Data Preparation for Machine learning 101: Why it’s important and how to do it
As data scientists who are the brains behind the AI-based innovations, you need to understand the significance of data preparation to achieve the desired level of cognitive capability for your models. Let’s begin.
By Nandhini TS, Xtract.io
Coding is a prerequisite for successful business models.
I recently stumbled upon this answer by Alexandre Robicquet on Quora which was also published on Forbes. For a beginner who’s looking for the most sensible advice on “How can I start learning about Machine Learning and Artificial Intelligence”, here’s what he says:
A condensed version of his perspective:
- Master coding, particularly python that is most ideal for machine learning. In addition to coding expertise, you should have good analytical and statistical skills.
- For starters, you can begin by cloning codes from git repositories or tutorials. But, to become a sound ML/AI engineer, you must know and own what you’re doing.
- Do not invent a solution and hunt for the problem. Instead, identify the problems and challenges to invent an automated solution.
(You may read his answer here).
But, that’s not it.
If you’re a coding nerd, double-check the quality and structure of data you feed into your algorithms as they play a huge role in inventing a successful analytical model.
There are 3 dimensions to building a successful AI/ML model:
Algorithms, data, and computation.
While building the accurate algorithms and application of computational skills is a part of the process, what is foundational to this?
Lay groundwork with the right data.
Right from massive AI-based technology revolutions like self-driving cars to building a very simple algorithm, you need data in the right form.
In fact, Tesla and Ford have been collecting data through dash cams, sensors, and back up cameras and analyzing it to build driverless and fully automated cars for safe roads.
The next step after collecting data comes the process of preparing the data which is going to be the crux of this article and will be discussed in detail in the further sections.
Before drilling down to the concept of the data preparation process, let’s understand the meaning first. As data scientists who are the brains behind the AI-based innovations, you need to understand the significance of data preparation to achieve the desired level of cognitive capability for your models.
Let’s begin.
What is data preparation?
Data is a precious resource for every organization. But, if we don’t analyze that statement further, it can negate itself.
Businesses use data for various purposes. On a broad level, it is used to make informed business decisions, execute successful sales and marketing campaigns, etc. But, these cannot be implemented with just raw data.
Data becomes a precious resource only if it is cleansed, well-labeled, annotated, and prepared. Once the data goes through various stages of fitness tests it then finally becomes qualified for further processing. The processing could be of several methods - data ingested to BI tools, CRM database, developing algorithms for analytical models, data management tools and so on.
Now, it is important that the insights you gather from the analysis of this information is accurate and trustworthy. The foundation of achieving this output lies in the health of the data. Additionally, whether you build your own models or get them from third parties, you must ensure that the data behind this entire process is labeled, augmented, clean, structured - to summarize, that is data preparation.
As Wikipedia defines, Data preparation is the act of manipulating (or pre-processing) raw data (which may come from disparate data sources) into a form that can readily and accurately be analyzed, e.g. for business purposes. Data preparation is the first step in data analytics projects and can include many discrete tasks such as loading data or data ingestion, data fusion, data cleaning, data augmentation, and data delivery.
Importance of Data preparation for ML
According to a recent study by Cognilytica, wherein responses of organizations, agencies, and end-user enterprises were recorded and analyzed to identify a lot of time is spent over labeling, annotation, cleansing, augmenting, and enrichment of data for machine learning models.
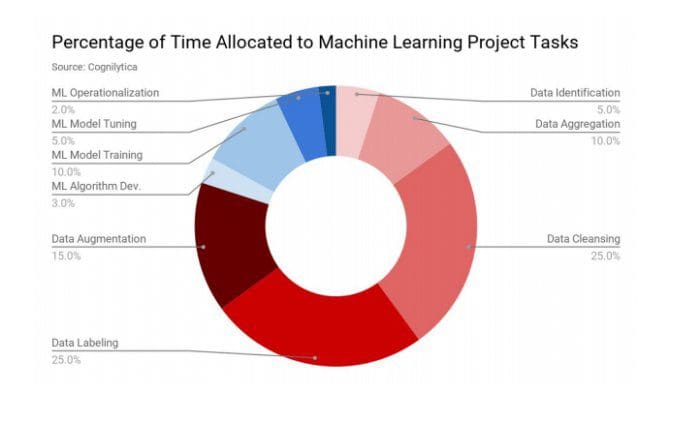
More than 80% of a data scientist’s time is spent on preparing the data. While this is a good sign, considering that as good data goes into building the analytical model, the accurate gets the output. But, data scientists should ideally be spending more of their time interacting with data, advanced analytics, training and evaluating the model, and deploy to production.
Only 20% of the time goes into the major chunk of the process. In order to overcome time constraints, organizations need to reduce the time taken (varies depending on the complexity of the project) on cleansing, augmenting, labeling and enriching the data by leveraging expert solutions for data engineering, labeling, and preparation.
This brings us to the concept of Garbage in garbage out i.e. the quality of output is determined by the quality of the input.
The Data Preparation Process
Here’s a quick brief of the data preparation process specific to machine learning models:
Data extraction the first stage of the data workflow is the extraction process which is typically retrieval of data from unstructured sources like web pages, PDF documents, spool files, emails, etc. The process deployed in extracting the information from the web is termed as web scraping.
Data profiling is the process of reviewing existing data to improve the quality and bring structure through a format. This helps in assessing the quality and coherence to particular standards. Most machine learning models fail to work when the datasets are imbalanced and not well-profiled.
Data cleansing ensures data is clean, comprehensive, error-free with accurate information as it helps in detecting outliers not only for texts and numeric but also irrelevant pixels from images. You can eliminate bias and obsolete information to ensure your data is clean.
Data transformation is transforming data to make it homogeneous. Data like addresses, names, and other field types are represented in different formats and data transformation helps in standardizing and normalizing this.
Data anonymization is the process of removing or encrypting personal information from the datasets to protect privacy.
Data augmentation is used to diversify the data available for your training models. Bringing in additional information without extracting new information includes cropping and padding to train neural networks.
Data sampling Identify representative subsets from large datasets to analyze and manipulate data.
Feature engineering is a major determinant of classifying a machine learning model as a good or a bad model. To improve the model accuracy you would combine datasets to consolidate it into one.
Here’s an example:
Let’s say there are two columns, one is income and the other is the output classification (A, B, C). The output A, B, C are dependent on the income range $2k - $3K, $4k - $5K, and $6K - $7K. The new feature would be income-range assigning numerical values 1,2, and 3. Now, these numerical values are mapped to the 3 datasets we created initially.
Here, the income-range is feature engineering.
Watch this video on Feature engineering by MindOrks for further understanding.
https://www.youtube.com/watch?time_continue=1&v=CXDfQdYpGGw
Another essential part of the data preparation process is labeling. To make this concept simple to understand, let me take an example of a hot beverage, say, tea.
Now, the goal of the project is to identify the percentage or amount of caffeine contained in a particular type of tea.
Black tea contains 20mg of caffeine
Tea + Milk has 11mg of caffeine
Herb tea has 0mg of caffeine
Earl grey tea 40mg of caffeine
Note: (Caffeine percentage calculated for 100 grams of tea)
So, the ML model will assign a numerical value say 1 to earl grey that has the highest amount of caffeine, 2 to black tea, and so on. This brings us to the concept of labeling that helps in identifying datasets.
Data Labeling - An essential and integral part of data preparation
Labeling is simply assigning tags to a set of unlabeled data to make it more identifiable for predictive analysis.
These labels indicate whether the animal in the photo is a dog or a fox (see image below).
Labeling helps the machine learning model to guess and predict a piece of unlabeled data as a result of feeding the model with millions of labeled data.

Some use cases of data labeling:
- Image classification/annotation of videos and images includes annotation of images, its description, bounding box definition, and more.
- Conversational tagging A typical example would be chatbots wherein the data is labeled and trained to make conversations with users more realistic and relevant.
- Sentiment analysis Labeling of data be it text or images to understand the sentiment of the content like in the case of tweet.
Speech and text NLP is the labeling for audio and text sources. - Face detection Label image sets and train for accurate detection and prediction
- Where to begin?
Data preparation is an essential prerequisite to build innovative business models. Poor data and good models are a bad combination that can ruin the efficiency and performance of the model you intend to build.
There are a plenty of data preparation solutions available out there that can help you save time and achieve efficiency. Though there are self-service data preparation tools available out there in the market, the managed services slightly have an edge over them considering the scalability of the in-house infrastructure, leveraging vast data collection from disparate sources, compliance to various data norms and guidelines, getting expert assistance as and when needed.
There are a couple of data preparation-as-managed-services vendors like Xtract.io, Informatica, Assetanalytix, Capestart etc. that you can consider to help you get started with data preparation.
If there are any questions you want to ask or any new information that you’d want to share, do drop your comments below so that we can spark some interesting conversations.
Bio: Nandhini TS is a product marketing associate at Xtract.io – a data solutions company. She enjoys writing about the power and influence of data for successful business operations. In her time off, she has her nose buried in growing her side hustles and binge-watching dinosaur documentaries.
Related:
- 7 Steps to Mastering Data Preparation for Machine Learning with Python — 2019 Edition
- 5 Ways to Deal with the Lack of Data in Machine Learning
- Fantastic Four of Data Science Project Preparation