
How to Select Rows and Columns in Pandas Using [ ], .loc, iloc, .at and .iat
Subset selection is one of the most frequently performed tasks while manipulating data. Pandas provides different ways to efficiently select subsets of data from your DataFrame.
![How to Select Rows and Columns in Pandas using [ ], .loc, iloc, .at and .iat](https://www.kdnuggets.com/wp-content/uploads/panda-barbell.jpg)
Image by catalyststuff on Freepik
You can download the Jupyter notebook of this tutorial here.
In this blog post, I will show you how to select subsets of data in Pandas using [ ], .loc, .iloc, .at, and .iat. I will be using the wine quality dataset hosted on the UCI website. This data record 11 chemical properties (such as the concentrations of sugar, citric acid, alcohol, pH, etc.) of thousands of red and white wines from northern Portugal, as well as the quality of the wines, recorded on a scale from 1 to 10. We will only look at the data for red wine.
First, I import the Pandas library, and read the dataset into a DataFrame.

Here are the first 5 rows of the DataFrame:
wine_df.head()

I rename the columns to make it easier for me call the column names for future operations.
wine_df.columns = ['fixed_acidity', 'volatile_acidity', 'citric_acid',
'residual_sugar', 'chlorides', 'free_sulfur_dioxide',
'total_sulfur_dioxide','density','pH','sulphates',
'alcohol', 'quality']
Different Ways to Select Columns
Selecting a single column
To select the first column 'fixed_acidity', you can pass the column name as a string to the indexing operator.
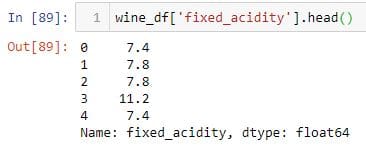
You can perform the same task using the dot operator.

Selecting multiple columns
To select multiple columns, you can pass a list of column names to the indexing operator.
wine_four = wine_df[['fixed_acidity', 'volatile_acidity','citric_acid', 'residual_sugar']]
Alternatively, you can assign all your columns to a list variable and pass that variable to the indexing operator.
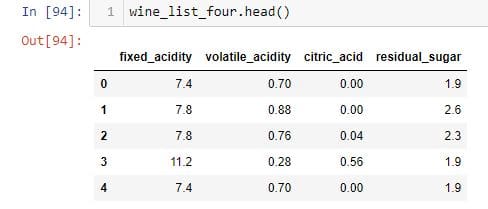
cols = ['fixed_acidity', 'volatile_acidity','citric_acid', 'residual_sugar']
wine_list_four = wine_four[cols]
Selecting columns using "select_dtypes" and "filter" methods
To select columns using select_dtypes method, you should first find out the number of columns for each data types.
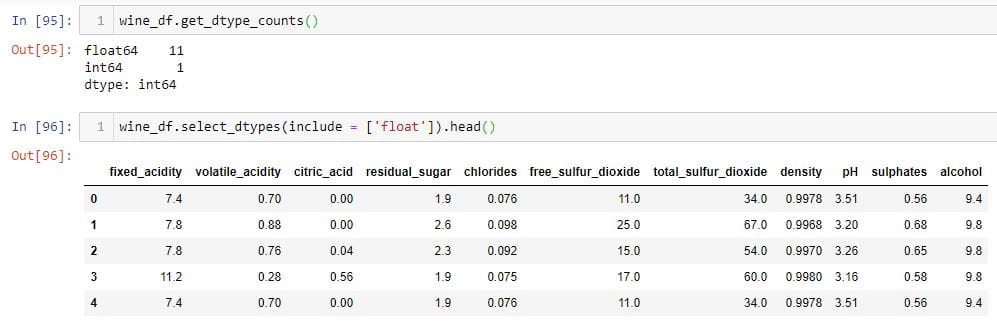
In this example, there are 11 columns that are float and one column that is an integer. To select only the float columns, use wine_df.select_dtypes(include = ['float']). The select_dtypes method takes in a list of datatypes in its include parameter. The list values can be a string or a Python object.
You can also use the filter method to select columns based on the column names or index labels.
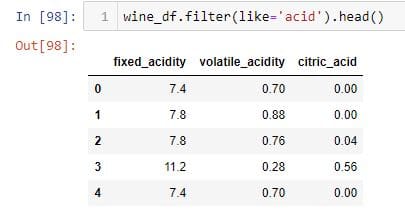
In the above example, the filter method returns columns that contain the exact string 'acid'. The like parameter takes a string as an input and returns columns that has the string.
You can use regular expressions with the regex parameter in the filter method.
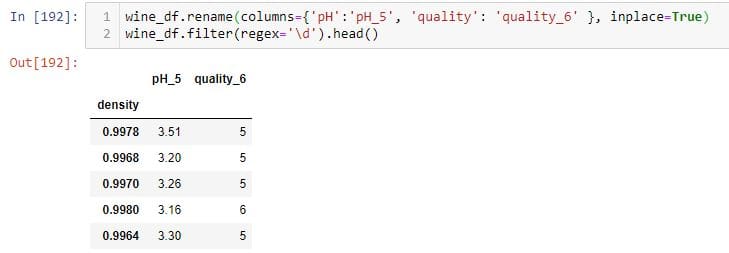
Here, I first rename the ph and quality columns. Then, I pass the regex parameter to the filter method to find all the columns that has a number.
Changing the Order of Columns
I would like to change the order of my columns.

wine_df.columns shows all the column names. I organize the names of my columns into three list variables, and concatenate all these variables to get the final column order.
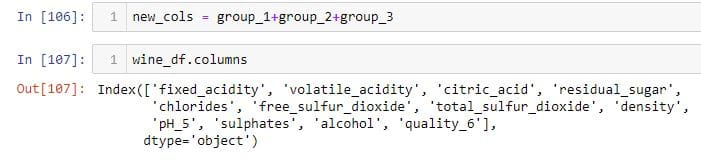
I use the Set module to check if new_cols contains all the columns from the original.
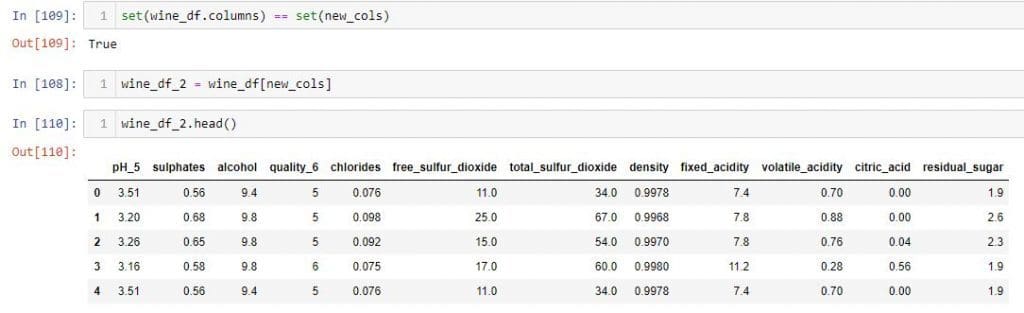
Then, I pass the new_cols variable to the indexing operator and store the resulting DataFrame in a variable "wine_df_2" . Now, the wine_df_2 DataFrame has the columns in the order that I wanted.
Different Ways to Select Rows
Selecting rows using .iloc and loc
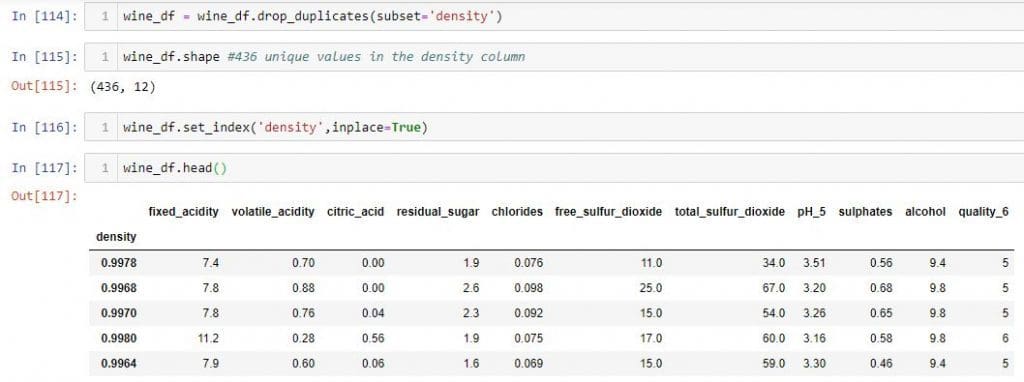
Now, let's see how to use .iloc and loc for selecting rows from our DataFrame. To illustrate this concept better, I remove all the duplicate rows from the "density" column and change the index of wine_df DataFrame to 'density'.
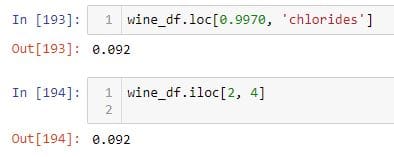
To select the third row in wine_df DataFrame, I pass number 2 to the .iloc indexer.
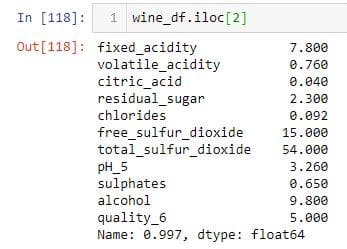
To do the same thing, I use the .loc indexer.
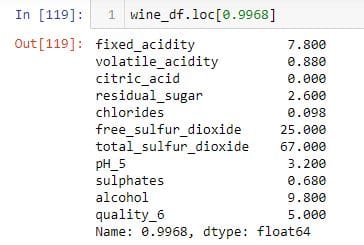
To select rows with different index positions, I pass a list to the .iloc indexer.

