Which Face is Real?
Which Face Is Real? was developed based on Generative Adversarial Networks as a web application in which users can select which image they believe is a true person and which was synthetically generated. The person in the synthetically generated photo does not exist.

Which Face is Real?
Which Face Is Real? was developed by Jevin West and Carl Bergstrom from the University of Washingtion as part of the Calling Bullshit Project. It acts as a sort of game that anyone can play. Visitors to the site have a choice of two images, one of which is real and the other of which is a fake generated by StyleGAN.
The project was implemented by Jevin and Carl as a course that will teach its students how to identify misinformation.
Our aim in this course is to teach you how to think critically about the data and models that constitute evidence in the social and natural sciences.
The world is awash in bullshit. Politicians are unconstrained by facts. Science is conducted by press release. Higher education rewards bullshit over analytic thought. Startup culture elevates bullshit to high art. Advertisers wink conspiratorially and invite us to join them in seeing through all the bullshit — and take advantage of our lowered guard to bombard us with bullshit of the second order. The majority of administrative activity, whether in private business or the public sphere, seems to be little more than a sophisticated exercise in the combinatorial reassembly of bullshit.
We're sick of it. It's time to do something, and as educators, one constructive thing we know how to do is to teach people. So, the aim of this course is to help students navigate the bullshit-rich modern environment by identifying bullshit, seeing through it, and combating it with effective analysis and argument.
Seattle, WA.
How do you tell the Difference?
Water splotches
- The algorithm produces shiny blobs that look somewhat like water splotches on old photographic prints. These splotches can appear anywhere in the image, but often show up at the interface between the hair and the background.

Background problems
- The background of the image can appear in a weird state such as blurriness or mishaped objects. This is due to the fact that the neural net is trained on the face and less emphasis is given to the background of the image.

Symmetry
- At the moment, the generator is not able to produce realistic looking eyeglasses, however this may not be obvious at first. A common problem is asymmetry. Look at the frame structure; often the frame will take one style at the left and another at the right, or there will be a wayfarer-style ornament on one side but not on the other. Other times the frame will just be crooked or jagged. In addition, asymmetries in facial hair, different earrings in the left and right ear, and different forms of collar or fabric on the left and right side can be present.

Hair
- Hair is known to be difficult for the algorithm to render properly. Disconnected strands, too straight, or too streaked will be common problems when generating hair.

Fluorescent bleed
- Fluorescent colors can sometimes bleed into the hair or face from the background. People can sometimes mistake this for colored hair.

