Choosing a Machine Learning Model
Selecting the perfect machine learning model is part art and part science. Learn how to review multiple models and pick the best in both competitive and real-world applications.
By Lavanya Shukla, Weights and Biases.

The number of shiny models out there can be overwhelming, which means a lot of times people fall back on a few they trust the most and use them on all new problems. This can lead to sub-optimal results.
Today we’re going to learn how to quickly and efficiently narrow down the space of available models to find those that are most likely to perform best on your problem type. We’ll also see how we can keep track of our models’ performances using Weights and Biases and compare them.
You can find the accompanying code here.
What We’ll Cover
- Model selection in competitive data science vs. real world
- A Royal Rumble of Models
- Comparing Models
Let’s get started!
Unlike Lord of the Rings, in machine learning, there is no one ring (model) to rule them all. Different classes of models are good at modeling the underlying patterns of different types of datasets. For instance, decision trees work well in cases where your data has a complex shape:

Whereas linear models work best where the dataset is linearly separable:
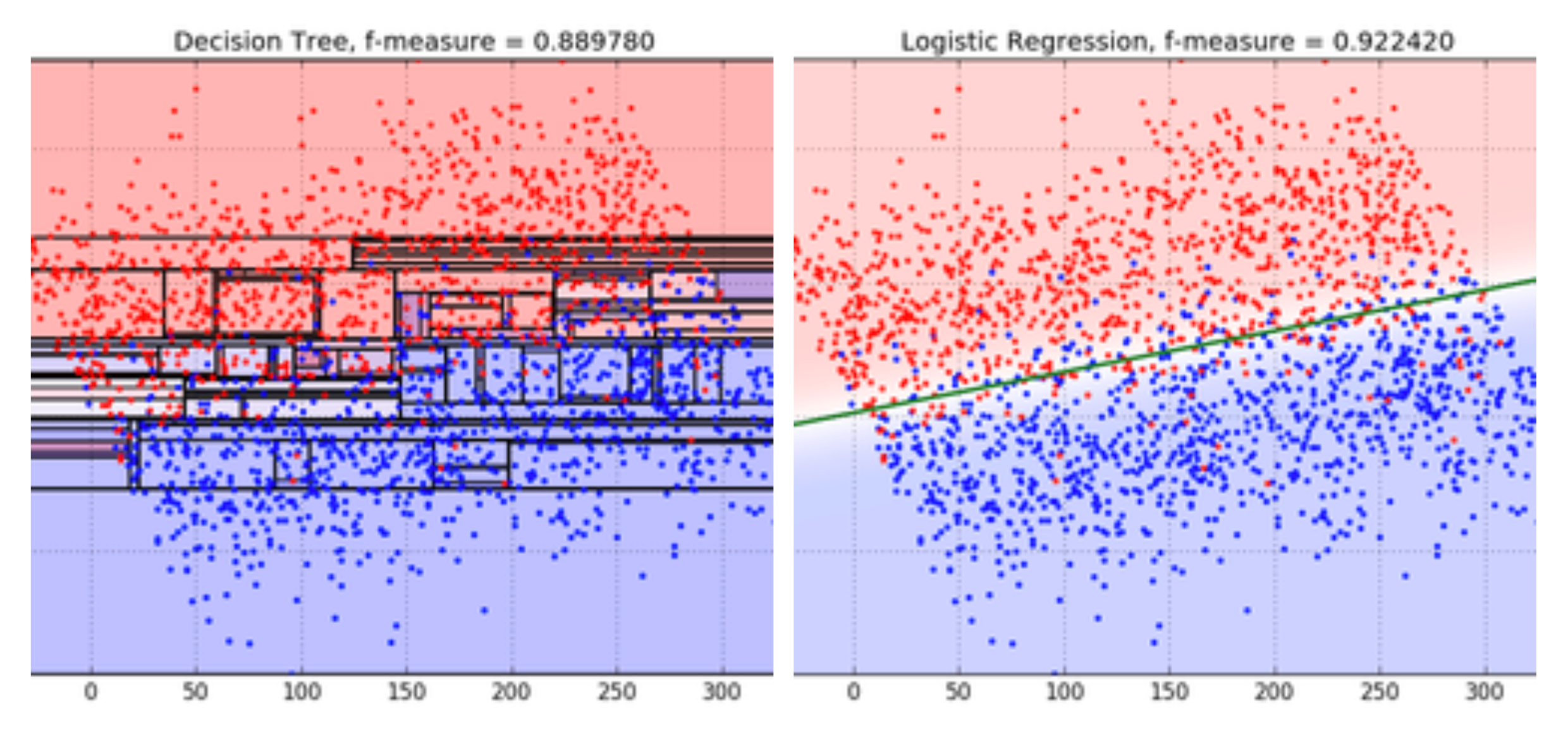
Before we begin, let’s dive a little deeper into the disparity between model selection in the real world vs for competitive data science.
Model selection in competitive data science vs. real world
As William Vorhies said in his blog post, “the Kaggle competitions are like formula racing for data science. Winners edge out competitors at the fourth decimal place, and like Formula 1 race cars, not many of us would mistake them for daily drivers. The amount of time devoted and the sometimes extreme techniques wouldn’t be appropriate in a data science production environment.”
Kaggle models are indeed like racing cars, as they’re not built for everyday use. Real-world production models are more like a Lexus — reliable but not flashy.
Kaggle competitions and the real world optimize for very different things, with some key differences being:
Problem Definition
The real world allows you to define your problem and choose the metric that encapsulates the success of your model. This allows you to optimize for a more complex utility function than just a singular metric, where Kaggle competitions come with a single pre-defined metric and don’t let you define the problem efficiently.
Metrics
In the real world, we care about inference and training speeds, resource and deployment constraints and other performance metrics, whereas in Kaggle competitions the only thing we care about is the one evaluation metric. Imagine we have a model with 0.98 accuracy that is very resource and time-intensive, and another with 0.95 accuracy that is much faster and less compute-intensive. In the real world, for a lot of domains, we might prefer the 0.95 accuracy model because maybe we care more about the time to inference. In Kaggle competitions, it doesn’t matter how long it takes to train the model or how many GPUs it requires, higher accuracy is always better.
Interpretability
Similarly, in the real world, we prefer simpler models that are easier to explain to stakeholders, whereas in Kaggle we pay no heed to model complexity. Model interpretability is important because it allows us to take concrete actions to solve the underlying problem. For example, in the real world looking at our model and being able to see a correlation between a feature (e.g., potholes on a street), and the problem (e.g. likelihood of car accident on the street), is more helpful than increasing the prediction accuracy by 0.005%.
Data Quality
Finally, in Kaggle competitions, our dataset is collected and wrangled for us. Anyone who’s done data science knows that is almost never the case in real life. But being able to collect and structure our data also gives us more control over the data science process.
Incentives
All this incentivizes a massive amount of time spent tuning our hyperparameters to extract the last drops of performance from our model and, at times, convoluted feature engineer methodologies. While Kaggle competitions are an excellent way to learn data science and feature engineering, they don’t address real-world concerns like model explainability, problem definition, or deployment constraints.
A Royal Rumble of Models
It’s time to start selecting models!
When picking our initial set of models to test, we want to be mindful of a few things:
Pick a diverse set of initial models
Different classes of models are good at modeling different kinds of underlying patterns in data. So a good first step is to quickly test out a few different classes of models to know which ones capture the underlying structure of your dataset most efficiently! Within the realm of our problem type (regression, classification, clustering) we want to try a mixture of tree-based, instance-based, and kernel-based models. Pick a model from each class to test out. We’ll talk more about the different model types in the ‘models to try’ section below.
Try a few different parameters for each model
While we don’t want to spend too much time finding the optimal set of hyper-parameters, we do want to try a few different combinations of hyper-parameters to allow each model class to have the chance to perform well.
Pick the strongest contenders
We can use the best performing models from this stage to give us intuition around which class of models we want to further dive into. Your Weights and Biases dashboard will guide you to the class of models that performed best for your problem.
Dive deeper into models in the best performing model classes.
Next, we select more models belonging to the best performing classes of models we shortlisted above! For example, if linear regression seemed to work best, it might be a good idea to try lasso or ridge regression as well.
Explore the hyper-parameter space in more detail.
At this stage, I’d encourage you to spend some time tuning the hyper-parameters for your candidate models. (The next post in this series will dive deeper into the intuition around selecting the best hyper-parameters for your models.) At the end of this stage, you should have the best performing versions of all your strongest models.
Making the final selection — Kaggle
Pick final submissions from diverse models. Ideally, we want to select the best models from more than one class of models. This is because if you make your selections from just one class of models and it happens to be the wrong one, all your submissions will perform poorly. Kaggle competitions usually allow you to pick more than one entry for your final submission. I’d recommend choosing predictions made by your strongest models from different classes to build some redundancy into your submissions.
The leaderboard is not your friend, but your cross-validation scores are. The most important thing to remember is that the public leaderboard is not your friend. Picking your models solely based on your public leaderboard scores will lead to overfitting the training dataset. And when the private leaderboard is revealed after the competition ends, sometimes you might see your rank dropping a lot. You can avoid this little pitfall by using cross-validation when training your models. Then pick the models with the best cross-validation scores, instead of the best leaderboard scores. By doing this you counter overfitting by measuring your model’s performance against multiple validation sets instead of just the one subset of test data used by the public leaderboard.
Making the final selection — Real-world
Resource constraints. Different models hog different types of resources, and knowing whether you’re deploying the models on an IoT/mobile device with a small hard drive and processor or an in cloud can be crucial in picking the right model.
Training time vs. Prediction time vs. Accuracy. Knowing what metric(s) you’re optimizing for is also crucial for picking the right model. For instance, self-driving cars need blazing fast prediction times, whereas fraud detection systems need to quickly update their models to stay up to date with the latest phishing attacks. For other cases like medical diagnosis, we care about the accuracy (or area under the ROC curve) much more than the training times.
Complexity vs. Explainability Tradeoff. More complex models can use orders of magnitude more features to train and make predictions require more compute but if trained correctly can capture really interesting patterns in the dataset. This also makes them convoluted and harder to explain though. Knowing how important it is to easily explain the model to stakeholders vs capturing some really interesting trends while giving up explainability is key to picking a model.
Scalability. Knowing how fast and how big your model needs to scale can help you narrow down your choices appropriately.
Size of training data. For really large datasets or those with many features, neural networks or boosted trees might be an excellent choice whereas smaller datasets might be better served by logistic regression, Naive Bayes, or KNNs.
Number of parameters. Models with a lot of parameters give you lots of flexibility to extract really great performance. However, there may be cases where you don’t have the time required to, for instance, train a neural network’s parameters from scratch. A model that works well out of the box would be the way to go in this case!
Comparing Models
Weights and Biases lets you track and compare the performance of your models with one line of code.
Once you have selected the models you’d like to try, train them, and simply add wandb.log({‘score’: cv_score}) to log your model state. Once you’re done training, you can compare your model performances in one easy dashboard!
You can find the code to do this efficiently here. I encourage you to fork this kernel and play with the code!
That’s it now you have all the tools you need to pick the right models for your problem!
Model selection and can be very complicated, but I hope this guide sheds some light and gives you a good framework for picking models.
Original. Reposted with permission.
Bio: Lavanya is a machine learning engineer @ Weights and Biases. She began working on AI 10 years ago when she founded ACM SIGAI at Purdue University as a sophomore. In a past life, she taught herself to code at age 10, and built her first startup at 14. She's driven by a deep desire to understand the universe around us better by using machine learning.
Related: