Graduating in GANs: Going From Understanding Generative Adversarial Networks to Running Your Own
Read how generative adversarial networks (GANs) research and evaluation has developed then implement your own GAN to generate handwritten digits.
By Cecilia Shao, Product Growth at comet.ml

Generative Adversarial Networks (GANs) have taken over the public imagination —permeating pop culture with AI- generated celebrities and creating art that is selling for thousands of dollars at high-brow art auctions.
In this post, we’ll explore:
- Brief primer on GANs
- Understanding and Evaluating GANs
- Running your own GAN
There is a wealth of resources for catching up on GANs, so our focus for this article is to understand how GANs can be evaluated. We’ll also walk you through running your own GAN to generate handwritten digits like MNIST.

Brief primer on GANs
Since its inception in 2014 with Ian Goodfellow’s ‘Generative Adversarial Networks’ paper, progress with GANs has exploded and led to increasingly realistic outputs.
4.5 years of GAN progress on face generation:
https://t.co/kiQkuYULMC
https://t.co/8di6K6BxVC
Just three years ago, you could find Ian Goodfellow’s reply on this Reddit thread to a user asking about whether you can use GANs for text:

“GANs have not been applied to NLP because GANs are only defined for real-valued data.
GANs work by training a generator network that outputs synthetic data, then running a discriminator network on the synthetic data. The gradient of the output of the discriminator network with respect to the synthetic data tells you how to slightly change the synthetic data to make it more realistic.
You can make slight changes to the synthetic data only if it is based on continuous numbers. If it is based on discrete numbers, there is no way to make a slight change.
For example, if you output an image with a pixel value of 1.0, you can change that pixel value to 1.0001 on the next step.
If you output the word “penguin”, you can’t change that to “penguin + .001” on the next step, because there is no such word as “penguin + .001”. You have to go all the way from “penguin” to “ostrich”.
Since all NLP is based on discrete values like words, characters, or bytes, no one really knows how to apply GANs to NLP yet.”
Now GANs are being used to create all kinds of content including images, video, audio, and (yup) text. These outputs can be used as synthetic data for training other models or just for spawning interesting side projects like thispersondoesnotexist.com, thisairbnbdoesnotexist.com/, and This Machine Learning Medium post does not exist. ????
Behind the GAN
A GAN is comprised of two neural networks — a generator that synthesizes new samples from scratch, and a discriminator that compares training samples with these generated samples from the generator. The discriminator’s goal is to distinguish between ‘real’ and ‘fake’ inputs (ie. classify if the samples came from the model distribution or the real distribution). As we described, these samples can be images, videos, audio snippets, and text.
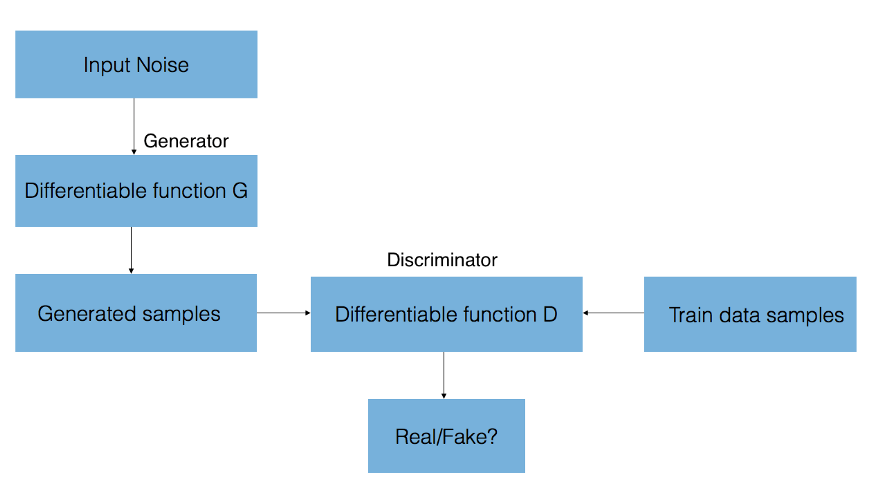
To synthesize these new samples, the generator is given random noise and attempts to generate realistic images from the learnt distribution of the training data.
The gradient of the output of the discriminator network (a convolutional neural network) with respect to the synthetic data informs how to slightly change the synthetic data to make it more realistic. Eventually the generator converges on parameters that reproduce the real data distribution, and the discriminator is unable to detect the difference.
You see and play with these converging data distributions with GAN Lab:
GAN Lab: Play with Generative Adversarial Networks in Your Browser!
GAN Lab was created by Minsuk Kahng, Nikhil Thorat, Polo Chau, Fernanda Viégas, and Martin Wattenberg, which was the…poloclub.github.io
Here’s a selection of the best guides on GANs :
- Stanford CS231 Lecture 13 — Generative Models
- Style-based GANs
- Understanding Generative Adversarial Networks
- Introduction to Generative Adversarial Networks
- Lillian Weng: From Gan to WGAN
- Dive head first into advanced GANs: exploring self-attention and spectral norm
- Guim Perarnau: Fantastic GANs and where to find them (Parts I & II)
Understanding and Evaluating GANs
Quantifying the progress of a GAN can feel very subjective — “Does this generated face look realistic enough?” , “Are these generated images diverse enough?” — and GANs can feel like black boxes where it’s not clear which components of the model impact learning or result quality.
To this end, a group from the MIT Computer Science and Artificial Intelligence (CSAIL) Lab, recently released a paper, ‘GAN Dissection: Visualizing and Understanding Generative Adversarial Networks’, that introduced a method for visualizing GANs and how GAN units relate to objects in an image as well as the relationship between objects.

Using a segmentation-based network dissection method, the paper’s framework allow us to dissect and visualize the inner workings of a generator neural network. This occurs by looking for agreements between a set of GAN units, referred to as neurons, and concepts in the output image such as tree, sky, clouds, and more. As a result, we’re able to identify neurons that are responsible for certain objects such as buildings or clouds.
Having this level of granularity into the neurons allows for edits to existing images (e.g. to add or remove trees as shown in the image) by forcefully activating and deactivating (ablating) the corresponding units for those objects.
However, it’s not clear if the network is able to reason about objects in a scene or if it’s simply memorizing these objects. One way to get closer to an answer for this question was to try to distort the image in unrealistic ways. Perhaps the most impressive part of MIT CSAIL’s interactive web demo of GAN Paint was how the model is seemingly able to limit these edits to ‘photorealistic’ changes. If you try to impose grass onto the sky, here’s what happens:

Even though we’re activating the corresponding neurons, it appears as though the GAN has suppressed the signal in later layers.

Another interesting way of visualizing GANs is to conduct latent space interpolation (remember, the GAN generate new instances by sampling from the learned latent space). This can be a useful way of seeing how smooth the transitions across generated samples are.

These visualizations can help us understand the internal representations of a GAN, but finding quantifiable ways to understand GAN progress and output quality is still an active area of research.
Two commonly used evaluation metrics for image quality and diversity are: the Inception Score and the Fréchet Inception Distance (FID). Most practitioners have shifted from the Inception Score to FID after Shane Barratt and Rishi Sharma released their paper ‘A Note on the Inception Score’ on key shortcomings of the former.