Three Things to Know About Reinforcement Learning
As an engineer, scientist, or researcher, you may want to take advantage of this new and growing technology, but where do you start? The best place to begin is to understand what the concept is, how to implement it, and whether it’s the right approach for a given problem.
By Emmanouil Tzorakoleftherakis, Product Manager, MathWorks
If you are following technology news, you have likely already read about how AI programs trained with reinforcement learning beat human players in board games like Go and chess, as well as video games. As an engineer, scientist, or researcher, you may want to take advantage of this new and growing technology, but where do you start? The best place to begin is to understand what the concept is, how to implement it, and whether it’s the right approach for a given problem.
If we simplify the concept, at its foundation, reinforcement learning is a type of machine learning that has the potential to solve toughdecision-making problems. But to truly understand how it impacts us, we need to answer three key questions:
- What is reinforcement learning and why should I consider it when solving my problem?
- When is reinforcement learning the right approach?
- What is the workflow I should follow to solve my reinforcement learning problem?
What Is Reinforcement Learning?
Reinforcement learning is a type of machine learning in whicha computer learns to perform a task through repeated trial-and-error interactions with a dynamic environment. This learning approach enables the computer to make a series of decisions that maximize a reward metric for the task without human intervention and without being explicitly programmed to achieve the task.
Tobetter understand reinforcement learning, let’s look at a real-world equivalent situation. Figure 1 shows a general representation of training a dog using reinforcement learning.

Figure 1. Reinforcement learning in dog training.
The goal of reinforcement learning in this case is to train the dog (agent) to complete a task within an environment, which includes the surroundings of the dog as well as the trainer. First, the trainer issues a command or cue, which the dog observes (observation). The dog then responds by taking an action. If the action is close to the desired behavior, the trainer will likely provide a reward, such asa food treat or a toy; otherwise, no reward or a negative reward will be provided. At the beginning of training, the dog will likely take more random actions like rolling over when the command given is “sit,” as it is trying to associate specific observations with actions and rewards. This association, or mapping, between observations and actions is called policy.
From the dog’s perspective, the ideal case would be one in which it would respond correctly to every cue, so that it gets as many treats as possible. So, the whole meaning of reinforcement learning training is to “tune” the dog’s policy so that it learns the desired behaviors that will maximize some reward. After training is complete, the dogshould be able to observe the owner and take the appropriate action, for example, sitting when commanded to “sit” by using the internal policy it has developed. By this point, treats are welcome but shouldn’t be necessary (theoretically speaking!).
Based on the dog training example, consider the task of parking a vehicle using an automated driving system (). The goal of this task is for the vehicle computer (agent) to park the vehicle in the correct parking spotwith the right orientation. Like the dog training case, the environment here is everything outside the agent and could include the dynamics of the vehicle, other vehicles that may be nearby, weather conditions, and so on. During training, the agentuses readings from sensors such as cameras, GPS, and lidar (observations) to generate steering, braking, and acceleration commands (actions).To learn how to generate the correct actions from the observations (policy tuning), the agent repeatedly tries to park the vehicle using a trial-and-error process. A reward signal can be provided to evaluate the goodness of a trial and to guide the learning process.

Figure 2. Reinforcement learning in autonomous parking.
In the dog training example, training is happening inside the dog’s brain. In the autonomous parking example, training is supervised by a training algorithm. The training algorithm is responsible for tuning the agent’s policy based on the collected sensor readings, actions, and rewards. After training is complete, the vehicle’s computer should be able to park using only the tuned policy and sensor readings.
When Is Reinforcement Learning the Right Approach?
Many reinforcement learning training algorithms have been developed to date; this article does not cover training algorithms, but it is worth mentioning that some of the most popular ones rely on deep neural network policies. The biggest advantage of neural networks is that they can encode really complex behaviors, which opens up the use of reinforcement learning in applications that are otherwise intractable or very challenging to tackle with alternative methods, including traditional algorithms. For example, in autonomous driving, a neural network can replace the driver and decide how to turn the steering wheel by simultaneously looking at input from multiple sensors, such as camera frames and lidar measurements (end-to-end solution). Without neural networks, the problem would normally be broken down into smaller pieces: a module that analyzes the camera input to identify useful features, another module that filters the lidar measurements, possibly one component that would aim to paint the full picture of the vehicle’s surroundings by fusing the sensor outputs, a “driver” module, and more! However, the benefit of end-to-end solutions comes with a few drawbacks.
A trained deep neural network policy is often treated as a “blackbox,” meaning that the internal structure of the neural network is so complex, often consisting of millions of parameters, that it is almost impossible to understand, explain, and evaluate the decisions taken by the network (left side of Figure 3). This makes it hard to establish formal performance guarantees with neural network policies. Think of it this way: Even if you train your pet, there will still be occasions when your commands will go unnoticed.

Figure 3. Some of the challenges of reinforcement learning.
Another thing to keep in mind is that reinforcement learning is not sample efficient. This means that, in general, a lot of training is required in order to reach acceptable performance. As an example, AlphaGo, the first computer program to defeat a world champion at the game of Go, was trained nonstop for a period of a few days by playing millions of games, accumulating thousands of years of human knowledge. Even for relatively simple applications, training time can take anywhere from minutes to hours or days. Finally, setting up the problem correctly can be tricky; many design decisions need to be made, which may require a few iterations to get it right (right side of Figure 3). These decisions include, for example, selecting the appropriate architecture for the neural networks, tuning hyperparameters, and shaping the reward signal.
In summary, if you are working on a time- or safety-critical project that you could potentially approach with alternative, traditional ways, reinforcement learning may not be the best thing to try first. Otherwise, give it a go!
Reinforcement Learning Workflow
The general workflow for training an agent using reinforcement learning includes the following steps (Figure 4).
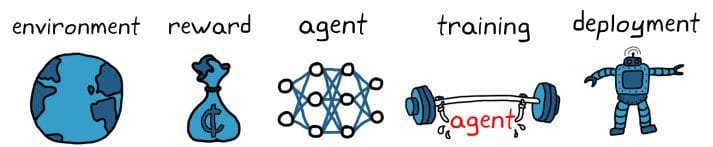
Figure 4.Reinforcement learning workflow.
1. Create the Environment
First you need to define the environment within which the agent operates, including the interface between agent and environment. The environment can be either a simulation model or a real physical system.Simulated environmentsare usually a good first step since they are safer (real hardware is expensive!) and allow experimentation.
2. Define the Reward
Next, specify the reward signal that the agent uses to measure its performance against the task goals and how this signal is calculated from the environment.Reward shaping can be tricky and may require a few iterations to get right.
3. Create the Agent
In this step, you create the agent. The agent consists of the policy and the training algorithm (refer back to ), so you need to:
a. Choose a way to represent the policy (e.g.,using neural networks or look-up tables).
b. Select the appropriate training algorithm. Different representations are often tied to specific categories of training algorithms, but in general, most modern algorithms rely on neural networksbecause they are good candidates for large state/action spaces and complex problems.
4. Train and Validate the Agent
Set up training options (e.g., stopping criteria) and train the agent to tune the policy. Make sure to validate the trained policy after training ends. Training can take anywhere from minutes to days depending on the application. For complex applications, parallelizing training on multiple CPUs, GPUs, and computer clusters will speed things up.
5. Deploy the Policy
Deploy the trained policy representation using, for example, generated C/C++ or CUDA code. No need to worry about agents and training algorithms at this point—the policy is a standalone decision-making system!
Training an agent using reinforcement learning is an iterative process. Decisions and results in later stages can require you to return to an earlier stage in the learning workflow. For example, if the training process does not converge on an optimal policy within a reasonable amount of time, you may have to update any of the following before retraining the agent:
- Training settings
- Learning algorithm configuration
- Policy representation
- Reward signal definition
- Action and observation signals
- Environment dynamics
Today, tools like Reinforcement Learning Toolbox(Figure 5) can help you quickly learn and implement controllers and decision-making algorithmsfor complex systems such as robots and autonomous systems.
Figure 5. Teaching a robot to walk with Reinforcement Learning Toolbox.
Regardless of the choice of tool, before deciding to adopt reinforcement learning, do not forget to ask yourself: “Given the time and resources I have for this project, is reinforcement learning the right approach for me?”
To learn more about reinforcement learning, see the links below.
- Reinforcement Learning (webpage): Learn about reinforcement learning and how MATLAB and Simulink can support the complete workflow for designing and deploying a reinforcement learning based controller.
- Train DQN Agent to Balance Cart-Pole System (example): Find out how to train a deep Q-learning network (DQN) agent to balance a cart-pole system modeled in MATLAB.
- Train Biped Robot to Walk Using DDPG Agent (example): Find out how to train a biped robot, modeled in Simscape Multibody, to walk using a deep deterministic policy gradient (DDPG) agent.
- Reinforcement Learning (video series): Watch an overview of reinforcement learning, a type of machine learning that has the potential to solve some control system problems that are too difficult to solve with traditional techniques.
- Reinforcement Learning with MATLAB (ebook): Find out how to get started with reinforcement learning in MATLAB and Simulink by explaining the terminology and providing access to examples, tutorials, and trial software.