I pass a list of density values to the .iloc indexer to reproduce the above DataFrame.

You can use slicing to select multiple rows . This is similar to slicing a list in Python.

The above operation selects rows 2, 3 and 4.
You can perform the same thing using loc.
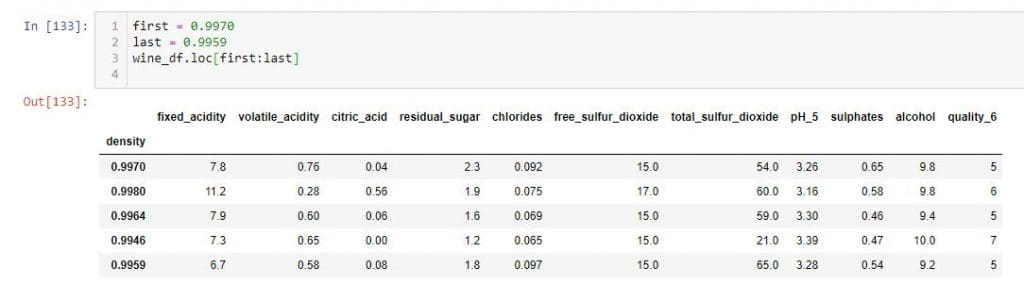
Here, I am selecting the rows between the indexes 0.9970 and 0.9959.
Selecting Rows and Columns Simultaneously
You have to pass parameters for both row and column inside the .iloc and loc indexers to select rows and columns simultaneously. The rows and column values may be scalar values, lists, slice objects or boolean.
Select all the rows, and 4th, 5th and 7th column:
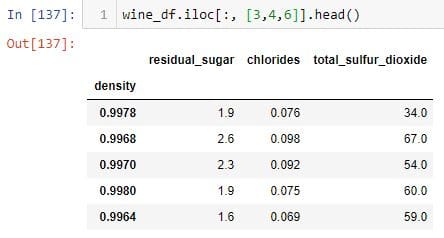
To replicate the above DataFrame, pass the column names as a list to the .loc indexer:
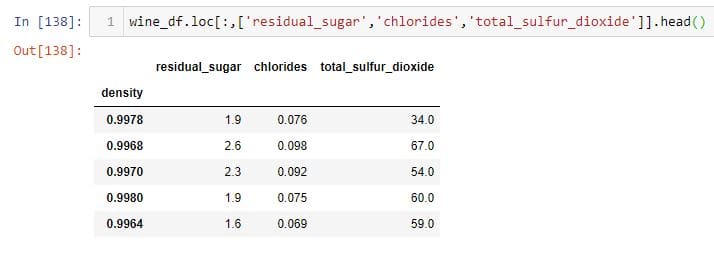
Selecting disjointed rows and columns
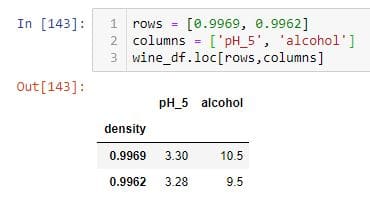
To select a particular number of rows and columns, you can do the following using .iloc.

To select a particular number of rows and columns, you can do the following using .loc.
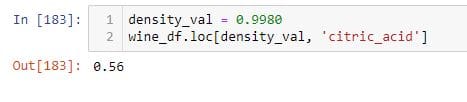
To select a single value from the DataFrame, you can do the following.
You can use slicing to select a particular column.
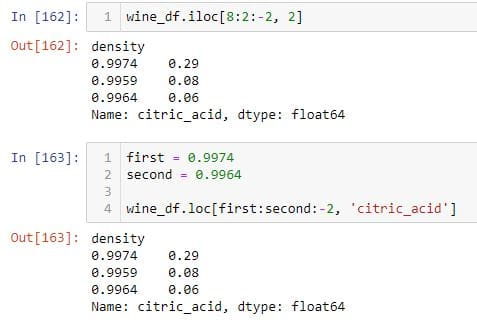
To select rows and columns simultaneously, you need to understand the use of comma in the square brackets. The parameters to the left of the comma always selects rows based on the row index, and parameters to the right of the comma always selects columns based on the column index.
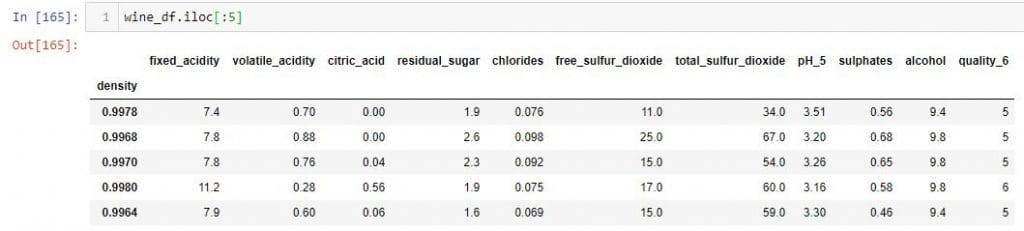
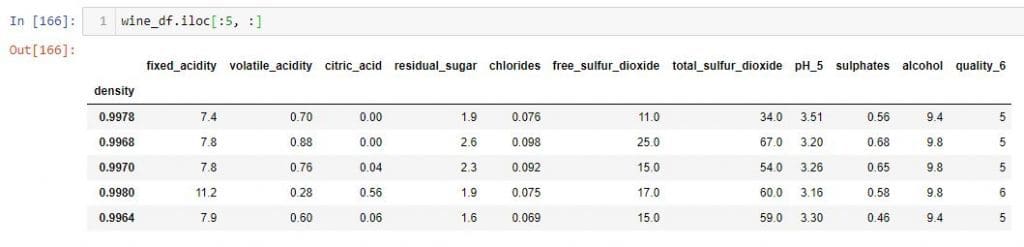
If you want to select a set of rows and all the columns, you don't need to use a colon following a comma.
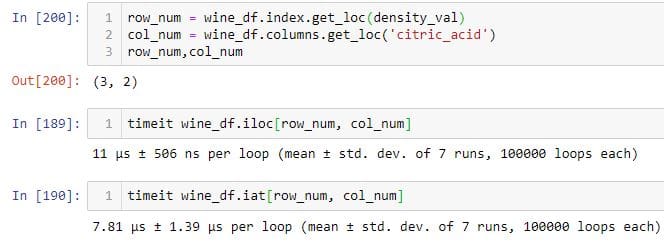
Selecting rows and columns using "get_loc" and "index" methods
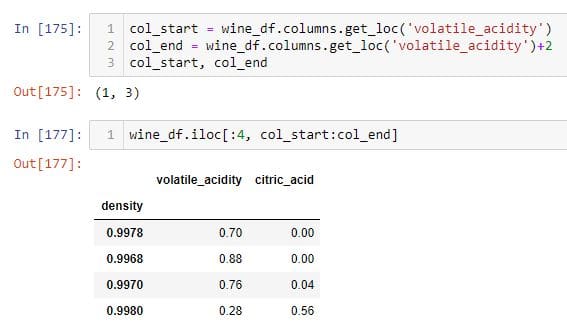
In the above example, I use the get_loc method to find the integer position of the column 'volatile_acidity' and assign it to the variable col_start. Again, I use the get_loc method to find the integer position of the column that is 2 integer values more than 'volatile_acidity' column, and assign it to the variable called col_end.I then use the iloc method to select the first 4 rows, and col_start and col_endcolumns. If you pass an index label to the get_loc method, it returns its integer location.
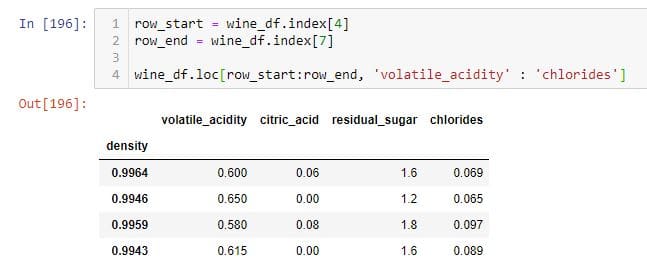
You can perform a very similar operation using .loc. The following shows how to select the rows from 3 to 7, along with columns "volatile_acidity" to "chlorides".
Subselection using .iat and at
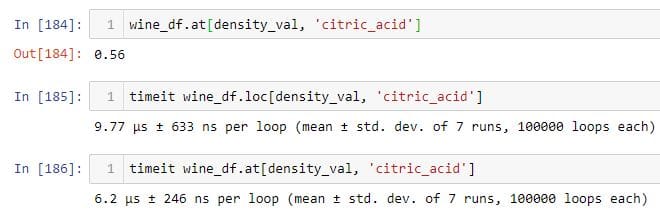
Indexers, .iat and .at, are much more faster than .iloc and .loc for selecting a single element from a DataFrame.
I will be writing more tutorials on manipulating data using Pandas. Stay Tuned!
References