Facebook Adds This New Framework to It’s Reinforcement Learning Arsenal
ReAgent is a new framework that streamlines the implementation of reasoning systems.

Building deep reinforcement learning(DRL) systems remains an incredibly challenging. As a nascent discipline in the deep learning space, the frameworks and tools for implementing DRL models remain incredibly basic. Furthermore, the core innovation in DRL is coming from the big corporate AI labs like DeepMind, Facebook or Google. Almost a year ago, Facebook open sourced Horizon a framework focused on streamlining the implementation of DRL solutions. After a year using Horizon and implementing large scale DRL systems, Facebook open sourced ReAgent, a new framework that expands the original vision of Horizon to the implementation of end-to-end reasoning systems.
From a product standpoint, ReAgent is the next version of Horizon but, practically speaking is much more. ReAgent expands the original capabilities of Horizon with new models and tools that simplify the implementation of reasoning systems. Conceptually, reasoning systems refers to artificial intelligence(AI) agents that are able to learn by trial and error. DRL is certainly the most prominent type of reasoning systems but the class can include other techniques such as simulations. Before diving into ReAgent, let’s do a quick walkthrough the capabilities of its predecessor.
A Quick Recap of Horizon
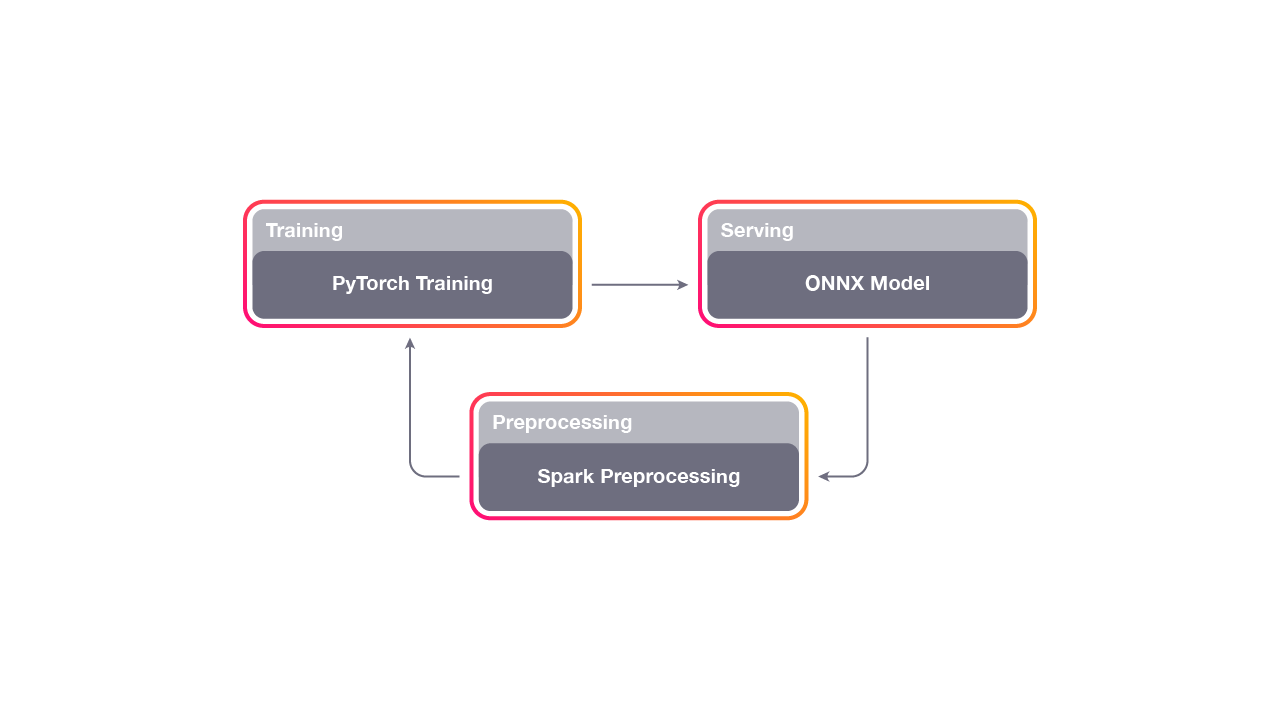
Horizon was initially designed to work efficiently across deep learning frameworks such as PyTorch and Caffe2 which are actively used within Facebook. Specifically, Horizon streamlines the use of PyTorch for model experimentation and training while Caffe2 is reserved for production workflows. A typically Horizon reinforcement learning workflow includes a Spark pipeline for time generation, followed by a feature extraction and normalization module based on Scipy followed by the model preprocessing-training and optimization module. Horizon leverages Facebook’s ONNX as the internal model representation and integrates with popular reinforcement learning environments such as OpenAI Gym.

The first released of Horizon abstracted capabilities such as data pre-processing, multi-GP training, a rich DRL algorithm portfolio, feature normalization among other key building blocks of DRL architectures.
One of the biggest contributions of Horizon is the feedback loop between experimentation and production. The training pipeline is responsible for pre-processing data logged by the existing model. That results of the pre-processing are used to train and analyze the counterfactual policy results in an offline setting. Finally, the models are deployed to a group of people and measure the true policy which results are used to feeds back into the next iteration.
After the first released of Horizon, Facebook discovered new improvements and capabilities that were needed to streamline the implementation of reasoning systems even further.
Enter ReAgent
One of the lessons learned after using Horizon in large scale DRL solutions, was that the framework was more effective when evaluating DRL models that have been previously trained instead of implementing new models. To address that limitation, ReAgent was implemented as a lightweight C++ library that can be embedded into any DRL model that is starting the process of collecting new data.
The core architecture of ReAgent is based on three fundamental components: models, evaluators and the serving platform. A ReAgent-enabled model will process the actions from external users or systems and route them to a set of training models whose scores help determine the next best action( like recommending a product). ReAgent can also send suggested model changes to an offline evaluator, which tests updated decision plans before they’re incorporated into the deployed model.

The main principle behind ReAgent’s architecture is to turn inputs into training resources. Let’s take the example of the training of an agent that plays different board games. When a user selects an action of specific move, ReAgent serving platform(RSP) responds by generating scores that rank a given set of related actions, according to preexisting decision plans. These plans are based on a collection of parameters determined by the models provided as part of ReAgent. This approach addresses the cold-start problem, where it is difficult or impossible to personalize actions without already having sufficient feedback.
In addition to simplifying and training of DRL systems, ReAgent excels on its ability of turning feedback into model rewards. This can be done by either modifying the online training models that optimize the RSP’s performance in real time or for offline training, which can lead to more substantial optimizations over longer periods of time.
ReAgent proposes a modular design that covers most elements of the lifecycle of DRL systems. Let’s assume that DRL models start with little to no data and, therefore, must make decisions using handwritten rules, which can be updated across many machines in real time using ReAgent’s serving platform. With feedback, multi-armed bandits, which share a parameter store, can adapt to make better decisions over time. Finally, contextual feedback enables ReAgent to train contextual bandits and RL models, and deploy them using the TorchScript library in PyTorch, to produce more personalized actions.
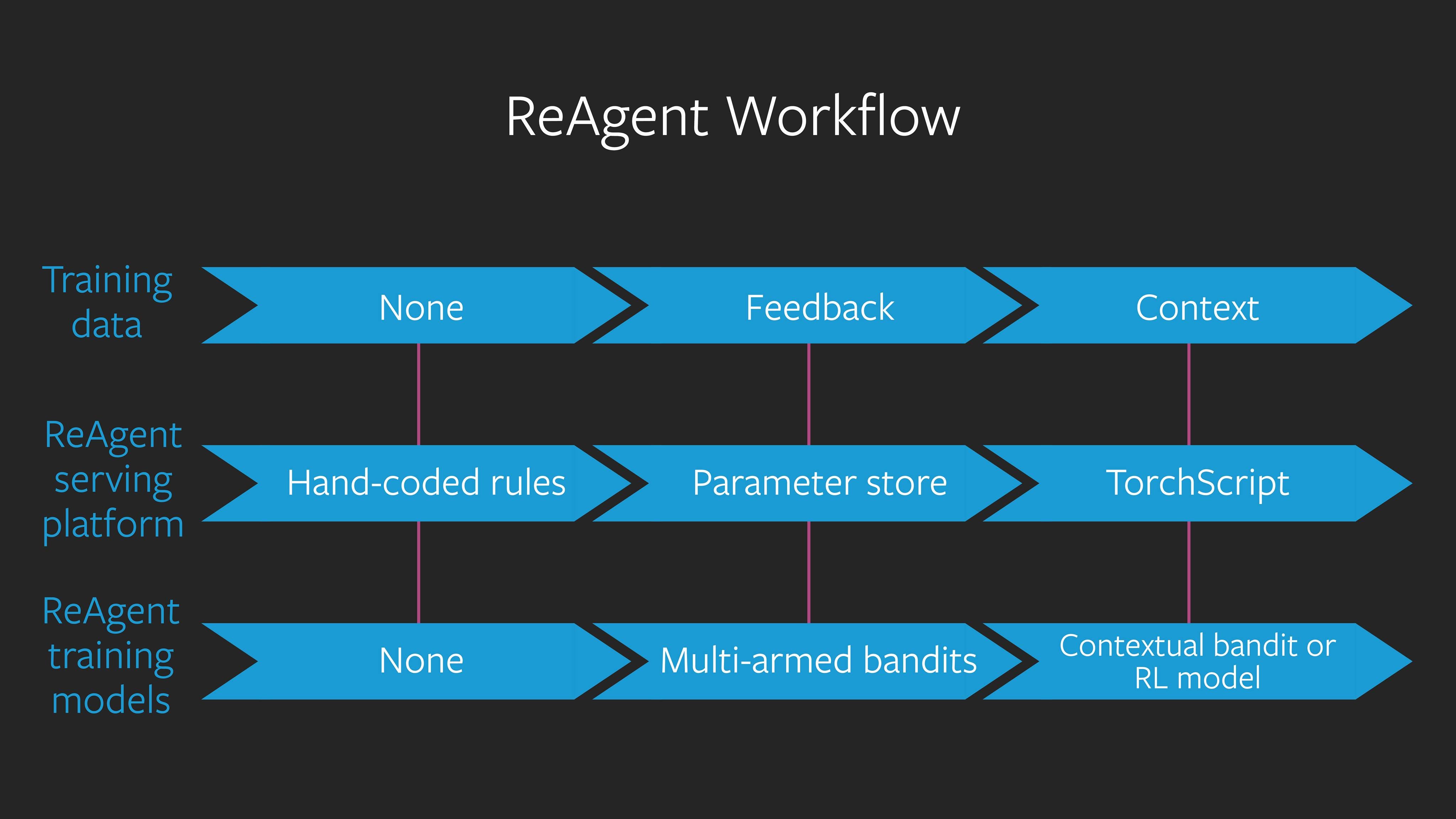
In the absence of a framework like ReAgent, developers would need to build different projects to address each one of the phases of the model lifecycle. Being a lightweight, easy to embed, C++ library, ReAgent allows developers to build different aspects of the DRL systems using their favorite technique while relying on the framework for cutting-edge, feedback-based policy optimization.
No DRL framework is complete without a deep algorithm portfolio. In the case of ReAgent, the framework supports several state-of-the-art DRL models including the following:
- Discrete-Action DQN
- Parametric-Action DQN
- Double DQN, Dueling DQN, Dueling Double DQN
- Distributional RL C51, QR-DQN
- Twin Delayed DDPG (TD3)
- Soft Actor-Critic (SAC)
Facebook is already using ReAgent at scale in several mission critical systems. ReAgent models are used to determine the relevance of Instagram notifications and also provided more personalized news recommendations. As Facebook continues experimenting with ReAgent, we should see some of their learnings being incorporated into the framework.
DRL remains one of the most difficult deep learning architectures to implement with modern technologies. Releases like ReAgent provide some of the fundamental building blocks of DRL architectures and an extensible programming model that allow researchers and machine learning engineers to regularly experiment with different ideas. The current release of ReAgent is available on GitHub and also includes a basic interactive tutorial that will help you get started playing with DRL systems.
Original. Reposted with permission.
Related:
- Facebook Has Been Quietly Open Sourcing Some Amazing Deep Learning Capabilities for PyTorch
- Three Things to Know About Reinforcement Learning
- Inside Pluribus: Facebook’s New AI That Just Mastered the World’s Most Difficult Poker Game