Inside Pluribus: Facebook’s New AI That Just Mastered the World’s Most Difficult Poker Game
The reasons why Pluribus represents a major breakthrough in AI systems might result confusing to many readers. After all, in recent years AI researchers have made tremendous progress across different complex games. However, six-player, no-limit Texas Hold’em still remains one of the most elusive challenges for AI systems.

Poker has remained as one of the most challenging games to master in the fields of artificial intelligence(AI) and game theory. From the game theory-creator John Von Neumann writing about poker in his 1928 essay “Theory of Parlor Games, to Edward Thorp masterful book “Beat the Dealer” to the MIT Blackjack Team, poker strategies has been an obsession to mathematicians for decades. In recent years, AI has made some progress in poker environments with systems such as Libratus, defeating human pros in two-player no-limit Hold’em in 2017. Last week, a team of AI researchers from Facebook in collaboration with Carnegie Mellon University achieved a major milestone in the conquest of Poker by creating Pluribus, an AI agent that beat elite human professional players in the most popular and widely played poker format in the world: six-player no-limit Texas Hold’em poker.
The reasons why Pluribus represents a major breakthrough in AI systems might result confusing to many readers. After all, in recent years AI researchers have made tremendous progress across different complex games such as checkers, chess, Go, two-player poker, StarCraft 2, and Dota 2. All those games are constrained to only two players and are zero-sum games (meaning that whatever one player wins, the other player loses). Other AI strategies based on reinforcement learning have been able to master multi-player games Dota 2 Five and Quake III. However, six-player, no-limit Texas Hold’em still remains one of the most elusive challenges for AI systems.
Mastering the Most Difficult Poker Game in the World
The challenge with six-player, no-limit Texas Hold’em poker can be summarized in three main aspects:
- Dealing with incomplete information.
- Difficulty to achieve a Nash equilibrium.
- Success requires psychological skills like bluffing.
In AI theory, poker is classified as an imperfect-information environment which means that players never have a complete picture of the game. No other game embodies the challenge of hidden information quite like poker, where each player has information (his or her cards) that the others lack. Additionally, an action in poker in highly dependent of the chosen strategy. In perfect-information games like chess, it is possible to solve a state of the game (ex: end game) without knowing about the previous strategy (ex: opening). In poker, it is impossible to disentangle the optimal strategy of a specific situation from the overall strategy of poker.
The second challenge of poker relies on the difficulty of achieving a Nash equilibrium. Named after legendary mathematician John Nash, the Nash equilibrium describes a strategy in a zero-sum game in which a player in guarantee to win regardless of the moves chosen by its opponent. In the classic rock-paper-scissors game, the Nash equilibrium strategy is to randomly pick rock, paper, or scissors with equal probability. The challenge with the Nash equilibrium is that its complexity increases with the number of players in the game to a level in which is not feasible to pursue that strategy. In the case of six-player poker, achieving a Nash equilibrium is computationally impossible many times.
The third challenge of six-player, no-limit Texas Hold’em is related to its dependence on human psychology. The success in poker relies on effectively reasoning about hidden information, picking good action and ensuring that a strategy remains unpredictable. A successful poker player should know how to bluff, but bluffing too often reveals a strategy that can be beaten. This type of skills has remained challenging to master by AI systems throughout history.
Pluribus
Like many other recent AI-game breakthroughs, Pluribus relied on reinforcement learning models to master the game of poker. The core of Pluribus’s strategy was computed via self-play, in which the AI plays against copies of itself, without any data of human or prior AI play used as input. The AI starts from scratch by playing randomly, and gradually improves as it determines which actions, and which probability distribution over those actions, lead to better outcomes against earlier versions of its strategy.
Differently from other multi-player games, any given position in six-player, no-limit Texas Hold’em can have too many decision points to reason about individually. Pluribus uses a technique called abstraction to group similar actions together and eliminate others reducing the scope of the decision. The current version of Pluribus uses two types of abstractions:
- Action Abstraction: This type of abstraction reduces the number of different actions the AI needs to consider. For instance, betting $150 or $151 might not make a difference from the strategy standpoint. To balance that, Pluribus only considers a handful of bet sizes at any decision point.
- Information Abstraction: This type of abstraction groups decision points based on the information that has been revealed. For instance, a ten-high straight and a nine-high straight are distinct hands, but are nevertheless strategically similar. Pluribus uses information abstraction only to reason about situations on future betting rounds, never the betting round it is actually in.
To automate self-play training, the Pluribus team used a version of the of the iterative Monte Carlo CFR (MCCFR) algorithm. On each iteration of the algorithm, MCCFR designates one player as the “traverser” whose current strategy is updated on the iteration. At the start of the iteration, MCCFR simulates a hand of poker based on the current strategy of all players (which is initially completely random). Once the simulated hand is completed, the algorithm reviews each decision the traverser made and investigates how much better or worse it would have done by choosing the other available actions instead. Next, the AI assesses the merits of each hypothetical decision that would have been made following those other available actions, and so on. The difference between what the traverser would have received for choosing an action versus what the traverser actually achieved (in expectation) on the iteration is added to the counterfactual regret for the action. At the end of the iteration, the traverser’s strategy is updated so that actions with higher counterfactual regret are chosen with higher probability.
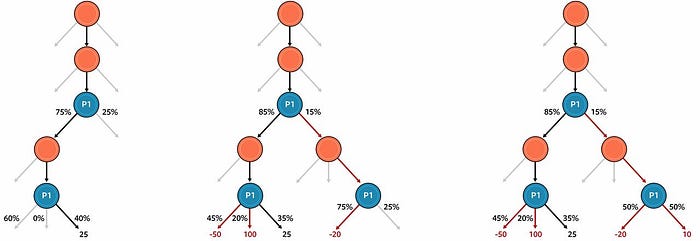
The outputs of the MCCFR training are known as the blueprint strategy. Using that strategy, Pluribus was able to master poker in eight days on a 64-core server and required less than 512 GB of RAM. No GPUs were used.
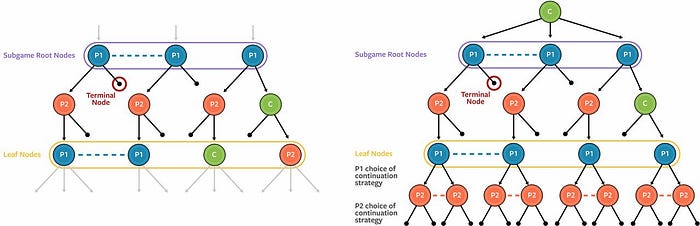
The blueprint strategy is too expensive to use real time in a poker game. During actual play, Pluribus improves upon the blueprint strategy by conducting real-time search to determine a better, finer-grained strategy for its particular situation. Traditional search strategies are very challenging to implement in imperfect information games in which the players can change strategies at any time. Pluribus instead uses an approach in which the searcher explicitly considers that any or all players may shift to different strategies beyond the leaf nodes of a subgame. Specifically, rather than assuming all players play according to a single fixed strategy beyond the leaf nodes, Pluribus assumes that each player may choose among four different strategies to play for the remainder of the game when a leaf node is reached. This technique results in the searcher finding a more balanced strategy that produces stronger overall performance.
Pluribus in Action
Facebook evaluated Pluribus by playing against an elite group of players that included several World Series of Poker and World Poker Tour champions. In one experiment, Pluribus played 10,000 hands of poker against five human players selected randomly from the pool. Pluribus’s win rate was estimated to be about 5 big blinds per 100 hands (5 bb/100), which is considered a very strong victory over its elite human opponents (profitable with a p-value of 0.021). If each chip was worth a dollar, Pluribus would have won an average of about $5 per hand and would have made about $1,000/hour.
The following figure illustrates Pluribus’ performance. On the top chart, the solid lines show the win rate plus or minus the standard error. The bottom chart shows the number of chips won over the course of the games.

Pluribus represents one of the major breakthroughs in modern AI systems. Even though Pluribus was initially implemented for poker, the general techniques can be applied to many other multi-agent systems that require both AI and human skills. Just like AlphaZero is helping to improve professional chess, its interesting to see how poker players can improve their strategies based on the lessons learned from Pluribus.
Original. Reposted with permission.
Related:
- Top 10 Best Podcasts on AI, Analytics, Data Science, Machine Learning
- State of AI Report 2019
- Decentralized and Collaborative AI: How Microsoft Research is Using Blockchains to Build More Transparent Machine Learning Models