Spatio-Temporal Statistics: A Primer
Marketing scientist Kevin Gray asks University of Missouri Professor Chris Wikle about Spatio-Temporal Statistics and how it can be used in science and business.
Kevin Gray: What is Spatio-Temporal Statistics? Can you give us a non-technical definition and brief history of it?
Chris Wikle: From my perspective, spatio-temporal statistics is concerned with making inference or prediction about data that have labels showing when (time) and where (space) they were collected. In this case, the space might be geographic space, or socio-economic space, or even social network space. Time scales can range from microseconds to millennia. Not surprisingly, these types of data are increasingly common across the sciences, engineering, government, and business. This is related to the advent of inexpensive data collection devices and resources (web data, GPS, biomedical, etc.) and high-volume, large-platform data collection (e.g., satellites). These data sources have led to interest in answering quite complex questions, and the desire to make predictions that involve space and time.
Cressie’s (1993) classic book (Statistics for Spatial Data) has some sparse coverage of spatio-temporal statistics. From that, it is pretty clear that formal consideration of this topic started in the mid-1970s, largely tied to the increased interest in environmental issues (e.g., air pollution) at the time. But, of course, there were also interesting studies in medicine (tumor growth), and econometrics around that time. Methodological development in spatio-temporal statistics started to see greater interest in the academic research community in the mid 1980s, with slow and steady progress through the mid-1990s. At that point, there was somewhat of a confluence of events that led to a dramatic increase in research on this topic. That was due to the beginning of the data revolution, and the realization from the classic Gelfand and Smith (1990) paper that Markov chain Monte Carlo methods could be used to solve complex, real-world problems from the Bayesian perspective.
The Bayesian perspective was very important for spatio-temporal statistics because it allowed one to consider uncertainty across all aspects of the model (the observation/data collection component, the latent spatio-temporal dependence process component, and the parameters that controlled those two components). The work in this area from the mid 1990s through the first decade of the 2000s is summarized in Cressie and Wikle (2011, Statistics for Spatio-Temporal Data). Since that time, the second great explosion in spatio-temporal analysis has occurred due to the unprecedented availability of rich data sources, and the popularization and practical implementation of deep learning models in the computer science literature.
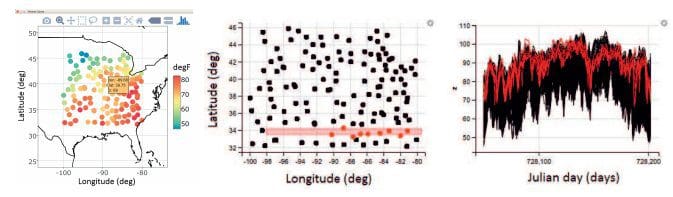
What are some examples of how it is used in scientific fields?
As I mentioned above, most examples of spatio-temporal statistical analysis to date have been in the area of environmental and ecological statistics (e.g., evaluating air pollution impacts, potential for climate change, filling in gappy satellite data, long-lead forecasts of El Nino, animal movement, invasive species, etc.). Probably the second biggest area of application has been in neuroimaging, in particular functional MRI analyses, followed by epidemiology (tracking disease spread through time). However, in the last few years, the explosion in deep learning has led to the use of these models in diverse areas such as computer vision, dynamic network analysis, and robotic control (among many others).
Are there examples of it being applied in marketing or other areas of the business sector you can share with us?
Most definitely! First, I’ve noticed the interest from the marketing and business sector in terms of job opportunities for our students. Again, this is tied to the tremendous data sources we have available now and the interest in using it in ways that can also quantify the uncertainty associated with predictions and inference. I’ve also seen evidence in the Ph.D. research in our Marketing Department here at Mizzou. Just last week I had the pleasure of reading a working paper from a student that dealt with spatial (city) and time effects of marketing strategies for businesses that employ so-called online-to-offline two-sided service platforms. So, I think this is not only a viable area in terms of using state-of-the-art methods, but also it is a growing area of research as well.
Do AI and machine learning also have a role in Spatio-Temporal Statistics?
I think the answer is again “most definitely.” I’m not sure I would have made that statement five years ago, but I’m a recent convert to the value of some of these methods. The turning point for me was when I decided to teach a special topics class in deep learning for our graduate students. The goal was to go inside these methods and learn them to the point we could program them ourselves. I gained a new respect for these methods, especially those that dealt with dependent inputs (images) and sequences (time series, sequences of words); that is, convolutional neural networks and recurrent neural networks (and their variants). Increasingly, these are being combined in novel ways to deal with spatio-temporal data as well. The challenge has been to implement these models in ways that consider the issues associated with uncertain observations (measurement error, sampling error), and provide probabilistically-valid uncertainty measurements. My own recent research is involved with trying to integrate these ideas into more formal spatio-temporal statistical modeling constructs. It is exciting (and daunting) to be working at this interface, but there is much to be gained from borrowing and exchanging ideas across disciplines.
Are there special considerations or things we need to be particularly watchful for in Spatio-Temporal Statistics? Are there common mistakes you see made?
I believe one of the biggest challenges we face in spatio-temporal statistics is being able to come up with efficient methods that can deal with real-world dependence, but do it in a way that we can still provide some coherent assessment of the uncertainty in our result. For example, just dealing with “big” spatio-temporal data and getting any sensible result (inference or prediction) can be computationally challenging. Sometimes we are simply forced by necessity to use existing software that might provide an answer, but with methods that are not applicable to the data. Similarly, we might consider an off-the-shelf model for spatial and temporal dependence, without considering how realistic that model is in terms of describing the real-world phenomena. This happens a lot when the real-process is dynamic (in that spatial fields evolve through time in a mechanistic way) yet this gets swept under the table when one just tries to specify a joint space-time covariance function. These problems are slowly getting solved as we research new methods and, importantly, develop efficient and accessible ways to implement them.
How do you see this field evolving in the next decade or so? Are there special challenges it faces?
In addition to the challenges mentioned previously, I think it will be a challenge to integrate the innovations that are coming from the engineering and computer science disciplines with the statistical modeling. I also think there is a great need to increase the complexity of our models in order to capture how multiple spatio-temporal processes are interacting at once, and in a way that can accommodate multiple data sources of varying sampling frequency and quality. Another big challenge is in visualization. The visualization of spatio-temporal data and model output is in its infancy, and there are many challenging problems. This is tied in to the more general concerns of communicating results from complex models in a way that practitioners can utilize and convey the relevant information to others. Overall, spatio-temporal statistics is such a fun area to work in because it is extremely relevant to almost every discipline and business area, and there are so many interesting problems and challenges. When I started working in this area in the early 1990s, I can remember someone telling me that I needed to broaden my research because there weren’t that many problems remaining. One of my best decisions was to ignore that advice!
Thanks for the opportunity to talk about spatio-temporal statistics Kevin!
Thank you, Chris!
Kevin Gray is President of Cannon Gray, a marketing science and analytics consultancy. He has more than 30 years’ experience in marketing research with Nielsen, Kantar, McCann and TIAA. Kevin also co-hosts the audio podcast series MR Realities.
Christopher K. Wikle is Curators' Distinguished Professor of Statistics at the University of Missouri. He is co-author of Statistics for Spatio-Temporal Data, winner of the 2011 Prose Award for Excellence in the Mathematics Category from the Association of American Publishers and the 2013 DeGroot Prize from the International Society for Bayesian Analysis. In addition, he has co-authored Spatio-Temporal Statistics with R (available for free to download at spacetimewithr.org) and published more than 150 papers on statistical topics.
Related: