All Models Are Wrong – What Does It Mean?
During your adventures in data science, you may have heard “all models are wrong.” Let’s unpack this famous quote to understand how we can still make models that are useful.
By Sydney Firmin, Alteryx.
“Essentially, all models are wrong, but some models are useful.” – George Box
This famous George Box quote was first recorded in 1976 in the paper “Science and Statistics,” published in the Journal of the American Statistical Association. It is an important quote to the field of statistics and analytical models and can be unpacked in two parts.
All Models Are Wrong
To dig into this statement, we need to define and examine what a model is.
For the context of this article, a model can be thought of as a simplified representation of a system or object. Statistical models approximate patterns in a data set by making assumptions about the data as well as the environment it was gathered in and applied to.
The three broad categories of assumptions made by statistical models are distributional assumptions (assumptions about the distribution of values in a variable or the distribution of observational errors), structural assumptions (assumptions about the functional relationship between variables), and cross-variation assumptions (joint probability distribution).
For example, a linear regression model assumes that the relationships between variables in a data set are linear (and only linear). In the eyes of a linear model, any distance between the observations that make up the data set and the modeled line is just noise (i.e., random or unexplained fluctuations in the data) and can ultimately be ignored.
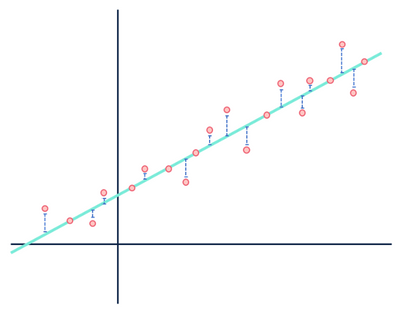
Pay no mind to the distances in blue.
George Box stated that all models are wrong specifically in the context of statistical models. Because the very nature of a model is a simplified and idealized representation of something, all models will be wrong in some sense. Models will never be “the truth” if truth means entirely representative of reality. It is very important to consider the assumptions made in generating a model because models are only truly helpful when the assumptions are held up.
Maps and Miniatures
Similar observations to Box’s “all models are wrong” are present in many different fields.
There is an aphorism that references the map-territory relation, attributed to Alfred Korzybski:
A map is not the territory it represents, but, if correct, it has a similar structure to the territory, which accounts for its usefulness.
Maps are useful because they are abstractions of a real object at a more manageable scale, but they will always exclude some level of detail. Depending on how much area a map includes, there may also be some distortion due to the projection of the map (caused by the tricky process of converting a spherical globe to a flat representation).
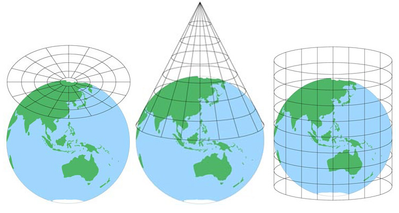
(Image source.)
The only truly accurate map would be a 1:1 replication of the territory it represents. However, a map like that would be no more helpful than navigating the territory itself.
Consider the quote from poet Paul Valery:
Everything simple is false. Everything which is complex is unusable.
Named after a Stanford business professor, Bonini’s Paradox describes the challenge of creating useful, complete models or simulations of complex systems. There is often a balancing act between complexity and accuracy in model development. If the goal of a model is to make a relationship or system clearer, added complexity defeats that purpose (although it might make the model more accurate).
On a high level, the map-territory relation also describes the relationship between an object and a representation of the object.
If you’ve ever taken a philosophy class, you may have come across the work The Treachery of Images by surrealist artist Rene Magritte.

The text translates to “This is not a pipe.” And it isn’t. We can’t stuff this (digital) image with tobacco and smoke it as it is just a representation of a real object.
Models are abstractions. Like maps, or miniature architectural models, or schematics, they cannot capture every detail of the object or system they are based on, if only because they do not exist in the real world and do not function in the same way.

If All Models Are Wrong, Why Bother?
George Box’s aphorism is not without its critics.
The problem many statisticians have with this quote seem to broadly fall into two categories:
- Models being wrong is an obvious statement. Of course all models are wrong, they’re models.
- This quote is used as an excuse for bad models.
Statistician J. Michael Steele has been critical of the adage (see this personal essay). Steele’s primary argument is that “wrong” only comes into play if the model does not correctly answer the question that it claims to answer (e.g., that a building on a map is mislabeled, not that the building is represented by a little square). Steele goes on to state:
The majority of published statistical methods hunger for one honest example.
Steele argues that statistical models are often not up to an adequate fitness measure, and many models developed by statisticians are not sufficient for their intended use cases.
In the article Statistics as a Science, Not an Art: The Way to Survive in Data Science, Mark van der Laan (Statistics at UC Berkeley) attributes the Box quote as a contributing cause of bad statistical models and dismisses it as “complete nonsense.” He goes on to write:
The foundation of statistics (…) could not have been to arbitrarily select a “convenient” statistical model. However, that is precisely what most statisticians blithely do, proudly referring to the quote, “All models are wrong, but some are useful.” Due to this, models that are so unrealistic that they are indexed by a finite dimensional parameter are still the status quo, even though everybody agrees they are known to be false.
As a solution, Van der Laan calls statisticians to stop using Box’s quote, and make a commitment to take data, statistics, and the scientific method seriously. He calls on statisticians to spend time learning how data in a given data set were generated and commit to developing realistic statistical models using machine learning and data-adaptive estimation techniques over more traditional parametric models.
This article has responses from statisticians Michael Lavine and Christopher Tong, as well as a response to the responses from the original author. The two refuting statisticians point to examples where models are known to be wrong but are often employed because they are useful, and fit for a given problem. Their examples include the three different models of light found in the field of optics (geometrical optics, physical optics, and quantum optics; all three models represent light differently, are “wrong” in some sense, and are still employed today), and the (nearly) linear relationship between the log of carbon flux and soil temperature found in data collected in the Harvard Forest.
In turn, Van der Laan responds to these examples and other critiques of his article, specifically his concept of finding a “true” model. The response letters are definitely worth a read if you are interested. This represents an active area of debate in the fields of statistics and data science.
But Some Models Are Useful
Despite the limitations of models, many models can be very useful. Because they are simplified, models are often helpful in understanding a certain component or facet of a system.
In the context of data science, machine learning and statistical models can be useful to estimate (predict) unknown values. In many contexts, if the model’s assumptions hold up, an uncertain estimate provided by a strong statistical model can still be very helpful for making decisions.
The second, less-cited half of George Box’s wisdom is this:
“The practical question is how wrong do (models) have to be to not be useful.” – George Box
Let's take another look at our linear regression example:
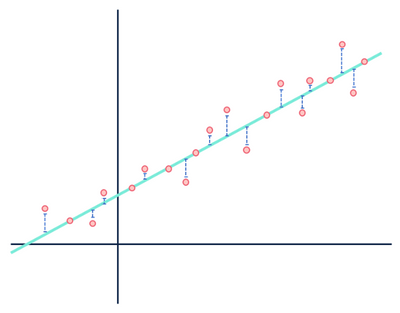
Mostly I spent too much time on this image to use it just once.
Now, let’s take a look at another theoretical linear regression model fit to a different data set.
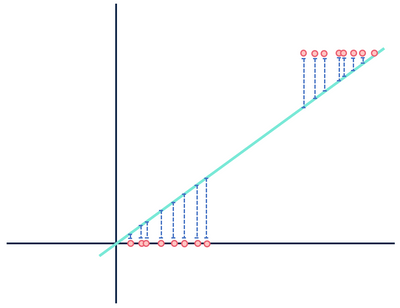
Pay no mind to the distances… wait this can’t be right.
Both figures show error, but one data set demonstrates a clearly linear relationship while the other is logistic. Both models are “wrong,” but one clearly captures a real relationship between variables, while the other does not, making one useful and one useless. Discarding the distances in blue as noise is reasonable if the data does have a linear relationship, but this assumption falls apart when the relationship has a different functional shape than your selected model.
Making Good Models
The fact that models are wrong or limited in the scope of what they represent might seem obvious to many people that work with models, but unfortunately, many people do not realize it or think about it much. That is why I feel it is important to keep the words of George Box in mind when developing a model. It should not be used as an excuse to build bad models.
For further reading, Steele has some great class notes: Does the Model Make Sense? and Does the Model Make Sense? Part II: Exploiting Sufficiency. Another great resource is the paper ‘All models are wrong…’: an introduction to model uncertainty from a model selection workshop held in 2011 in Groningen.
Another interesting read is When All Models are Wrong from Issues in Science and Technology, which calls on Box's words as a call for more stringent transparency in scientific and statistical models.
The important thing to take away from all of this is to make sure you understand what aspects of your data are captured by your model, and what aspects are not. It is critical to check your assumptions and starting points. As a statistician or data scientist, it is your responsibility to produce rigorous models as well as know their limitations. Always report your uncertainty as well as the scope of your model. With that in mind, you will be able to make models that, while possibly wrong, can certainly be useful.
Original. Reposted with permission.
Bio: A geographer by training and a data geek at heart, Sydney strongly believes that data and knowledge are most valuable when they can be clearly communicated and understood. In her current role as a Sr. Data Science Content Engineer, she gets to spend her days doing what she loves best; transforming technical knowledge and research into engaging, creative, and fun content for the Alteryx Community.
Related: