Multi-Task Learning – ERNIE 2.0: State-of-the-Art NLP Architecture Intuitively Explained
The tech giant Baidu unveiled its state-of-the-art NLP architecture ERNIE 2.0 earlier this year, which scored significantly higher than XLNet and BERT on all tasks in the GLUE benchmark. This major breakthrough in NLP takes advantage of a new innovation called “Continual Incremental Multi-Task Learning”.
By Michael Ye (Technical Editor: Royal Sequeira; Editor: Susan Shu Chang)
The tech giant Baidu unveiled its state-of-the-art NLP architecture ERNIE 2.0 earlier this year, which scored significantly higher than XLNet and BERT on all tasks in the GLUE benchmark. This major breakthrough in NLP takes advantage of a new innovation called “Continual Incremental Multi-Task Learning”. In this article, we will intuitively explain the concept of Continual Multi-Task Learning, build the ERNIE 2.0 model, and address the concerns regarding ERNIE 2.0’s results.
Prerequisites:
- Neural Networks
- Gradient Descent
- Pre-Training & Fine-Tuning(watch this video: https://bit.ly/2lIADHm)
What is Multi-Task Learning?
To understand Multi-Task Learning, let’s start with a Single-Task Learning example: for simplicity’s sake, imagine a plain feed-forward neural network used in pre-training for NLP (natural language processing). The task is to predict the next word in a sentence.

The input is the string “I like New” and the correct output is the string “York”.
The training process (gradient descent) can be visualized as a ball rolling down a hill: where the terrain is the loss function (otherwise known as cost/error function), and the position of the ball represents the current value of all parameters (weights & biases).
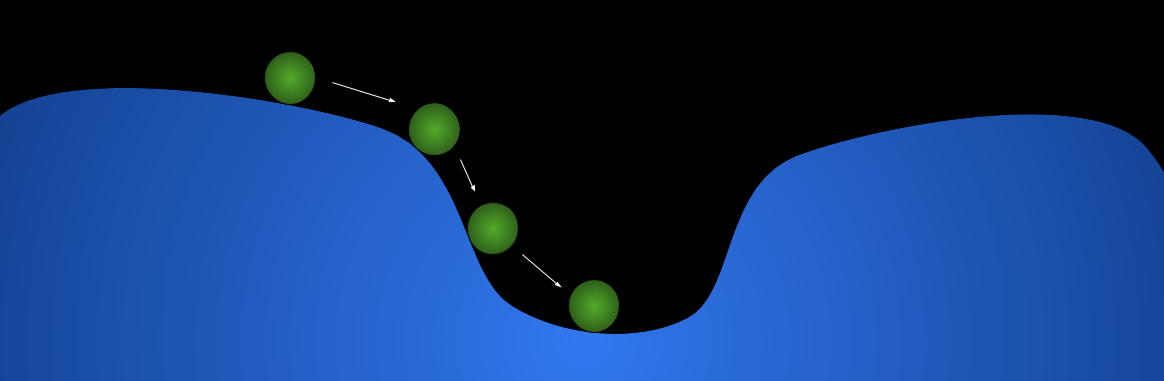
*This diagram only has two dimensions for visualization purposes. *If this metaphor does not make sense to you, please review your understanding of gradient descent: https://bit.ly/2C080IK
Now, what if you wanted the neural network to do multiple tasks? For example, predict the next word in a sentence AND conduct sentiment analysis (predict whether or not the attitude is positive, neutral, or negative. E.g. “You are awesome” classifies as positive).
Well, you can simply add another output!
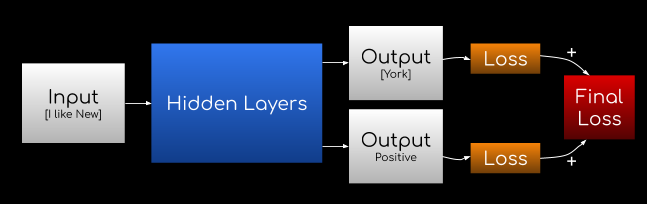
The input is “I like New”, the next word prediction is “York”, and the sentiment prediction is positive.
The loss from both outputs is then summed together and averaged, and the final loss is used to train the network, since now you want to minimize the loss for both tasks.
This time, the training process can be visualized as summing 2 terrains (the 2 loss functions) together to get a new terrain (the final loss function), and then performing gradient descent.

This is the essence of Multi-Task Learning — training one neural network to perform multiple tasks so that the model can develop generalized representation of language rather than constraining itself to one particular task. In fact, ERNIE 2.0 trains its neural network to perform 7 tasks which will be explained in more detail.
Multi-Task Learning is especially useful in natural language processing, as the goal of the pre-training process is to “understand” the language. Similarly, humans also perform multiple tasks when it comes to language understanding.
Now that we have explained multi-task learning, there is still one more key concept in the ERNIE 2.0 architecture, and that is…
Continual Learning
One challenge with training neural networks is the fact that the local minimum is not always the global minimum.
As an example, let’s look at the terrain of our final loss function from the last example - what if we initialized the weights differently, or placed the ball at a different location?

The local minimum this time is far from ideal. To combat this problem and find a better local minimum that’s more likely to be the global minimum, ERNIE 2.0 proposes the concept of Continual Learning.
Instead of training all the tasks at once(Figure 2), you train them sequentially:
- Train using task 1
- Use the parameters from the previous step, and train using tasks 1, 2
- Use the parameters from the previous step, and train using tasks 1, 2, 3,
and so on…
This is inspired by humans, as we learn incrementally instead of multiple tasks at once. And it works because if you get to task 1’s global minimum, when you add the two loss functions together, you’re more likely to get the global minimum compared to if you started with completely random parameters (Figure 3).
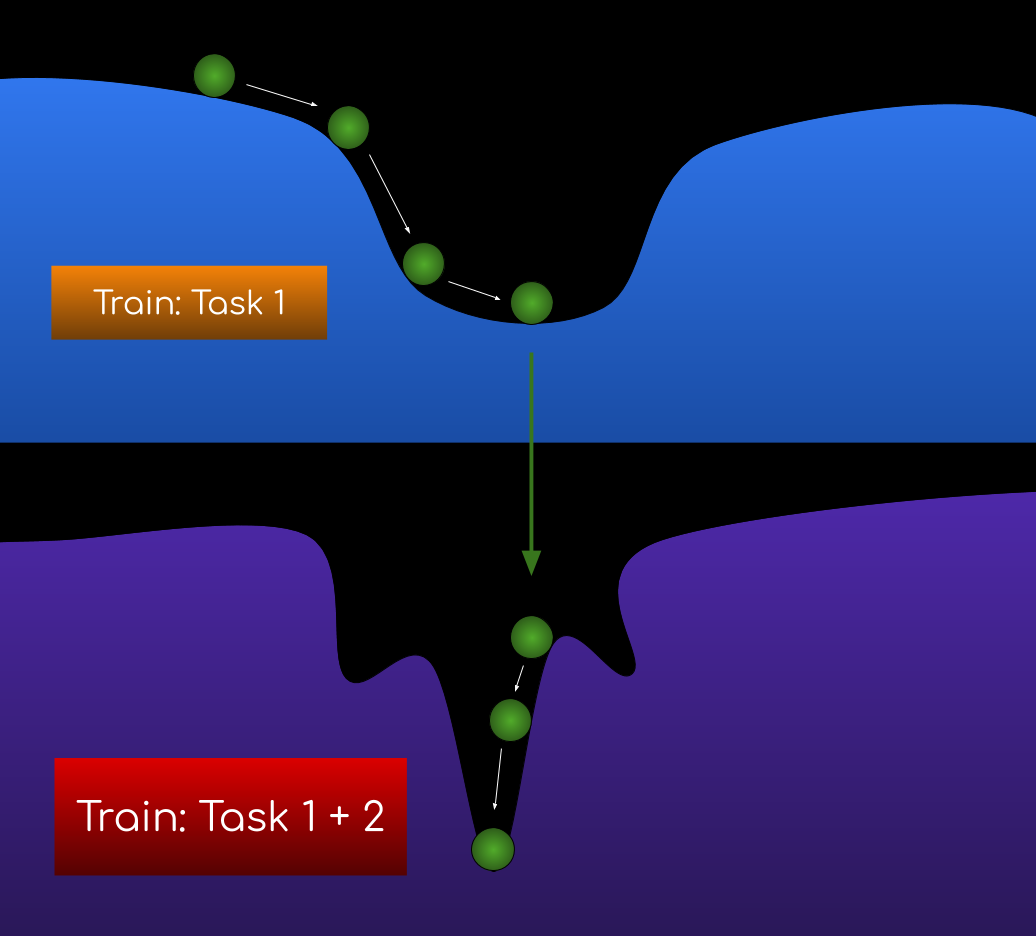
Continual learning also allows you to add new tasks easily — Just add an extra step in the sequence (e.g. Step 3: Train tasks 1, 2, 3). However, keep in mind you must train all previous tasks along with the new task to ensure the loss functions get added together.
