5 Step Guide to Scalable Deep Learning Pipelines with d6tflow
How to turn a typical pytorch script into a scalable d6tflow DAG for faster research & development.
By Norman Niemer, Chief Data Scientist & Samuel Showalter, Technology Consultant
Introduction: Why bother?
Building deep learning models typically involves complex data pipelines as well as a lot of trial and error, tweaking model architecture and parameters whose performance needs to be compared. It is often difficult to keep track of all the experiments, leading at best to confusion and at worst wrong conclusions.
In 4 reasons why your ML code is bad we explored how to organize ML code as DAG workflows to solve that problem. In this guide we will go through a practical case study on turning an existing pytorch script into a scalable deep learning pipeline with d6tflow. The starting point is a pytorch deep recommender model by Facebook and we will go through the 5 steps of migrating the code into a scalable deep learning pipeline. The steps below are written in partial pseudo code to illustrate concepts, the full code is available also, see instructions at the end of the article.
Lets get started!
Step 1: Plan your DAG
To plan your work and help others understand how your pipeline fits together, you want to start by thinking about the data flow, dependencies between tasks and task parameters. This helps you organize your workflow into logical components. You might want to draw a diagram such as this
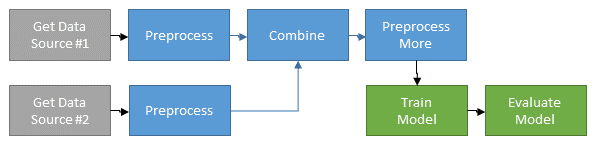
Below is the pytorch model training DAG for FB DLRM. It shows the training task TaskModelTrain with all its dependencies and how the dependencies relate to each other. If you write functional code it is difficult see how your workflow fits together like this.
task = TaskModelTrain()
print(d6tflow.preview(task, clip_params=True))##
## └─--[TaskModelTrain-{'data_generation': 'random'}[more] ([94mPENDING[0m)]
## |--[TaskBuildNetwork-{'data_generation': 'random'}[more] ([94mPENDING[0m)]
## | └─--[TaskGetTrainDataset-{'data_generation': 'random'}[more] ([94mPENDING[0m)]
## |--[TaskGetTrainDataset-{'data_generation': 'random'}[more] ([94mPENDING[0m)]
## └─--[TaskGetTestDataset-{'data_generation': 'random'}[more] ([94mPENDING[0m)]
## None
Step 2: Write Tasks instead of functions
Data science code is typically organized in functions which leads to a lot of problems as explained in 4 reasons why your ML code is bad. Instead you want to write d6tflow tasks. The benefits are that you can:
- chain tasks into a DAG so that required dependencies run automatically
- easily load task input data from dependencies
- easily save task output such as preprocessed data and trained models. That way you don’t accidentally rerun long-running training tasks
- parameterize tasks so they can be intelligently managed (see next step)
- save output to d6tpipe to separate data from code and easily share the data, see Top 10 Coding Mistakes Made by Data Scientists
Here is what the before/after looks like for the FB DLRM code after you convert functional code into d6tflow tasks.
Typical pytorch functional code that does not scale well:
# ***BEFORE***
# see dlrm_s_pytorch.py
def train_model():
data = loadData()
dlrm = DLRM_Net([...])
model = dlrm.train(data)
torch.save({model},'model.pickle')
if __name__ == "__main__":
parser.add_argument("--load-model")
if load_model:
model = torch.load('model.pickle')
else:
model = train_model()Same logic written using scalable d6tflow tasks:
# ***AFTER***
# see flow_tasks.py
class TaskModelTrain(d6tflow.tasks.TaskPickle):
def requires(self): # define dependencies
return {'data': TaskPrepareData(), 'model': TaskBuildNetwork()}
def run(self):
data = self.input()['data'].load() # easily load input data
dlrm = self.input()['model'].load()
model = dlrm.train(data)
self.save(model) # easily save trained model as pickle
if __name__ == "__main__":
if TaskModelTrain().complete(): # load ouput if task was run
model = TaskModelTrain().output().load()
Step 3: Parameterize tasks
To improve model performance, you will try different models, parameters and preprocessing settings. To keep track of all this, you can add parameters to tasks. That way you can:
- keep track which models have been trained with which parameters
- intelligently rerun tasks as parameters change
- help others understand where in workflow parameters are introduced
Below sets up FB DLRM model training task with parameters. Note how you no longer have to manually specify where to save the trained model and data.
# ***BEFORE***
# dlrm_s_pytorch.py
if __name__ == "__main__":
# define model parameters
parser.add_argument("--learning-rate", type=float, default=0.01)
parser.add_argument("--nepochs", type=int, default=1)
# manually specify filename
parser.add_argument("--save-model", type=str, default="")
model = train_model()
torch.save(model, args.save_model)
# ***AFTER***
# see flow_tasks.py
class TaskModelTrain(d6tflow.tasks.TaskPickle):
# define model parameters
learning_rate = luigi.FloatParameter(default = 0.01)
num_epochs = luigi.IntParameter(default = 1)
# filename is determined automatically
def run(self):
data = self.input()['data'].load()
dlrm = self.input()['model'].load()
# use learning_rate param
optimizer = torch.optim.SGD(dlrm.parameters(), lr=self.learning_rate)
# use num_epochs param
while k < self.num_epochs:
optimizer.step()
model = optimizer.get_model()
self.save(model) # automatically save model, seperately for each parameter config
Compare trained models
Now you can use that parameter to easily compare output from different models. Make sure you run the workflow with that parameter before you load task output (see Step #4).
model1 = TaskModelTrain().output().load() # use default num_epochs=1
print_accuracy(model1)
model2 = TaskModelTrain(num_epochs=10).output().load()
print_accuracy(model2)
Inherit parameters
Often you need to have a parameter cascade downstream through the workflow. If you write functional code, you have to keep repeating the parameter in each function. With d6tflow you can inherit parameters so the terminal task can pass the parameter to upstream tasks as needed.
In the FB DLRM workflow, TaskModelTrain inherits parameters from TaskGetTrainDataset. This way you can run TaskModelTrain(mini_batch_size=2) and it will pass the parameter to upstream tasks ie TaskGetTrainDataset and all other tasks that depend on it. In the actual code, note the use of self.clone(TaskName) and @d6tflow.clone_parent.
class TaskGetTrainDataset(d6tflow.tasks.TaskPickle):
mini_batch_size = luigi.FloatParameter(default = 1)
# [...]
@d6tflow.inherit(TaskGetTrainDataset)
class TaskModelTrain(d6tflow.tasks.TaskPickle):
# no need to repeat parameters
pass
Step 4: Run DAG to process data and train model
To kick off data processing and model training, you run the DAG. You only need to run the terminal task which automatically runs all dependencies. Before actually running the DAG, you can preview what will be run. This is especially helpful if you have made any changes to code or data because it will only run the tasks that have changed not the full workflow.
task = TaskModelTrain() # or task = TaskModelTrain(num_epochs=10)
d6tflow.preview(task)
d6tflow.run(task)
Step 5: Evaluate model performance
Now that the workflow has run and all tasks are complete, you can load predictions and other model output to compare and visualize output. Because the tasks knows where each output it saved, you can directly load output from the task instead of having to remember the file paths or variable names. It also makes your code a lot more readable.
model1 = TaskModelTrain().output().load()
print_accuracy(model1)
Compare models
You can easily compare output from different models with different parameters.
model1 = TaskModelTrain().output().load() # use default num_epochs=1
print_accuracy(model1)
model2 = TaskModelTrain(num_epochs=10).output().load()
print_accuracy(model2)
Keep iterating
As you iterate, changing parameters, code and data, you will want to rerun tasks. d6tflow intelligently figures out which tasks need to be rerun which makes iterating very efficient. If you have changed parameters, you don’t need to do anything, it will know what to run automatically. If you have changed code or data, you have to mark the task as incomplete using .invalidate() and d6tflow will figure out the rest.
In the FB DLRM workflow, say for example you changed training data or made changes to the training preprocessing.
TaskGetTrainDataset().invalidate()
# or
d6tflow.run(task, forced=TaskGetTrainDataset())
Full source code
All code is provided at https://github.com/d6tdev/dlrm. It is the same as https://github.com/facebook/dlrm with d6tflow files added:
- flow_run.py: run flow => run this file
- flow_task.py: tasks code
- flow_viz.py: show model output
- flow_cfg.py: default parameters
- dlrm_d6t_pytorch.py: dlrm_data_pytorch.py adopted for d6tflow
Try yourself!
For your next project
In this guide we showed how to build scalable deep learning workflows. We used an existing code base and showed how to turn linear deep learning code into d6tflow DAGs and the benefits of doing so.
For new projects, you can start with a scalable project template from https://github.com/d6t/d6tflow-template. The structure is very similar:
- run.py: run workflow
- task.py: task code
- cfg.py: manage parameters
Norman Niemer is the Chief Data Scientist at a large asset manager where he delivers data-driven investment insights. He holds a MS Financial Engineering from Columbia University and a BS in Banking and Finance from Cass Business School (London).
Samuel Showalter is a Technology Consultant. He is a recent graduate passionate about data science, software development, and the value it can add to personal and professional life. He has worked in very different roles, but all of them share a focus of data management and analysis.
Original. Reposted with permission.
Related:
- Top 10 Coding Mistakes Made by Data Scientists
- 4 Reasons Why Your Machine Learning Code is Probably Bad
- Data Pipelines, Luigi, Airflow: Everything you need to know