 Three R Libraries Every Data Scientist Should Know (Even if You Use Python)
Three R Libraries Every Data Scientist Should Know (Even if You Use Python)
 Three R Libraries Every Data Scientist Should Know (Even if You Use Python)
Three R Libraries Every Data Scientist Should Know (Even if You Use Python)Check out these powerful R libraries built by the world’s biggest tech companies.
By Terence Shin, Data Scientist | MSc Analytics & MBA student

Photo by Denis Pavlovic on Unsplash
Introduction
For the longest time, I was quite against using R for no other reason other than the fact that it wasn’t Python.
But after playing around with R for the past few months, I realized that R outclasses Python in several use cases, particularly for statistical analyses. As well, R has some powerful packages that were built by the world’s biggest tech companies, and they aren’t in Python!
And so, in this article, I wanted to go over three R packages that I highly recommend that you take the time to learn and equip in your arsenal of tools because they are seriously powerful tools.
Without further ado, here are three R packages that every data scientist should know, EVEN IF YOU ONLY USE PYTHON:
- Causal Impact w/ Google
- Robyn w/ Facebook
- Anomaly Detection w/ Twitter
1. Causal Impact (Google)
Let’s say your company launched a new TV ad for the Super Bowl and they wanted to see how it impacted conversions. Causal impact analysis attempts to predict what would have happened if the campaign never occurred — this is called the counterfactual.
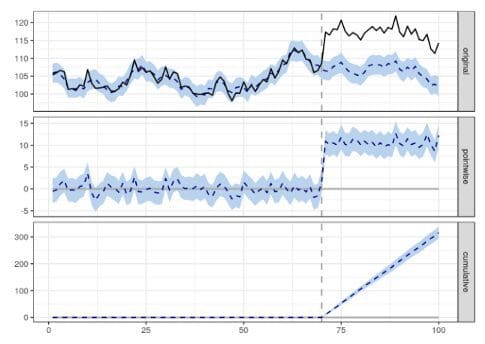
Image created by author
To give an actual example of what Causal impact does, it attempts to predict the counterfactual, i.e. the blue dotted line in the top graph, and then it compares the actual values to the counterfactual to estimate the delta.
Causal impact is super useful for marketing initiatives, expanding to new regions, testing new product features, and more!
2. Robyn (Facebook)
Marketing Mix Modelling is a modern technique used to estimate the impact of several marketing channels or campaigns on a target variable, like conversions or sales.
Marketing Mix Models (MMMs) are extremely popular, more than attribution models, because they allow you to measure the impact of immeasurable channels like TV, billboards, and radio.
Typically, Marketing Mix Models take months to build from scratch. But Facebook created a new R package, called Robyn, that can create a robust MMM in minutes.
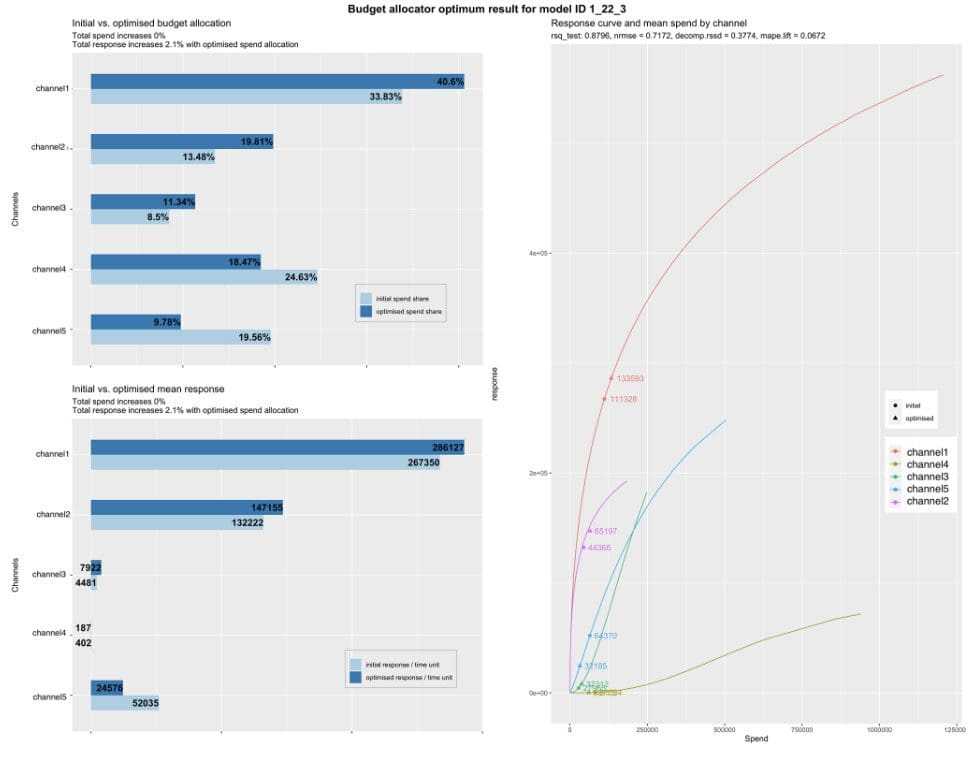
Image created by author
Not only can you assess the effectiveness of each marketing channel with Robyn, but you can also optimize your marketing budget with it too!
Be sure to subscribe here and to my personal newsletter to never miss another article on data science guides, tricks and tips, life lessons, and more!
3. Anomaly Detection (Twitter)
Anomaly detection, also known as outlier analysis, is a method that identifies data points that differ significantly from the rest of the data.
A subset of general anomaly detection is anomaly detection in time-series data, which is a unique problem because you have to consider the trend and seasonality of the data as well.
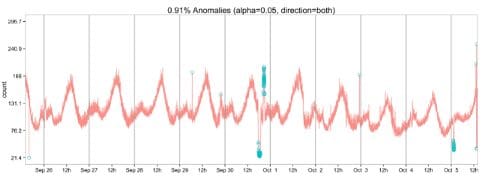
Image created by author
Twitter solved this problem by creating an anomaly detection package that does it all for you. It’s an intricate algorithm that can identify global and local anomalies. Aside from time series, it can also be used to detect anomalies in a vector of values.
Thanks for Reading!
If you enjoyed this be sure to subscribe here and to my exclusive newsletter to never miss another article on data science guides, tricks and tips, life lessons, and more!
Not sure what to read next? I’ve picked another article for you: The 10 Best Data Visualizations of 2021
and another one: All Machine Learning Algorithms You Should Know in 2022
Terence Shin
- If you enjoyed this, SUBSCRIBE to my Medium for exclusive content!
- Likewise, you can also FOLLOW me on Medium
- Sign up for my personal newsletter
- Follow me on LinkedIn for other content
Bio: Terence Shin is a data enthusiast with 3+ years of experience in SQL and 2+ years of experience in Python, and a blogger on Towards Data Science and KDnuggets.
Original. Reposted with permission.