The 5 Sampling Algorithms every Data Scientist need to know
Algorithms are at the core of data science and sampling is a critical technical that can make or break a project. Learn more about the most common sampling techniques used, so you can select the best approach while working with your data.
Data Science is the study of algorithms.
I grapple through with many algorithms on a day to day basis, so I thought of listing some of the most common and most used algorithms one will end up using in this new DS Algorithm series.
Simple Random Sampling
Say you want to select a subset of a population in which each member of the subset has an equal probability of being chosen.
Below we select 100 sample points from a dataset.
sample_df = df.sample(100)
Stratified Sampling

Assume that we need to estimate the average number of votes for each candidate in an election. Assume that the country has 3 towns:
Town A has 1 million factory workers,
Town B has 2 million workers, and
Town C has 3 million retirees.
We can choose to get a random sample of size 60 over the entire population, but there is some chance that the random sample turns out to be not well balanced across these towns and hence is biased causing a significant error in estimation.
Instead, if we choose to take a random sample of 10, 20 and 30 from Town A, B and C respectively then we can produce a smaller error in estimation for the same total size of the sample.
You can do something like this pretty easily with Python:
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y, test_size=0.25)
Reservoir Sampling

I love this problem statement:
Say you have a stream of items of large and unknown length that we can only iterate over once.
Create an algorithm that randomly chooses an item from this stream such that each item is equally likely to be selected.
How can we do that?
Let us assume we have to sample 5 objects out of an infinite stream such that each element has an equal probability of getting selected.
import randomdef generator(max): number = 1 while number < max: number += 1 yield number# Create as stream generator stream = generator(10000)# Doing Reservoir Sampling from the stream k=5 reservoir = [] for i, element in enumerate(stream): if i+1<= k: reservoir.append(element) else: probability = k/(i+1) if random.random() < probability: # Select item in stream and remove one of the k items already selected reservoir[random.choice(range(0,k))] = elementprint(reservoir) ------------------------------------ [1369, 4108, 9986, 828, 5589]
It can be mathematically proved that in the sample each element has the same probability of getting selected from the stream.
How?
It always helps to think of a smaller problem when it comes to mathematics.
So, let us think of a stream of only 3 items, and we have to keep 2 of them.
We see the first item, and we hold it in the list as our reservoir has space. We see the second item, and we hold it in the list as our reservoir has space.
We see the third item. Here is where things get interesting. We choose the third item to be in the list with probability 2/3.
Let us now see the probability of first item getting selected:
The probability of removing the first item is the probability of element 3 getting selected multiplied by the probability of Element 1 getting randomly chosen as the replacement candidate from the 2 elements in the reservoir. That probability is:
2/3*1/2 = 1/3
Thus the probability of 1 getting selected is:
1–1/3 = 2/3
We can have the exact same argument for the Second Element and we can extend it for many elements.
Thus each item has the same probability of getting selected: 2/3 or in general k/n.
Random Undersampling and Oversampling
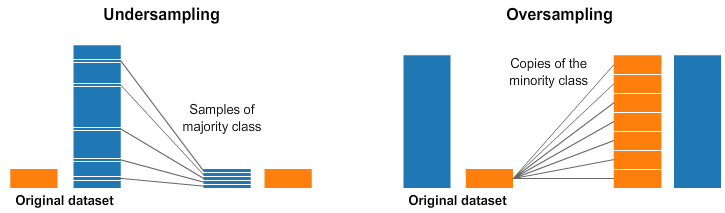
It is too often that we encounter an imbalanced dataset.
A widely adopted technique for dealing with highly imbalanced datasets is called resampling. It consists of removing samples from the majority class (under-sampling) and/or adding more examples from the minority class (over-sampling).
Let us first create some example imbalanced data.
from sklearn.datasets import make_classificationX, y = make_classification( n_classes=2, class_sep=1.5, weights=[0.9, 0.1], n_informative=3, n_redundant=1, flip_y=0, n_features=20, n_clusters_per_class=1, n_samples=100, random_state=10 )X = pd.DataFrame(X) X['target'] = y
We can now do random oversampling and undersampling using:
num_0 = len(X[X['target']==0]) num_1 = len(X[X['target']==1]) print(num_0,num_1)# random undersampleundersampled_data = pd.concat([ X[X['target']==0].sample(num_1) , X[X['target']==1] ]) print(len(undersampled_data))# random oversampleoversampled_data = pd.concat([ X[X['target']==0] , X[X['target']==1].sample(num_0, replace=True) ]) print(len(oversampled_data))------------------------------------------------------------ OUTPUT: 90 10 20 180
Undersampling and Oversampling using imbalanced-learn
The Python package imbalanced-learn (imblearn) tackles the curse of imbalanced datasets.
It provides a variety of methods to undersample and oversample.
a. Undersampling using Tomek Links:
One such method it provides is called Tomek Links. Tomek links are pairs of examples of opposite classes in close vicinity.
In this algorithm, we end up removing the majority element from the Tomek link which provides a better decision boundary for a classifier.

from imblearn.under_sampling import TomekLinks tl = TomekLinks(return_indices=True, ratio='majority') X_tl, y_tl, id_tl = tl.fit_sample(X, y)
b. Oversampling using SMOTE:
In SMOTE (Synthetic Minority Oversampling Technique) we synthesize elements for the minority class, in the vicinity of already existing elements.
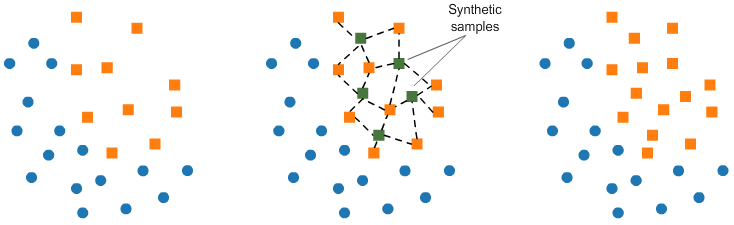
from imblearn.over_sampling import SMOTE smote = SMOTE(ratio='minority') X_sm, y_sm = smote.fit_sample(X, y)
There are a variety of other methods in the imblearn package for both undersampling (Cluster Centroids, NearMiss, etc.) and oversampling (ADASYN and bSMOTE) that you can check out.
Conclusion
Algorithms are the lifeblood of data science.
Sampling is an important topic in data science, and we really don’t talk about it as much as we should.
A good sampling strategy sometimes could pull the whole project forward. A bad sampling strategy could give us incorrect results. So one should be careful while selecting a sampling strategy.
So use sampling, be it at work or bars.
Original. Reposted with permission.
Bio: Rahul Agarwal's professional goal is to work on business and data science, bridging the transitional gap between these two worlds. Versed in finding clever solutions to complex problems in a variety of different realms.
Related: