3 Reasons Why AutoML Won’t Replace Data Scientists Yet
We dispel the myth that AutoML is replacing Data Scientists jobs by highlighting three factors in Data Science development that AutoML can’t solve.
By Marcia Oliveira, a Senior Data Scientist at Skim Technologies
Automatic Machine Learning (aka AutoML) has been gaining traction within the Data Science community. This surge of interest is reflected on the development and release of numerous open source AutoML libraries (e.g., AutoWeka, MLBox, auto-sklearn, TPOT, HpBandSter, AutoKeras, prophet), and on the emergence of businesses focused on building and commercialising AutoML systems (e.g., DataRobot, DarwinAI, H2O.ai, OneClick.ai).
Although AutoML is a hot topic and many articles are being written about it (e.g., H2O.ai’s Erin LeDell, Fast.ai’s Rachel Thomas, and KDnuggets’ Matthew Mayo), just a few have emphasized and clarified the limitations of current AutoML systems. It is our intention to address this gap by pointing out what we believe to be AutoML’s main drawbacks currently.
The diagram below shows a typical Data Scientists workflow according to the popular TDSP methodology. This highlights the limited areas in which AutoML is currently used.
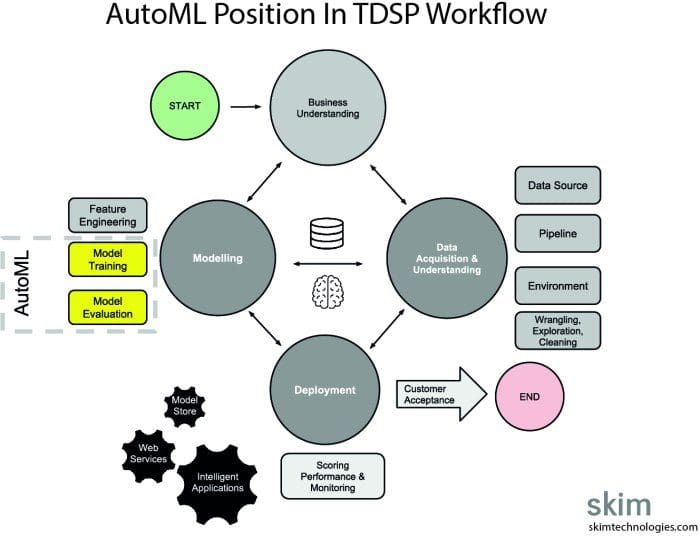
Figure 1: AutoML Application within TDSP, source: Skimtechnologies.com
Will AutoML replace Data Scientists?
It’s a common question that arises whenever the topic of AutoML is brought up. The TL;DR answer is no.
Besides the difficulty of automating many of the data science tasks, that’s not really the point behind AutoML; its purpose is to assist data scientists and free them from the burden of repetitive, and less demanding tasks, so they can invest their time on tasks that are more challenging, creative, and harder to automate. We go into more detail below, that highlights the creative thinking a Data Scientists performs that AutoML, in its current form, can’t replace.
Three limitations of current AutoML systems
Currently, AutoML systems can be fast at generating predictive models that achieve near-optimal performances. However, their coverage is still narrow and their true potential still untapped.
In this section, we highlight three limitations of existing AutoML systems: unsupervised & reinforcement learning, complex data types, and domain knowledge.
1. Unsupervised Learning & Reinforcement Learning
Despite being lesser known by the general public, unsupervised and reinforcement learning are important ML approaches used to solve different kinds of real-world problems (e.g., customer segmentation, industrial simulation).
Unsupervised learning techniques aim to discover patterns from data when no ground truth is available. In contrast with supervised learning, this type of ML approach does not rely on labelled datasets, which are typically very costly and hard to obtain. Also, there is no clear measure of success that can be used to assess the quality of unsupervised learning results, since there is no ground truth to measure against. As a result, it is harder to judge the effectiveness of different methods since there is no direct way to compare them. This subjectivity in the definition of “success” and the important role of expert knowledge during the process, are two likely reasons why existing AutoML systems do not cover this approach. Nonetheless, given that the majority of data in the world is unlabelled, AutoML systems would become even more useful if their scope was widened to include the automated application of such methods.
With reinforcement learning, software agents learn to perform a specific task through trial and error by receiving feedback from their own actions. If the action represents a step towards achieving the goal, then the agent receives a reward. Otherwise, it is punished. This way, the agent learns from its mistakes and improves with experience. Similarly to supervised learning, in reinforcement learning, there is a measure of success, which makes this ML task amenable to automation. However, to the best of our knowledge, no AutoML system has been proposed to automate the reinforcement learning process.
In short, contemporary AutoML overlooks the more challenging tasks of unsupervised and reinforcement learning, focusing only on supervised tasks that require labelled data as input.
2. Complex Data Types
Data is one of the most valuable commodities today, but not all data is equal. Data comes in different shapes and sizes, and the ability to extract patterns from it heavily depends on its format and complexity.
Most AutoML systems were first designed to work with the most common data type, which according to 2017’s Kaggle ML and Data Science Survey (Figure 1) is structured, tabular or “relational” data.

Figure 2: Most common data types used at work (from H2O.ai’s Erin LeDell blog post; source: Kaggle ML and Data Science Survey, 2017)
Some AutoML systems have also been extended to handle unstructured data, namely, text and images (e.g., Google Cloud AutoML Vision, Google Cloud AutoML Natural Language, AutoKeras, DataRobot), since these are two of the most prevalent data types (Figure 1).
Another very common type of data, mostly in the financial and retail industries, is time series data. Companies, such as DataRobot, OneClick.ai and H2O Driverless AI, developed tools to automatically build time series forecasting models. In the open source space, Facebook’s prophet and R’s forecast library attempt to do the same.
Network data and web data are, on the other hand, two more complex data types. These data types are still not part of the AutoML equation, thus limiting the type of problems that can be solved with AutoML. However, it is likely that, as development progresses and with tools such as the Skim Engine (Disclosure: I work at Skim Technologies and have been heavily involved in the development of this NLP Engine), AutoML systems will include automatic means to process these types of data in the near future.
3. Feature Engineering embedded with Domain Knowledge
AutoML systems have been considered a synonym of model selection and hyperparameter tuning, which represent only a small piece of the KDD puzzle. These two stages are the easiest to automate, given the objectivity and consistency of their steps across supervised learning problems. However, one of the key ingredients for building great ML models has been often disregarded from AutoML systems: feature engineering.
Feature engineering is more of an art than a science and it is arguably the stage offering the most fertile ground for human creativity to blossom. Manually crafting features that unearth meaningful aspects of the process one is trying to model, requires imagination, creativity and domain expertise. Consequently, the performance can vary if feature engineering is carried out by different data scientists.
Manual feature engineering is also problem-dependent and the type of features one can create is often bounded by the input dataset. As a consequence, it is one of the most time-consuming and laborious stages of any data science project, along with data cleaning and preprocessing.
Nevertheless, good enough models can be built by adopting a more generic and mechanical framework to feature creation that is dataset-agnostic (e.g., Deep Feature Synthesis).
Almost all of the advanced AutoML platforms include some sort of automated data preprocessing (e.g., handling missing values, dropping duplicates, scaling), but only a few offer automatic feature engineering (e.g., DataRobot, H2O Driverless AI). There are also open source solutions, notably FeatureTools. However, none of them are able to automatically incorporate domain knowledge into the ML process and this remains an exclusive human skill.
Despite the noteworthy attempts of automating the difficult and time-consuming task of feature engineering, the secret ingredient to obtaining high-quality models in many real-world problems continues to be domain knowledge. AutoML future development should focus on the building of more sophisticated methods for incorporating specific knowledge into automatically created features.
Ideally, more sophisticated methods for incorporating domain specific knowledge into the automatically created features should be developed, by exploiting regularities and involving a multidisciplinary team in the development of AutoML products. Flexibility is also essential, and AutoML systems should also offer the ability of combining automatically generated features with manually created ones.
Conclusion
We live in an era where the growth of data outpaces our ability to make sense of it. This is justified not only by current technological barriers but mostly by our reliance on experts to perform this task. AutoML is an exciting field that has been on the spotlight and which promises to mitigate this problem through intelligent automation of repetitive tasks of the ML workflow.
We expect big strides of progress in this field in a near future and we recognise the help of AutoML systems in addressing many of the challenges that we face out there.
Bio: Marcia Oliveira is a Senior Data Scientist at Skim Technologies, a data science services startup that helps corporates become data-driven. She holds a PhD in Network Science and an MSc in Data Science from the University of Porto, Portugal.
Resources:
- On-line and web-based: Analytics, Data Mining, Data Science, Machine Learning education
- Software for Analytics, Data Science, Data Mining, and Machine Learning
Related:
- Automatic Machine Learning is broken
- Accelerating Time Series Analysis with Automated Machine Learning
- Building AI to Build AI: The Project That Won the NeurIPS AutoML Challenge