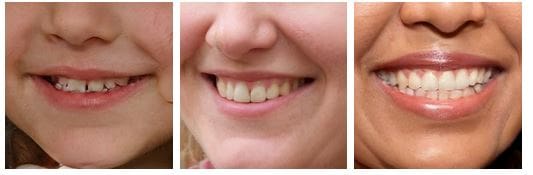
Teeth
- Teeth are also hard to render and can come out as odd-shaped, asymmetric or for those that can identify teeth, sometimes 3 incisors can appear in the image.
Trying the algorithm
All the code for the StyleGAN have been open-sourced in the stylegan repository. It gives details on how you can run the styleGAN algorithm yourself.
However, there are a few barriers:
- System Requirements
- Training time
System Requirements
- Both Linux and Windows are supported, but we strongly recommend Linux for performance and compatibility reasons.
- 64-bit Python 3.6 installation. We recommend Anaconda3 with numpy 1.14.3 or newer.
- TensorFlow 1.10.0 or newer with GPU support.
- One or more high-end NVIDIA GPUs with at least 11GB of DRAM. We recommend NVIDIA DGX-1 with 8 Tesla V100 GPUs.
- NVIDIA driver 391.35 or newer, CUDA toolkit 9.0 or newer, cuDNN 7.3.1 or newer.
That type of compute and storage capacity is not common among individuals.
Training time
Below you will find NVIDIA's reported expected training times for default configuration of the train.py script (available in the stylegan repository) on a Tesla V100 GPU for the FFHQ dataset (available in the stylegan repository).
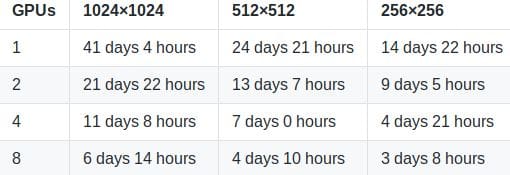
The time taken to properly train this algorithm is far beyond the patience of an everyday individual.
Behind the scenes
The science behind the app is thanks to a team at NVIDIA and their work on Generative Adversarial Networks. They created the StyleGAN. To learn a little more about this amazing technique, I have provided some resources and concise explanations below.
Generative Adversarial Network
For those wanting a refresher on GAN's, this playlist of tutorials on GAN's by Ahlad Kumar is quite helpful.
Generative Adversarial Networks first made the rounds in 2014 as an extension of generative models via an adversarial process in which we simultaneously train two models:
- A generative model that captures the data distribution (training)
- A discriminative model that estimates the probability that a sample came from the
training data rather than the generative model.
The goal of GAN's is to generate artificial/fake samples that are indistinguishable from authentic/real samples. A common example is generating artificial images that are indistinguishable from real photos of people. The human visual processing system would not be able to differentiate these images so easily as the images will look like real people at first. We will later see how this happens and how we can distinguish a photo of a real person and a photo generated by an algorithm.
StyleGAN
The algorithm behind this amazing app was the brainchild of Tero Karras, Samuli Laine and Timo Aila at NVIDIA and called it StyleGAN. The algorithm is based on earlier work by Ian Goodfellow and colleagues on General Adversarial Networks (GAN's). NVIDIA open sourced the code for their StyleGAN which uses GAN's in which two neural networks, one to generate indistinguishable artificial images while the other will attempt to distinguish between fake and real photographs.
But while we’ve learned to distrust user names and text more generally, pictures are different. You can't synthesize a picture out of nothing, we assume; a picture had to be of someone. Sure a scammer could appropriate someone else’s picture, but doing so is a risky strategy in a world with google reverse search and so forth. So we tend to trust pictures. A business profile with a picture obviously belongs to someone. A match on a dating site may turn out to be 10 pounds heavier or 10 years older than when a picture was taken, but if there’s a picture, the person obviously exists.
No longer. New adversarial machine learning algorithms allow people to rapidly generate synthetic 'photographs' of people who have never existed.
Generative models have a limitation in which it's hard to control the characteristics such as facial features from photographs. NVIDIA's StyleGAN is a fix to this limitation. The model allows the user to tune hyper-parameters that can control for the differences in the photographs.
StyleGAN solves the variability of photos by adding styles to images at each convolution layer. These styles represent different features of a photos of a human, such as facial features, background color, hair, wrinkles etc. The algorithm generates new images starting from a low resolution (4x4) to a higher resolution (1024x1024). The model generates two images A and B and then combines them by taking low-level features from A and rest from B. At each level, different features (styles) are used to generate an image:
- Coarse styles (resolution between 4 to 8) - pose, hair, face, shape
- Middle styles (resolution between 16 to 32) - facial features, eyes
- Fine styles (resolution between 64 to 1024)- color scheme

Properties of the style-based generator
Style mixing
- The generator employs mixing regularization where a given percentage of images are generated using two random latent codes instead of one during training. When generating such an image, the user simply switches from one latent code to another (i.e. style mixing) at a randomly selected point in the synthesis network. In the below image we can see how the styles generated by one latent code (source) override a subset of the styles of another latent code (destination)

Stochastic Variation
- Many aspects of a photograph are stochastic (i.e. random) such as wrinkles, hair placement, stubbles, freckles, pimples. The architecture of StyleGAN adds per-pixel noise after each convolution layer in order for images to show these variations as seen in real life. As seen in the below image, noise added by the generator only affects the stochastic aspects of the image and leaves the higher level styles as they are.

Separation of global effects from stochasticity
- Changes to the style of the image will have global effects such as changing pose, gender, face etc. but the noise such as freckles, wrinkles, hair placement will only affect the stochastic variation. In StyleGAN, global effects such as pose, lighting or background style can be controlled coherently and the noise is added independently to each pixel and is thus ideally suited for controlling stochastic variation.
Helpful resources
- StyleGAN
- How to Recognize Fake AI generated Images
- NVIDIA Open-Sources Hyper-Realistic Face Generator StyleGAN
Related:
- The New Neural Internet is Coming
- Generative Adversarial Networks, an overview
- See NVIDIA Deep Learning In Action [Webinar Series]