Furthermore, in ERNIE 2.0 Adam Optimizer is used to ensure higher chances of locating the global minimum, but that is outside the scope of this article. If you’d like to read more on it, here’s the link: https://arxiv.org/pdf/1412.6980.pdf
ERNIE 2.0 Model
Finally, we can now build the ERNIE 2.0 model!
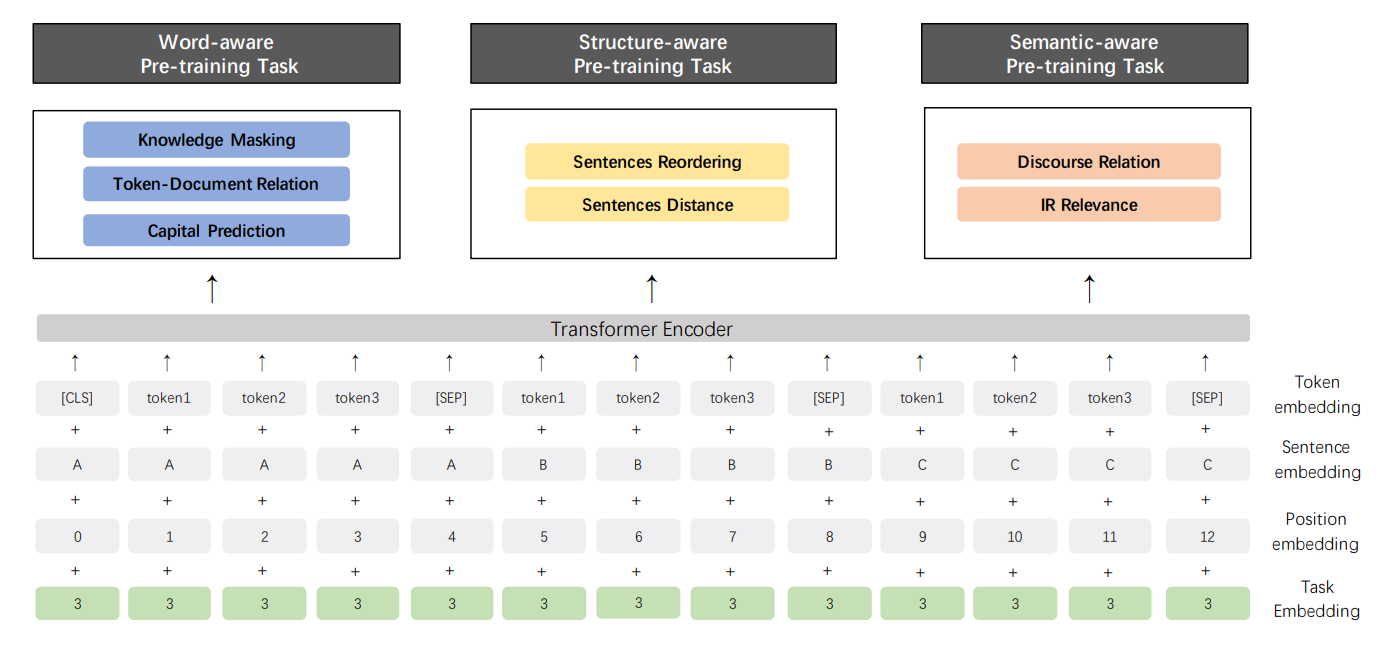
This diagram is provided in the paper in section 4.2.3
Let’s start with the input: the input embedding contains the token embedding, sentence embedding, position embedding, and task embedding. If you have never heard of embeddings, they are essentially a form of representation to convert something a human understands to something a machine understands. (Read more about it here: https://bit.ly/2k52nWt)
Next, it’s fed into an “encoder” which can be any neural network. Of course, you want to use an RNN (recurrent neural network) or a Transformer for the best performance in natural language processing.
*ERNIE 2.0 uses a transformer with the same settings as BERT and XLNET.
Lastly, the final output contains the outputs of the 7 tasks which are:
- Knowledge Masking
- Token-Document Relation
- Capital Prediction
- Sentence Reordering
- Sentences Distance
- Discourse Relation
- IR Relevance
These tasks were specifically picked to learn the lexical (vocabulary), syntactic (structure), and semantic (meaning) information of the language. Read section 4.2 of the paper for a detailed explanation of each task.
The training process is basically identical to the example we showed above for continual learning:
First train Task 1,
then Task 1 & 2,
then Task 1 & 2 & 3,
and so on… all the way till you have all 7 tasks training at the same time.
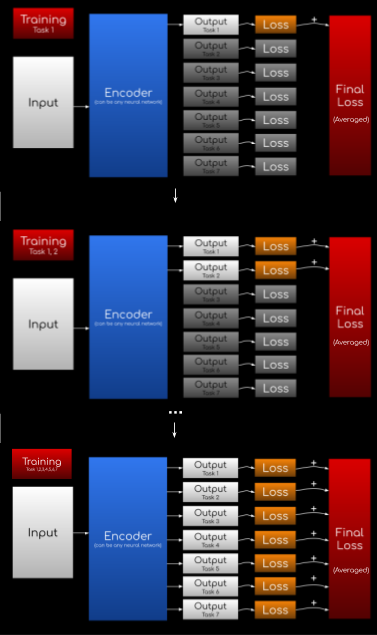
*As seen in Figure 4, when tasks are inactive during training, their loss function is essentially always zero.
Also, one difference in the ERNIE 2.0 setting is that losses are averaged in the end (instead of summing them).
Concerns Regarding ERNIE 2.0’s Results
ERNIE 2.0 has beaten all previous architectures such as XLNet and BERT in every single task of the GLUE benchmark. While the paper implies the groundbreaking results were caused by Continual Multi-Task Learning, there haven’t been ablation studies to prove it. Some factors outside of Continual Multi-Task learning that could’ve played a key role in beating XLNET and BERT are:
- A lot more data was used to train the model (Reddit, Discovery data…). However, this is unavoidable to a certain extent; since multi-task learning requires more training objectives, it implies more data is needed.
- The neural network was implemented in PaddlePaddle
More importantly, the following questions need to be answered in order to attribute ERNIE 2.0’s results to Continual Multi-Task Learning:
- How much did Multi-Task learning matter in the results?
- How much did Continual Learning matter in the results? What if you trained all 7 tasks at once instead of going sequentially?
- Does the order of the tasks matter?
Conclusion
To summarize, ERNIE 2.0 introduced the concept of Continual Multi-Task Learning, and it has successfully outperformed XLNET and BERT in all NLP tasks. While it can be easy to say Continual Multi-Task Learning is the number one factor in the groundbreaking results, there are still many concerns to resolve.
Of course, this article does not cover the full range of topics in the paper such as the specific experimental results, and it was never meant to. This article is merely an intuitive explanation for the core concepts of ERNIE 2.0. If you’re interested in understanding ERNIE 2.0 fully, please read the paper as well!
The Paper: “ERNIE 2.0: A Continual Pre-training Framework for Language Understanding”
Authors: Yu Sun, Shuohuan Wang, Yukun Li, Shikun Feng, Hao Tian, Hua Wu, Haifeng Wang
Link: https://arxiv.org/pdf/1512.03385.pdf
Original. Reposted with permission.
Related:
- Interpolation in Autoencoders via an Adversarial Regularizer
- Pre-training, Transformers, and Bi-directionality
- Large-Scale Evolution of Image Classifiers