Overview of Different Approaches to Deploying Machine Learning Models in Production
Learn the different methods for putting machine learning models into production, and to determine which method is best for which use case.
By Julien Kervizic, Senior Enterprise Data Architect at GrandVision NV

There are different approaches to putting models into productions, with benefits that can vary dependent on the specific use case. Take for example the use case of churn prediction, there is value in having a static value already that can easily be looked up when someone call a customer service, but there is some extra value that could be gained if for specific events, the model could be re-run with the newly acquired information.
There is generally different ways to both train and server models into production:
- Train: one off, batch and real-time/online training
- Serve: Batch, Realtime (Database Trigger, Pub/Sub, web-service, inApp)
Each approach having its own set of benefits and tradeoffs that need to be considered.
One off Training
Models don’t necessarily need to be continuously trained in order to be pushed to production. Quite often a model can be just trained ad-hoc by a data-scientist, and pushed to production until its performance deteriorates enough that they are called upon to refresh it.

From Jupyter to Production
Data Scientists prototyping and doing machine learning tend to operate in their environment of choice Jupyter Notebooks. Essentially an advanced GUI on a repl, that allows you to save both code and command outputs.
Using that approach it is more than feasible to push an ad-hoc trained model from some piece of code in Jupyter to production. Different types of libraries and other notebook providers help further tie the link between the data-scientist workbench and production.
Model Format
Pickle converts a python object to to a bitstream and allows it to be stored to disk and reloaded at a later time. It is provides a good format to store machine learning models provided that their intended applications is also built in python.
ONNX the Open Neural Network Exchange format, is an open format that supports the storing and porting of predictive model across libraries and languages. Most deep learning libraries support it and sklearn also has a library extension to convert their model to ONNX’s format.
PMML or Predictive model markup language, is another interchange format for predictive models. Like for ONNX sklearn also has another library extension for converting the models to PMML format. It has the drawback however of only supporting certain type of prediction models.PMML has been around since 1997 and so has a large footprint of applications leveraging the format. Applications such as SAP for instance is able to leverage certain versions of the PMML standard, likewise for CRM applications such as PEGA.
POJO and MOJO are H2O.ai’s export format, that intendeds to offers an easily embeddable model into java application. They are however very specific to using the H2O’s platform.
Training
For one off training of models, the model can either be trained and fine tune ad hoc by a data-scientists or training through AutoML libraries. Having an easily reproducible setup, however helps pushing into the next stage of productionalization, ie: batch training.
Batch Training
While not fully necessary to implement a model in production, batch training allows to have a constantly refreshed version of your model based on the latest train.
Batch training can benefit a-lot from AutoML type of frameworks, AutoML enables you to perform/automate activities such as feature processing, feature selection, model selections and parameter optimization. Their recent performance has been on par or bested the most diligent data-scientists.
Using them allows for a more comprehensive model training than what was typically done prior to their ascent: simply retraining the model weights.
Different technologies exists that are made to support this continuous batch training, these could for instance be setup through a mix of airflow to manage the different workflow and an AutoML library such as tpot, Different cloud providers offer their solutions for AutoML that can be put in a data workflow. Azure for instance integrates machine learning prediction and model training with their data factory offering.
Real time training
Real-time training is possible with ‘Online Machine Learning’ models, algorithms supporting this method of training includes K-means (through mini-batch), Linear and Logistic Regression (through Stochastic Gradient Descent) as well as Naive Bayes classifier.
Spark has StreamingLinearAlgorithm/StreamingLinearRegressionWithSGD to perform these operations, sklearn has SGDRegressor and SGDClassifier that can be incrementally trained. In sklearn, the incremental training is done through the partial_fit method as shown below:
import pandas as pd from sklearn import linear_model X_0 = pd.DataFrame([[0,0], [1,0]] ) y_0 = pd.DataFrame([[0], [0]]) X_1 = pd.DataFrame([[0,1], [1,1], [1,1]]) y_1 = pd.DataFrame([[1], [1], [1]]) clf = linear_model.SGDClassifier() clf.partial_fit(X_0, y_0, classes=[0,1]) print(clf.predict([[0,0]])) # -> 0 print(clf.predict([[0,1]])) # -> 0 clf.partial_fit(X_1, y_1, classes=[0,1]) print(clf.predict([[0,0]])) # -> 0 print(clf.predict([[0,1]])) # -> 1
When deploying this type of models there needs to be serious operational support and monitoring as the model can be sensitive to new data and noise, and model performance needs to be monitored on the fly. In offline training, you can filter points of high leverage and correct for this type of incoming data. This is much harder to do when you are constantly updating your model training based on a stream of new data points.
Another challenge that occurs with training online model is that they don’t decay historical information. This means that, on case there are structural changes in your datasets, the model will need to be anyway re-trained and that there will be a big onus in model lifecycle management.
Batch vs. Real-time Prediction
When looking at whether to setup a batch or real-time prediction, it is important to get an understanding of why doing real-time prediction would be important. It can potentially be for getting a new score when significant event happen, for instance what would be the churn score of customer when they call a contact center. These benefits needs to be weighted against the complexity and cost implications that arise from doing real-time predictions.
Load implications
Catering to real time prediction, requires a way to handle peak load. Depending on the approach taken and how the prediction ends up being used, choosing a real-time approach, might also require to have machine with extra computing power available in order to provide a prediction within a certain SLA. This contrasts with a batch approach where the predictions computing can be spread out throughout the day based on available capacity.
Infrastructure Implications
Going for real-time, put a much higher operational responsibility. People need to be able to monitor how the system is working, be alerted when there is issue as well as take some consideration with respect to failover responsibility. For batch prediction, the operational obligation is much lower, some monitoring is definitely needed, and altering is desired but the need to be able to know of issues arising directly is much lower.
Cost Implications
Going for real-time predictions also has costs implications, going for more computing power, not being able to spread the load throughout the day can force into purchasing more computing capacity than you would need or to pay for spot price increase. Depending on the approach and requirements taken there might also be extra cost due to needing more powerful compute capacity in order to meet SLAs. Furthermore, there would tend to be a higher infrastructure footprint when choosing for real time predictions. One potential caveat there is where the choice is made to rely on in app prediction, for that specific scenario the cost might actually end up being cheaper than going for a batch approach.
Evaluation Implications
Evaluating the prediction performance in real-time manner can be more challenging than for batch predictions. How do you evaluate performance when you are faced with a succession of actions in a short burst producing multiple predictions for a given customer for instance? Evaluating and debugging real-time prediction models are significantly more complex to manage. They also require a log collection mechanism that allows to both collect the different predictions and features that yielded the score for further evaluation.
Batch Prediction Integration
Batch predictions rely on two different set of information, one is the predictive model and the other one is the features that we will feed the model. In most type of batch prediction architecture, ETL is performed to either fetch pre-calculated features from a specific datastore (feature-store) or performing some type of transformation across multiple datasets to provide the input to the prediction model. The prediction model then iterates over all the rows in the datasets providing the different score.
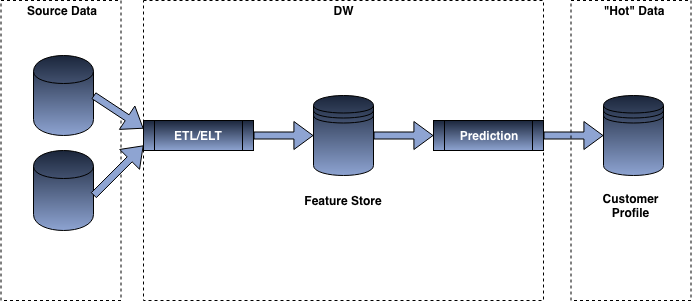
Once all the predictions have been computed, we can then “serve” the score to the different systems wanting to consume the information. This can be done in different manner depending on thee use case for which we want to consume the score, for instance if we wanted to consume the score on a front-end application, we would most likely push the data to a “cache” or NoSQL database such as Redis so that we can offer milliseconds responses, while for certain use cases such as the creation of an email journey, we might just be relying on a CSV SFTP export or a data load to a more traditional RDBMS.
Real-time Prediction integration
Being able to push model into production for real-time applications require 3 base components. A customer/user profile, a set of triggers and predictive models.

Profile: The customer profile contains all the related attribute to the customer as well as the different attributes (eg: counters) necessary in order to make a given prediction. This is required for customer level prediction in order to reduce the latency of pulling the information from multiple places as well as to simplify the integration of machine learning models in productions. In most cases a similar type of data store would be needed in order to effectively fetch the data needed to power the prediction model.
Triggers: Triggers are events causing the initiation of process, they can be for churn for instance, call to a customer service center, checking information within your order history, etc …
Models: models need to have been pre-trained and typically exported to one of the 3 formats previously mentioned (pickle, ONNX or PMML) to be something that we could easily port to production.
There are quite a few different approach to putting models for scoring purpose in production:
- Relying on in Database integration: a lot of database vendors have made a significant effort to tie up advanced analytics use cases within the database. Be it by direct integration of Python or R code, to the import of PMML model.
- Exploiting a Pub/Sub model: The prediction model is essentially an application feeding of a data-stream and performing certain operations, such as pulling customer profile information.
- Webservice: Setting up an API wrapper around the model prediction and deploying it as a web-service. Depending on the way the web-service is setup it might or might not do the pull or data needed to power the model.
- inApp: it is also possible to deploy the model directly into a native or web application and have the model be run on local or external datasources.
Database integrations
If the overall size of your database is fairly small (< 1M user profile) and the update frequency is occasional it can make sense to integrate some of the real-time update process directly within the database.
Postgres possess an integration that allows to run Python code as functions or stored procedure called PL/Python. This implementation has access to all the libraries that are part of the PYTHONPATH, and as such are able to use libraries such as Pandas and SKlearn to run some operations.
This can be coupled with Postgres’ Triggers Mechanism to perform a run of the database and update the churn score. For instance if a new entry is made to a complaint table, it would be valuable to have the model be re-run in real-time.
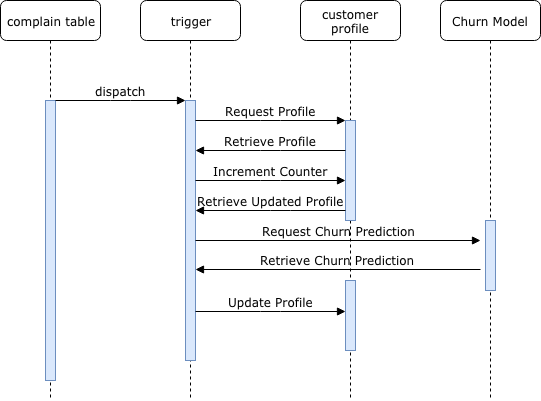
Sequence flow
The flow could be setup in the following way:
New Event: When a new row is inserted in the complain table, an event trigger is generated.
Trigger: The trigger function would update the number of complaint made by this customer in the customer profile table and fetch the updated record for the customer.
Prediction Request: Based on that it would re-run the churn model through PL/Python and retrieve the prediction.
Customer Profile Update: It can then re-update the customer profile with the updated prediction. Downstream flows can then happen upon checking if the customer profile has been updated with new churn prediction value.
Technologies
Different databases are able to support the running of Python script, this is the case of PostGres which has a native Python integration as previously mentioned, but also of Ms SQL Server through its’ Machine Learning Service (in Database), other databases such as Teradata, are able to run R/Python script through an external script command. While Oracle supports PMML model through its data mining extension.
Pub/Sub
Implementing real-time prediction through a pub/sub model allows to be able to properly handle the load through throttling. For engineers, it also means that they can just feed the event data through a single “logging” feed, to which different application can subscribe.
