Can Neural Networks Develop Attention? Google Thinks they Can
Google recently published some work about modeling attention mechanisms in deep neural networks.

Trying to read this article is a complicated task from the neuroscientific standpoint. At this time you are probably bombarded with emails, news, notifications on our phone, the usual annoying coworker interrupting and other distractions that cause your brain to spin on many directions. In order to read this tiny article or perform many other cognitive tasks, you need to focus, you need attention.
Attention is a cognitive skill that is pivotal to the formation of knowledge. However, the dynamics of attention have remained a mystery to neuroscientists for centuries and, just recently, that we have had major breakthroughs that help to explain how attention works. In the context of deep learning programs, building attention dynamics seems to be an obvious step in order to improve the knowledge of models and adapt them to different scenarios. Building attention mechanisms into deep learning systems is a very nascent and active area of research. A few months ago, researchers from the Google Brain team published a paper that detailed some of the key models that can be used to simulate attention in deep neural networks.
How Attention Works?
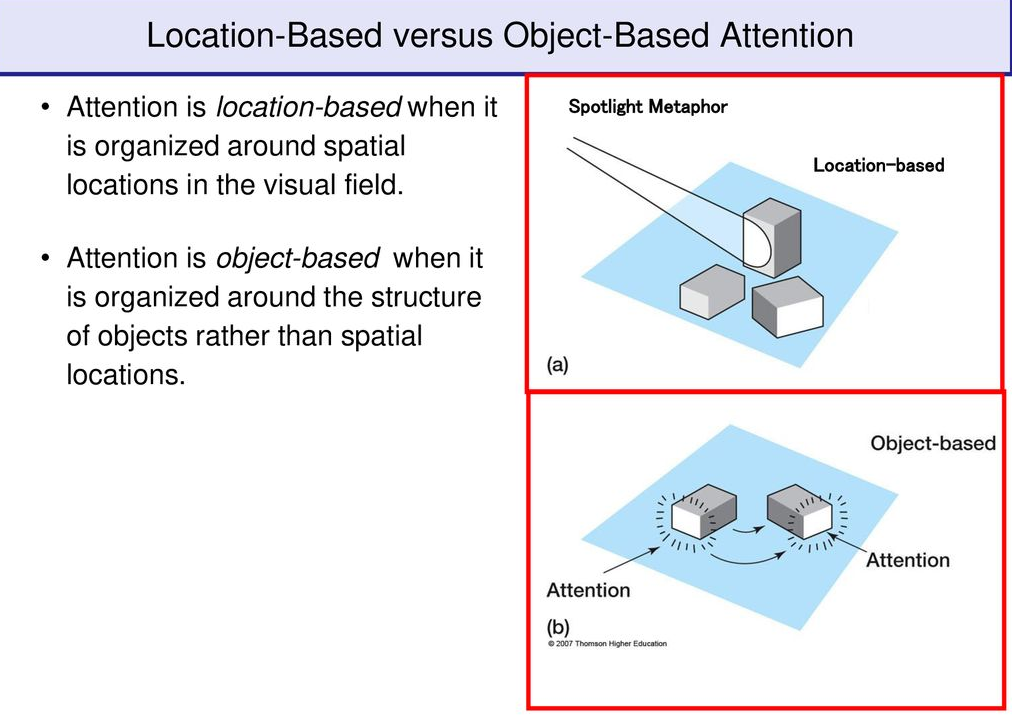
In order to understand attention in deep learning systems it might be useful to take a look at how this cognitive phenomenon takes place in the human brain. From the perspective of neuroscience, attention is the ability of the brain to selectively concentrate on one aspect of the environment while ignoring other things. The current research identifies two main types of attention both related to different areas of the brain. Object-based attention is often referred to the ability of the brain to focus on specific objects such as a picture of a section in this article. Spatial-based attention is mostly related to the focus on specific locations. Both types of attention are relevant in deep learning models. While object-based attention can be used in systems such as image recognition or machine translation, spatial-attention is relevant in deep reinforcement learning scenarios such as self-driving vehicles.
Attentional Interfaces in Deep Neural Networks
When comes to deep learning systems, there are different techniques that have been created in order to simulate different types of attention. The Google research paper focuses on four fundamental models that are relevant to recurrent neural networks(RNNs). Why RNNs specifically? Well, RNNs are a type of network that is mostly used to process sequential data and obtain higher-level knowledge. As a result, RNNs are often used as a second step to refine the work of other neural network models such as convolutional neural networks(CNNs) or generative interfaces. Building attention mechanisms into RNNs can help improve the knowledge of different deep neural models. The Google Brain team identified the following four techniques for building attention into RNNs models:

- Neural Turing Machines: One of the simplest attentional interfaces, Neural Turing Machines(NTMs) add a memory structure to traditional RNNs. Using a memory structure allows ATM to specify an “attention distribution” section that describes the area that the model should focus on. Las year, I published an overview of NTMs that explores some of its fundamental concepts. Implementations of NTMs can be found in many of the popular deep learning frameworks such as TensorFlow and Theano.
- Attentional Interfaces: Attentional interfaces uses an RNN model to focus on specific sections of another neural network. A classic example of this technique can be found in image recognition models using a CNN-RNN duplex. In this architecture, the RNN will focus on specific parts of the images generated by the CNN in order to refine it and improve the quality of the knowledge.
- Adaptive Computation Time: This is a brand-new technique that allows RNNs to perform multiple steps of computation for each time step. How is this related to attention? Very simply, standard RNNs perform the same amount of computation of each step. Adaptive computation time techniques used an attention distribution model to the number of steps to run each time allowing to put more emphasis on specific parts of the model.
- Neural Programmer: A fascinating new area in the deep learning space, neural programmer models focus on learning to create programs in order to solve a specific task. In fact, it learns to generate such programs without needing examples of correct programs. It discovers how to produce programs as a means to the end of accomplishing some task. Conceptually, neural programmer techniques try to bridge the gap between neural networks and traditional programming techniques that can be used to develop attention mechanisms in deep learning models.
Attention is one of the most complicated cognitive abilities of the human brain. Simulating attention mechanisms in neural networks can open a new set of fascinating possibilities for the future of deep learning.
Original. Reposted with permission.
Related:
- About Google’s Self-Proclaimed Quantum Supremacy and its Impact on Artificial Intelligence
- Facebook Adds This New Framework to It’s Reinforcement Learning Arsenal
- Facebook Has Been Quietly Open Sourcing Some Amazing Deep Learning Capabilities for PyTorch