Introducing AI Explainability 360: A New Toolkit to Help You Understand what Machine Learning Models are Doing
Recently, AI researchers from IBM open sourced AI Explainability 360, a new toolkit of state-of-the-art algorithms that support the interpretability and explainability of machine learning models.

Interpretability is one of the most difficult challenges in modern machine learning solutions. While building sophisticated machine learning models is getting easier, understanding how models develop knowledge and arrive to conclusions remains a very difficult challenge. Typically, the more accurate the models the harder they are to interpret. Recently, AI researchers from IBM open sourced AI Explainability 360, a new toolkit of state-of-the-art algorithms that support the interpretability and explainability of machine learning models.
The release of AI Explainability 360 is the first practical implementation of ideas outlined in dozens of research papers in the last few years. In the same way traditional software applications incorporate instrumentation code to help its runtime monitoring, machine learning models need to add interpretability techniques to facilitate debugging, troubleshooting and versioning. However, interpreting machine learning models is a multiple of complexity higher than traditional software applications. For starters, we need have very little understanding of what makes a machine learning model interpretable.
The Building Blocks of Interpretability
A few months ago, researchers from Google published a very comprehensive paper in which they outlined the core components of interpretability. The paper presents four fundamental challenges to make a model interpretable:
- Understanding what Hidden Layers Do: The bulk of the knowledge in a deep learning model is formed in the hidden layers. Understanding the functionality of the different hidden layers at a macro level is essential to be able to interpret a deep learning model.
- Understanding what Hidden Layers Do: The bulk of the knowledge in a deep learning model is formed in the hidden layers. Understanding the functionality of the different hidden layers at a macro level is essential to be able to interpret a deep learning model.
- Understanding How Nodes are Activated: The key to interpretability is not to understand the functionality of individual neurons in a network but rather groups of interconnected neurons that fire together in the same spatial location. Segmenting a network by groups of interconnected neurons will provide a simpler level of abstraction to understand its functionality.
- Understanding How Concepts are Formed: Understanding how deep neural network forms individual concepts that can then be assembled into the final output is another key building block of interpretability.
The other aspect to realize is that the interpretability of AI modes decreases as their sophistication increases. Do you care about obtaining the best results or do you care about understanding how those results were produced? That’s a essence of the interpretability vs. accuracy friction that is at the center of every machine learning scenario. Many deep learning techniques are complex in nature and, although they result very accurate in many scenarios, they can become incredibly difficult to interpret.
To address the challenges of explainability, machine learning models need to start incorporating interpretable building blocks a first class citizen. That’s the goal of IBM’s new toolkit.
AI Explainability 360
AI Explainability 360 is an open source toolkit for streamlining the implementation of interpretable machine learning models. The toolkit includes a series of interpretability algorithms that reflect state-of-the-art research in this topic as well as an intuitive user interface that helps understand machine learning models from different perspectives. One of the main contributions of the AI Explainability 360 is that it doesn’t rely on a single form of interpretation for a machine learning model. In the same way that humans rely on rich, expressive explanations to interpret a specific outcome, the explainability of machine learning models varies depending on personas and context involved. AI Explainability 360, produces different explanations for different roles such as data scientists or business stake holders.
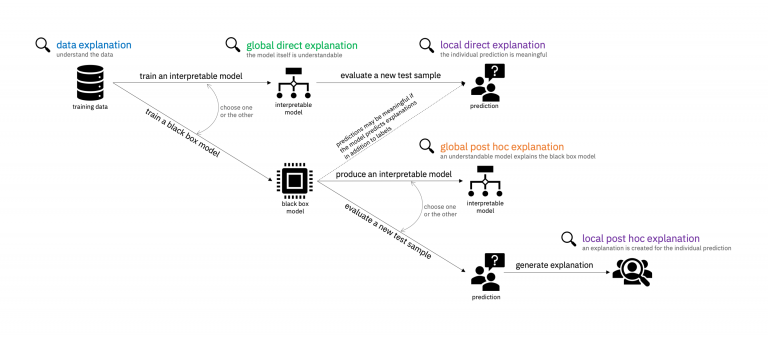
The explanations generated by AI Explainability 360 can be divided in two main groups depending on whether they are based on the data or the models.
- Data: Understanding the characteristics of a dataset is very often the shortest path to explainability. This is specially true in supervised learning algorithms that rely heavily on datasets in order to build relevant knowledge. Sometimes the features in a given dataset are meaningful to consumers, but other times they are entangled, i.e. multiple meaningful attributes are combined together in a single feature. AI Explainability 360 includes several algorithms that focus on data interpretability.
- Model: The interpretation of models is the key building block of any machine learning explainability. There are several ways to make a machine learning model comprehensible to consumers. The first distinction is direct interpretability vs. post hoc explanation. Directly interpretable models are model formats such as decision trees, Boolean rule sets, and generalized additive models, that are fairly easily understood by people and learned straight from the training data. Post hoc explanation methods first train a black box model and then build another explanation model on top of the black box model. The second distinction is global vs. local explanation. Global explanations are for entire models whereas local explanations are for single sample points.
The distinction between global interpretable models, global and local post hoc explanations is one of the key contributions of AI Explainability 360. Typically, global interpretable models are better suited for scenarios that need a complete and discrete interpretation paths of the models. Many of those scenarios include areas such as safety, reliability or compliance. Global post hoc explanations are useful for decision maker personas that are being supported by the machine learning model. Physicians, judges, and loan officers develop an overall understanding of how the model works, but there is necessarily a gap between the black box model and the explanation. Local post hoc explanations are relevant to induvial personas such as patients, defendants of applicants that are affected by the outcome of a model and need to understand its interpretation from a their very specific viewpoint.
Developers can start using AI Explainability 360 by incorporating the interpretable components using the APIs included in the toolkit. Additionally, AI Explainability 360 includes a series of demos and tutorials that can help developers get started relatively quickly. Finally, the toolkit provides a very simple user interface that can be used to get started with the concepts of machine learning interpretability.
Interpretability is one of the most important building blocks of modern machine learning applications. AI Explainability 360 provides one of the most complete stacks to simplify the interpretability of machine learning programs without having to become an expert in this particular area of research. It is likely that we will see some of the ideas behind AI Explainability 360 being incorporated into mainstream deep learning frameworks and platforms.
Original. Reposted with permission.
Related:
- Two Major Difficulties in AI and One Applied Solution
- 6 Key Concepts in Andrew Ng’s “Machine Learning Yearning”
- How Creating an AI Study Group Boosted My Skills and Got Me a Job