Neural Code Search: How Facebook Uses Neural Networks to Help Developers Search for Code Snippets
Developers are always searching for answers to questions about their code. But how do they ask the right questions? Facebook is creating new NLP neural networks to help search code repositories that may advance information retrieval algorithms.

Google and StackOverflow are every developer’s best friend these days. When working on a specific project, developers constantly resort to external sources of information to find solutions or code snippets to a given problem. However, the search resolution is mostly based on metadata and not in the information provided by the code itself. For instance, if a developer posts a code snippet to StackOverflow, it will typically include a description and tags that help to index it for future searches. This approach relies on the accuracy of that metadata in order to render accurate search results, but it also misses information that can be inferred directly from the code. To address this limitation, a team from Facebook AI Research (FAIR) has been working on an approach to use natural language processing (NLP) and information retrieval (IR) to infer search-relevant information directly from the source code text.
The first materialization of the FAIR team efforts is a tool called Neural Code Search (NCS) which accepts a natural language query and returns results inferred directly from the code corpus. The techniques behind NCS were summarized in two research papers recently published:
- NCS: This paper describes a technique that uses an unsupervised model that combines NLP and IR techniques.
- UNIF: This paper proposes an extension of NCS that uses a supervised neural network model to improve performance when good supervision data is available for training.
The principles behind both techniques, NCS and UNIF, is relatively similar. Both methods rely on vector representations of code snippets, which can be used to train a model such as semantically similar code snippets, and queries are close together in the vector space. This technique is able to answer natural language queries directly using the code snippets corpus without relying on external metadata. Although both techniques (NCS, UNIF) are relatively similar, UNIF extends NCS with a supervised model to create even more accurate answers to NLP queries.
NCS
The core principle behind is to use embeddings to generate a vector representation from a code corpus in a way in which similar code snippets are close to each other in the vector space. In the example below, there are two distinct method bodies that both pertain to closing or hiding the Android soft keyboard (the first question above). Since they share similar semantic meanings, even if they do not share the exact same lines of code, they are represented by points in the vector space that are close to each other. NCS uses method-level granularity to embed every code snippet in the vector space.
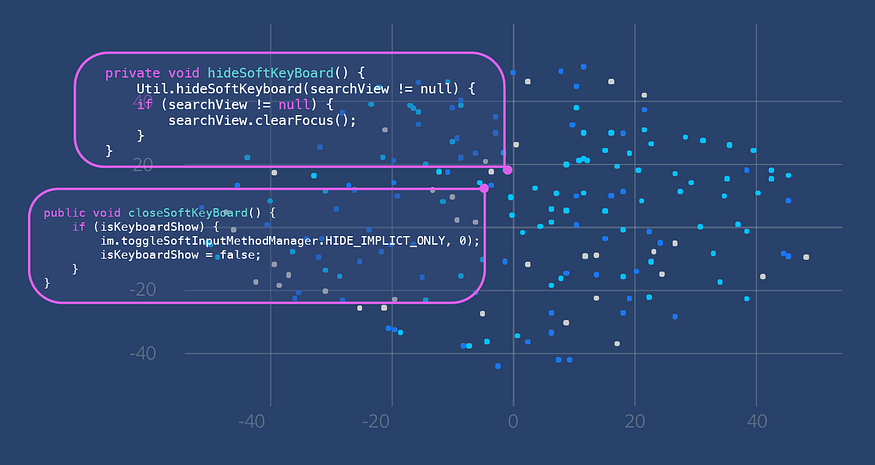
The process of creating the vector representation has three main steps:
1) Extracting Words
2) Build Word Embeddings
3) Build Document Embeddings
4)Natural Language Search Retrieval

Give a specific code snippet, NCS extracts different syntactic sections such as method names, method invocations, enums, string literals, and comments. Those artifacts are then tokenized using standards English conventions. For each document in the input corpus, NCS tokenizes the source code in a manner that can learn an embedding for each word. After this step, the list of words we extracted for each method body resembles a natural language document.
After the word extraction, NCS proceeds to build the word embeddings using the FastText framework. During this process, FastText computes vector representations using a two-layer dense neural network that can be trained unsupervised on a large corpus. More specifically, NCS uses the skip-gram model, where the embedding for a target token is used to predict embeddings of context tokens within a fixed window size.
The final step of this phase is to express the general intent of a method body using the extracted word embeddings. NCS achieves that by calculating a weighted average of the word embedding vectors for the set of words in the method body. The result of this formula is known as a document embedding and is used to create an index of each method in the body for effective search retrieval.
Using a vector representation as a starting point, NCS can now try to answer natural language queries related to code snippets. Given a natural language query, NCS follows a similar tokenization process using the FastText framework. Using the same FastText embedding matrix, NCS averages the vector representations of words to create a document embedding for the query sentence; out-of-vocab words are dropped. NCS then uses a standard similarity search algorithm, FAISS, to find the document vectors with closest cosine distance to the query.

UNIF
As an unsupervised technique, NCS has the advantage that it can build knowledge directly from the code corpus in a quick and easy manner. However, one of the main limitations of NCS is that the model implicitly assumes that the words in the query come from the same domain as the words extracted from source code, as the queries and the code snippets are both mapped to the same vector space. However, there are plenty of examples in which a code corpus does not convey any relevant semantic information. Take the example below of a code snippet that obtains available blocks in a memory space. Just by generating the word embeddings in an unsupervised way, NCS won’t be able to match relevant queries such as “Get free space on internal memory”.
File path = Environment.getDataDirectory(); StatFs stat = new StatFs(path.getPath()); long blockSize = stat.getBlockSize(); long availableBlocks = stat.getAvailableBlocks(); return Formatter.formatFileSize(this, availableBlocks * blockSize);
UNIF is a supervised extension to NCS that attempts to bridge the gap between natural language words and source code words. Essentially, UNIF uses supervised learning to modify the initial token embedding matrix T and produce two embedding matrices, Tc and Tq, for code and query tokens, respectively. We also replace the TF-IDF weighing of code token embeddings with a learned attention-based weighing scheme. This twist essentially accounts for some of the semantic mismatches in code corpus.

NCS and UNIF in Action
The FAIR team evaluates both NCS and UNIF against state-of-the-art information retrieval models. Using a starting dataset of StackOverflow questions, NCS was able to outperform the popular BM25 model across a diverse series of tasks.

Similarly, adding the UNIF extension showed incremental improvements in the NCS performance.

Both NCS and UNIF present a clever and yet simple-to-implement approach for information retrieval. Starting with code search is a trivial way to deliver immediate value, but the ideas behind NCS and UNIF are applicable to many neural search and information retrieval scenarios.
Original. Reposted with permission.
Related: