analyzing BERT representations should expand on all of these aspects. Finally, thanks to John Hewitt and Zack Lipton for providing useful discussion on the subject.
Bio: Davis Liang is a Scientist at Amazon AI. His interests fall into the intersection of computer vision, natural language processing, speech recognition, cognitive neuroscience, and reinforcement learning under the domain of generalizable & robust neural architectures. At night and on the weekends, he is a visual artist. His musings about machine learning at The Local Minima (medium.com/thelocalminima).
Original. Reposted with permission.
Related:
- 10 Exciting Ideas of 2018 in NLP
- ELMo: Contextual Language Embedding
- Human Interpretable Machine Learning (Part 1) — The Need and Importance of Model Interpretation