An example, of how this could be setup is shown below:
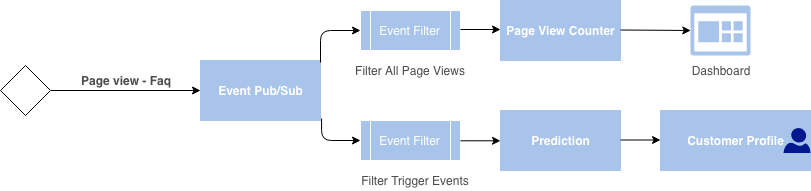
The page view event is fired to a specific event topic, on which two application subscribe a page view counter, and a prediction. Both of these application filter out specific relevant event from the topic for their purpose and consume the different messages in the topics. The page view counter app, provides data to power a dashboard, while the prediction app, updates the customer profile.

Sequence flow:
Event messages are pushed to the pub/sub topic as they occur, the prediction app poll the topic for new messages. When a new message is retrieved by the prediction app, it will request and retrieve the customer profile and use the message and the profile information to make a prediction. which it will ultimately push back to the customer profile for further use.
A slightly different flow can be setup where the data is first consumed by an “enrichment app” that adds the profile information to the message and then pushes it back to a new topic to finally be consumed by the prediction app and pushed onto the customer profile.
Technologies:
The typical open source combination that you would find that support this kind of use case in the data ecosystem is a combination of Kafka and Spark streaming, but a different setup is possible on the cloud. On google notably a google pub-sub/dataflow (Beam) provides a good alternative to that combination, on azure a combination of Azure-Service Bus or Eventhub and Azure Functions can serve as a good way to consume the messages and generate these predictions.
Web Service
We can implement models into productions as web-services. Implementing predictions model as web-services are particularly useful in engineering teams that are fragmented and that need to handle multiple different interfaces such as web, desktop and mobile.
Interfacing with the web-service could be setup in different way:
- Either providing an identifier and having the web-service pull the required information, compute the prediction and return its’ value
- Or by accepting a payload, converting it to a data-frame, making the prediction and returning its’ value.
The second approach is usually recommended in cases, when there is a lot of interaction happening and a local cache is used to essentially buffer the synchronization with the backend systems, or when needing to make prediction at a different grain than a customer id, for instance when doing session based predictions.
The systems making use of local storage, tend to have a reducer function, which role is to calculate what would be the customer profile, should the event in local storage be integrated back. As such it provides an approximation of the customer profile based on local data.
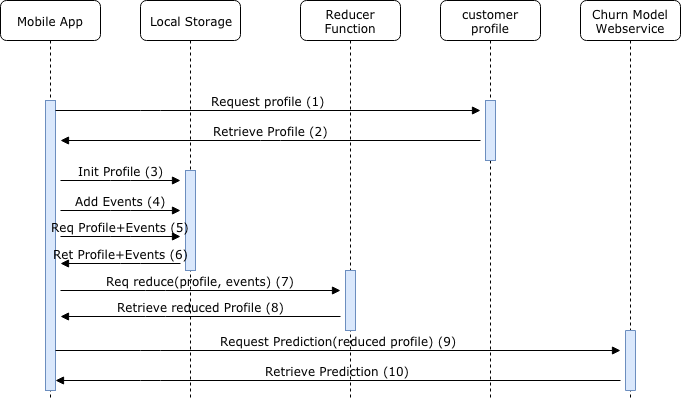
Sequence Flow
The flow for handling the prediction using a mobile app, with local storage can be described in 4 phases.
Application Initialization (1 to 3): The application initializes, and makes a request to the customer profile, and retrieve its initial value back, and initialize the profile in local storage.
Applications (4): The application stores the different events happening with the application into an array in local storage.
Prediction Preparation (5 to 8): The application wants to retrieve a new churn prediction, and therefore needs to prepare the information it needs to provide to the Churn Web-service. For that, it makes an initial request to local storage to retrieve the values of the profile and the array of events it has stored. Once they are retrieve, it makes a request to a reducer function providing these values as arguments, the reducer function outputs an updated* profile with the local events incorporated back into this profile.
