OpenAI’s GPT-2: the model, the hype, and the controversy
OpenAI recently released a very large language model called GPT-2. Controversially, they decided not to release the data or the parameters of their biggest model, citing concerns about potential abuse. Read this researcher's take on the issue.
By Ryan Lowe, McGill University
Last Thursday, OpenAI [recently] released a very large language model called GPT-2. This model can generate realistic text in a variety of styles, from news articles to fan fiction, based off some seed text. Controversially, they decided not to release the data or the parameters of their biggest model, citing concerns about potential abuse. It’s been a pretty big deal.
I decided to start a blog just so I could write about this, as I haven’t seen a post that says all the things I want to say. I think there’s a really crucial takeaway for the machine learning community around dealing with potential misuses of machine learning research. I also talk about the technical merits of the research, the social implications of human-level language generation, and the accusations that OpenAI is motivated by hype-generation.
(Disclaimer: I interned at OpenAI from February to August 2017, and know some of the people involved in this research. Opinions stated here are my own.)
Is the research any good?
I used to work on neural network-based dialogue systems, which are trained to predict the next response given previous responses in a dialogue. I remember going through our model’s generated samples, in late 2016, trying to find a single sentence that sounded plausible given the context of the conversation.
So I was pretty shocked when I read GPT-2’s story about English-speaking unicorns (if you haven’t read it, I highly recommend it). The story isn’t perfect, and has some wobbles in the middle, but on the whole it’s remarkably coherent. It actually sounds like a news article that a human could have written. To me, that’s an incredible result regardless of the amount of cherry-picking. I would have been moderately impressed with a language model that correctly recalled Jorge Perez’s name throughout the document without an explicit memory mechanism. This is something else entirely. I might be slightly out-of-date with the recent language generation literature, but I’m not aware of any model that comes close to this level of coherence, grammaticality, use of long-term context, and world knowledge.
To be clear: there is no algorithmic contribution here. They are “just scaling up” previous research. But I think seeing exactly how strong these scaled up models are is an important contribution in its own right. It’s easy to say in retrospect “of course more data and compute gives you better models”, but if I had shown the unicorn story to a colleague last Wednesday and told them that it was AI-generated, I don’t think they would have believed me.
Some have wondered if the model may simply be memorizing ‘templates’ of text and repeating them at the correct time. This concern is discussed in the paper (Appendix 8.2), where the authors show that the word overlap between GPT-2’s samples and their training set is less than the overlap between the test set and the training set. In other words, GPT-2 shows less memorization behaviour than a randomly selected portion of human text. This seems like fairly convincing evidence that the model has non-trivial generalization capability.
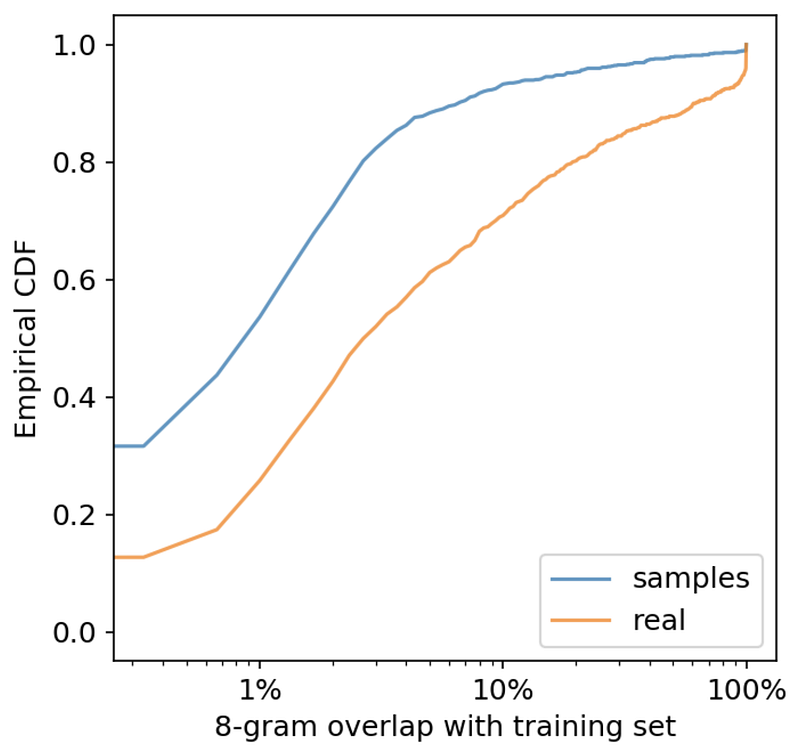
Should we be skeptical of their results? There is a legitimate question about whether OpenAI is accurately presenting the generation capabilities of their model. I personally would like to see the number of inputs they fed into GPT-2 to get the displayed samples (i.e. the degree of what they call ‘meta-cherry picking’). They do, however, provide a dump of hundreds of raw GPT-2 samples, which gives us a clearer picture of their model’s abilities. They also state, for each cherry-picked piece of high-quality GPT-2 writing, how many samples it took to achieve it, which I haven’t seen too often in other papers (including my own). Along with the code release, to me OpenAI’s approach here meets the standard of other published NLP papers.
The social impact of human-quality fake text
Now to the controversy. OpenAI decided not to release the weights of its largest GPT-2 model, with the stated concern of “large language models being used to generate deceptive, biased, or abusive language at scale.” Let’s put aside for now the question of whether GPT-2 can do this, and first ask: if we had an open-source model that could generate unlimited human-quality text with a specific message or theme, could that be bad?
I think the answer is yes. It’s true that humans can already write fake news articles, and that governments already recruit thousands of people to write biased comments tailored towards their agenda. But an automated system could: (1) enable bad actors, who don’t have the resources to hire thousands of people, to wage large-scale disinformation campaigns; and (2) drastically increase the scale of the disinformation campaigns already being run by state actors. These campaigns work because humans are heavily influenced by the number of people around them who share a certain viewpoint, even if the viewpoint doesn’t make sense. Increasing the scale should correspondingly increase the influence that governments and companies have over what we believe.
To combat this, we’ll need to start to researching detection methods for AI-generated text. This will present different challenges compared to fake video and speech detection: while only a single high-quality fake video is required to influence people’s opinion, videos are very high-dimensional and it’s likely easier to detect ‘artifacts’ produced by ML models. On the other hand, AI-generated fake text has to be done at a large scale to have an impact (otherwise a human could do it), but since text consists of discrete words it may be harder to tell if a particular piece of text is AI-generated, especially if it’s short.
So, there are legitimate arguments that widely releasing a perfect human-level text generator, without thinking about the implications, could be a bad idea.
AI hype, and OpenAI’s motivations
There’s another reason many are postulating for why OpenAI withheld their model parameters — to add hype value to their research. The theory is that OpenAI, knowing that news outlets would cover the research more if they could spin an ‘AI is dangerous’ narrative, withheld their model so that sensationalist news stories would be written about them, thereby increase the public’s recognition of OpenAI, and further cementing the perceived value of OpenAI’s AI safety work.
OpenAI hasn’t written about their approach to interacting with journalists, but there are some blanks we can fill in. Like other industrial labs, OpenAI clearly cares about public perception and recognition. They are also explicitly soliciting journalists to write stories about their research (otherwise they wouldn’t have provided GPT-2 access to them). On top of that, since OpenAI is a non-profit, they gain an even greater advantage to having their research publicized, as it likely increases donations and thus their budget for doing more research. It’s hard to know how much control OpenAI has over the news that’s written about them, but some of the headlines and articles about GPT-2 are quite apocalyptic.
So how do we know that OpenAI’s primary motivation isn’t to gain more influence and money? The short answer is: we don’t. We have to take OpenAI at their word that they actually care about the social impact of their research. For me, that’s not particularly hard to believe given that I know many of these people personally.
But many researchers seem reluctant to assign positive intentions: they perceive OpenAI as either a ‘holier-than-thou’ outfit who thinks they will save the world, or a group misguided by the notion of an ‘AI singularity’ and bent on fear-mongering, or a puppet of Elon Musk’s ego designed to maximize news coverage, or some combination thereof. The word ‘Open’ in their name, combined with their outsized media attention and connection to Elon, seems to brew a particular kind of hatred which has spilled out onto Twitter and Reddit in response to the GPT-2 announcement.
These criticisms are worthy of debate and contain grains of truth (except that, to my knowledge, Elon is no longer on OpenAI’s board and hasn’t influenced their decisions for a while). The distortion of AI research in the media is a real problem, as is the undue attention received by industrial labs due to media hype, which short-changes researchers elsewhere. There is an important discussion to be had about the role of big-lab PR in influencing the public perception of AI.
But I urge onlookers to put aside their judgements of OpenAI for a moment (you can resume them later), and to think about what’s really going on here. As ML researchers, we are building things that affect people. Sooner or later, we’ll cross a line where our research can be used maliciously to do bad things. Should we just wait until that happens to decide how we handle research that can have negative side effects?
I’m particularly disappointed by the dismissively sarcastic responses by prominent figures in the machine learning community. I won’t discuss this in detail, but I think it normalizes a dismissive attitude towards the social impact of ML in general. If you’re new to the field and you see a cool famous researcher make a joke about those nerds who are not releasing their silly ML model, you’re likely to absorb these judgements without thinking critically about them (at least, I was easily influenced by famous AI researchers as a Master’s student). I don’t think this is very helpful.
One researcher remarked on Twitter that DeepMind could have done something similar with the release of WaveNet, a model which generates very high-quality human speech, and they were more socially responsible for *not* having done so (they did not mention the ethical implications at all in their initial release). It’s true that there’s nothing special or magical about the research at OpenAI — other labs have done research where a case could have been made to withhold it. Some industrial labs do have fairness teams that review research before release, but we as a field have no idea what norms they are using or standards they are enforcing. OpenAI seems to be the only industrial lab publicly considering the ethical implications of their machine learning research. Even if they are primarily motivated by greed or driving hype, I think the issues they are raising deserve to be taken seriously.
Moving forward: starting the conversation about social impact
Did the GPT-2 model actually warrant this level of caution? It’s hard to say. Decisions like this raise a lot of questions: How long is this really delaying bad actors from reproducing this result? What is the tradeoff with reproducibility? Where is the line between research that is harmless and research that is dangerous? How can we responsibly engage with journalists to have these developments covered accurately? In this case, is GPT-2 benign enough that it should have been released fully? Should OpenAI have provided limited access to researchers to ensure reproducibility? Or maybe they shouldn’t have released the paper at all? OpenAI seems willing to engage in a discussion about these issues (they give an email at the bottom of their blog post asking for feedback), but that doesn’t go far enough: these discussions should be had in the open, not via email exchange.
This is the most important takeaway: the machine learning community really, really needs to start talking openly about our standards for ethical research release. We need a venue that is not Twitter. One possibility is a workshop, maybe co-located with a major ML conference like ICLR, ICML or NeurIPS, where we can brainstorm about what norms we’d like to adopt as a field. I can imagine a kind of ‘safety checklist’ (similarly to the recent ‘reproducibility checklist’) that researchers would be encouraged to follow before releasing their work. Like the fields of biotechnology and cybersecurity, we’re getting to the point where a small subset of ML papers have the potential to be misused. That should be enough for us to start doing something about it.
There are machine learning researchers who are reading this thinking: “This whole situation is ridiculous, AI doesn’t really work anyway. Let me get back to training my models.” And this is part of the problem: from the inside, it often feels like progress is incremental and nothing works like it’s supposed to (especially RL). But ML research is already having an impact in the real world (e.g. to make decisions on loan applications, court sentencing, personnel hiring, etc.). The biases in these algorithms are now being exposed, but this is coming years after they were first implemented, and in the meantime they have made a serious impact on people’s lives.
As our systems become more competent (and they will, eventually), we’ll be able to do increasingly awesome things, and hopefully change the world for the better. But the potential for misuse will also grow significantly. If the majority of ML researchers don’t consider the societal implications of their work before they release it, those who do care will constantly be playing catch-up. If we want to minimize the harm that machine learning will cause in the world, that simply isn’t good enough.
Thanks to Alex Irpan and Jean Harb who gave awesome feedback on this post, and Natasha Jensen for the idea of a ‘safety checklist’.
Bio: Ryan Lowe is a Ph.D. student in Computer Science in the Reasoning & Learning Lab at McGill University, supervised by Joelle Pineau. His current research focuses on multi-agent reinforcement learning and the emergence of language and behavioural complexity.
Original. Reposted with permission.
Related: