A Concise Explanation of Learning Algorithms with the Mitchell Paradigm
A single quote from Tom Mitchell can shed light on both the abstract concept and concrete implementations of machine learning algorithms.
A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E.
- Tom Mitchell, "Machine Learning"1
Tom Mitchell's quote is well-known and time-tested in the world of machine learning, having first appeared in his 1997 book. The sentence has been influential on me, personally, as I have referred to it numerous times over the years and referenced it in my Master's thesis. The quote also features prominently in Chapter 5 of the much more recent and authoritative "Deep Learning" by Goodfellow, Bengio & Courville, serving as the jumping off point for the book's explanation of learning algorithms.
While inherently abstract, the variables E, T, and P can be mapped to machine learning algorithms and their learning processes in order to help solidify one's understanding of learning algorithms abstractly and even more concretely. Let's have a look at how we can get quite a bit of mileage out of such a succinct few words.
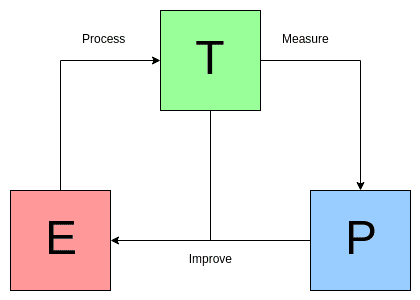
Figure 1. The Mitchell Paradigm, visualized.
Machine Learning Tasks are usually described in terms of how the machine learning system should process an example.
- Ian Goodfellow, Yoshua Bengio & Aaron Courville, "Deep Learning"2
First off, let's keep in mind that our focus here is on the machine learning algorithms, and the process of learning. This means we must differentiate between our task and the learning process, and understand how they relate.
If, for instance, we want to classify images, it is important to distinguish between performing our task (image classification) and learning how to perform our task, which can be described as "our means of attaining the ability to perform the task"2. A single image would be the example which our machine learning system would process, relating back to the above quote.
Other examples of tasks would be regression, translation, anomaly detection, and density estimation.
To evaluate the abilities of a machine learning algorithm, we must design a quantitative measure of its performance.
- Ian Goodfellow, Yoshua Bengio & Aaron Courville, "Deep Learning"2
During the learning process, we must determine if our example has led us further toward our ultimate task goal; we need to measure its performance. In our example, in other words, has what we have learned from the previous processed example(s) allowed us to better classify images?
Fortunately, what we want to know in this case can be quantified and easily measured: accuracy or, inversely, error rate, in the case of classification. Sometimes knowing what to measure is difficult; knowing what to measure but not being able to measure it is a potential problem as well.
In order to best measure performance, we are generally interested in assessing on data which has not previously been seen by our learning algorithm, which is where the concept of having training and testing datasets comes into play.
Machine learning algorithms can be broadly categorised as unsupervised or supervised by what kind of experience they are allowed to have during the learning process.
- Ian Goodfellow, Yoshua Bengio & Aaron Courville, "Deep Learning"2
The concept of experience is a bit more abstract than the others, and is more difficult to point to something concrete (e.g. particular lines of code in an implemented model) which embodies it.
Broadly, experience relates to how a learning algorithm experiences data from which it learns. The easiest angle from which we can describe such experience is whether the data is labeled (supervised learning) or not (unsupervised learning). In this sense, experience is all about how the process of learning takes place, as in: is this a form of self-learning, or is it a guided process?
We can also more fully describe the dataset being learned from as part of the experience. Generally, data is packed into matrices, which are collections of examples. Examples, in turn, are collections of features, which describe a particular example. This feature set may or may not be supplemented with a label (or target), dependent on whether it will be used for supervised or unsupervised learning.
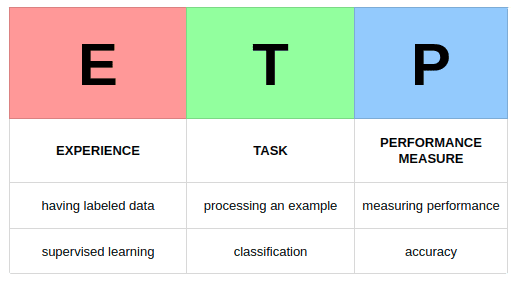
Figure 2. Using the Mitchell Paradigm to explain an image classification task.
For more on this topic, you can find the referenced books below freely available online.
References:
- Machine Learning, Tom Mitchell, McGraw Hill, 1997.
- Deep Learning, Ian Goodfellow, Yoshua Bengio & Aaron Courville, MIT Press, 2016.
Related:
- The Keras 4 Step Workflow
- Frameworks for Approaching the Machine Learning Process
- A Framework for Approaching Textual Data Science Tasks