Web-service Prediction (9 to 10): The application makes a request to the churn prediction web-service, providing the different the updated*/reduced customer profile from step 8 as part of the payload. The web-service can then used the information provided by the payload to generate the prediction and output its value, back to the application.
Technologies
There are quite a few technologies that can be used to power a prediction web-service:
Functions
AWS Lambda functions, Google Cloud functions and Microsoft Azure Functions (although Python support is currently in Beta) offer an easy to setup interface to easily deploy scalable web-services.
For instance on Azure a prediction web-service could be implemented through a function looking roughly like this:
import logging
import azure.functions as func
import pandas as pd
from sklearn.linear_model import LogisticRegression
from sklearn.externals import joblib
def main(req: func.HttpRequest) -> func.HttpResponse:
logging.info('Python HTTP trigger function processed a request.')
if req.body:
try:
logging.info("Converting Request to DataFrame")
req_body = req.get_json()
df_body = pd.DataFrame([req_body])
logging.info("Loadding the Prediction Model")
filename = "model.pckl"
loaded_model = joblib.load(filename)
# Features names need to have been added to the pickled model
feature_names = loaded_model.feature_names
# subselect only the feature names
logging.info("Subselecting the dataframe")
df_subselect = df_body[feature_names]
logging.info("Predicting the Probability")
result = loaded_model.predict_proba(df_subselect)
# We are looking at the probba prediction for class 1
prediction = result[0][1]
return func.HttpResponse("{prediction}".format(prediction=prediction), status_code=200)
except ValueError:
pass
else:
return func.HttpResponse(
"Please pass a name on the query string or in the request body",
status_code=400
)
Container
An alternative to functions, is to deploy a flask or django application through a docker container (Amazon ECS, Azure Container Instance or Google Kubernetes Engine). Azure for instance provides an easy way to setup prediction containers through its’ Azure Machine Learning service.
Notebooks
Different notebooks providers such as databricks and dataiku have notably worked on simplifying the model deployment from their environments. These have the feature of setting up a web service to a local environment or deploying to external systems such as Azure ML Service, Kubernetes engine etc…
In App
In certain situations when there are legal or privacy requirements that do not allow for data to be stored outside of an application, or there exists constraints such as having to upload a large amount of files, leveraging a model within the application tend to be the right approach.
Android-ML Kit or the likes of Caffe2 allows to leverage models within native applications, while Tensorflow.js and ONNXJS allow for running models directly in the browser or in apps leveraging javascripts.
Considerations
Beside the method of deployments of the models, they are quite a few important considerations to have when deploying to production.
Model Complexity
The complexity of the model itself, is the first considerations to have. Models such as a linear regressions and logistic regression are fairly easy to apply and do not usually take much space to store. Using more complex model such as a neural network or complex ensemble decision tree, will end up taking more time to compute, more time to load into memory on cold start and will prove more expensive to run.
Data Sources
It is important to consider the difference that could occur between the datasource in productions and the one used for training. While it is important for the data used for the training to be in sync with the context it would be used for in production, it is often impractical to recalculate every value so that it becomes perfectly in-sync.
Experimentation framework
Setting up an experimentation framework, A/B testing the performance of different models versus objective metrics. And ensuring that there is sufficient tracking to accurately debug and evaluate models performance a posteriori.
Wrapping Up
Choosing how to deploy a predictive models into production is quite a complex affair, there are different way to handle the lifecycle management of the predictive models, different formats to stores them, multiple ways to deploy them and very vast technical landscape to pick from.
Understanding specific use cases, the team’s technical and analytics maturity, the overall organization structure and its’ interactions, help come to the the right approach for deploying predictive models to production.
Bio: Julien Kervizic is a Senior Enterprise Data Architect at GrandVision NV.
Original. Reposted with permission.
Related: