Research Guide for Depth Estimation with Deep Learning
In this guide, we’ll look at papers aimed at solving the problems of depth estimation using deep learning.
Depth estimation is a computer vision task designed to estimate depth from a 2D image. The task requires an input RGB image and outputs a depth image. The depth image includes information about the distance of the objects in the image from the viewpoint, which is usually the camera taking the image.
Some of the applications of depth estimation include smoothing blurred parts of an image, better rendering of 3D scenes, self-driving cars, grasping in robotics, robot-assisted surgery, automatic 2D-to-3D conversion in film, and shadow mapping in 3D computer graphics, just to mention a few.
In this guide, we’ll look at papers aimed at solving these problems using deep learning. The two images below provide a clear illustration of depth estimation in practice.


Deeper Depth Prediction with Fully Convolutional Residual Networks (IEEE 2016)
This paper proposes a fully convolutional architecture to address the problem of estimating the depth map of a scene given an RGB image. Modeling of the ambiguous mapping between monocular images and depth maps is done via residual learning. The reverse Huber loss is used for optimization. The model runs in real-time on images or videos.
Deeper Depth Prediction with Fully Convolutional Residual Networks
This paper addresses the problem of estimating the depth map of a scene given a single RGB image. We propose a fully…
The approach proposed in this paper uses a CNN for depth estimation. The model is fully convolutional and includes efficient residual up-sampling blocks — up-projections — that track high-dimensional regression problems.
The first section of the network is based on ResNet50 and is initialized with pre-trained weights. The second part is a sequence of convolutional and unpooling layers that guide the network in learning its upscaling. Dropout is then applied, followed by a final convolution that yields the final prediction.

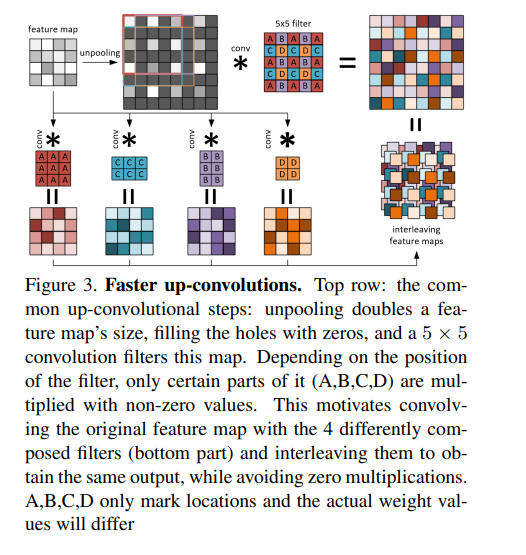
The unpooling layers increase the spatial resolution of feature maps. Unpooling layers are implemented so as to double the size by mapping each entry into the top-left corner of a 2 x 2 kernel. Each such layer is followed by a 5 x 5 convolution. This block is referred to as up-convolution. A simple 3 × 3 convolution is added after the up-convolution. A projection connection is added from the lower resolution feature map to the result.

The authors also recalibrate the up-convolution operation in order to decrease training time of the network by at least 15%. As seen in the figure below, in the top left, the original feature map is unpooled and convolved by a 5 x 5 filter.
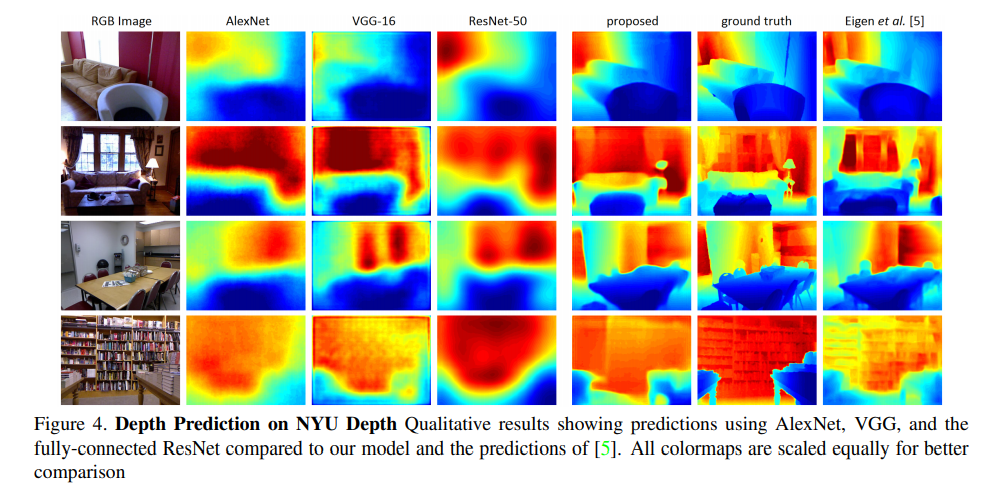
Here’s how the proposed model performs on the NYU Depth v2 dataset compared to other models.

Unsupervised Learning of Depth and Ego-Motion from Video (CVPR 2017)
The authors present an unsupervised learning framework for the task of monocular depth and camera motion estimation from unstructured video sequences. The method uses single-view depth and multi-view pose networks. Loss is based on warping nearby views to the target using the computed depth and pose.

Unsupervised Learning of Depth and Ego-Motion from Video
We present an unsupervised learning framework for the task of monocular depth and camera motion estimation from…
The authors propose a framework for jointly training a single-view depth CNN and a camera pose estimation CNN from unlabeled video sequences. The supervision pipeline is based on view synthesis. The depth network takes the target view as the input and outputs a per-pixel depth map. A target view can be synthesized given per-pixel depth in an image and the pose & visibility in a nearby view. This synthesis can be implemented in a fully differentiable manner with CNNs as the geometry and pose estimation modules.

The authors adopt the DispNet architecture, which is an encoder-decoder design with skip connections and multi-scale side predictions. A ReLU activation follows all convolution layers except the prediction ones.
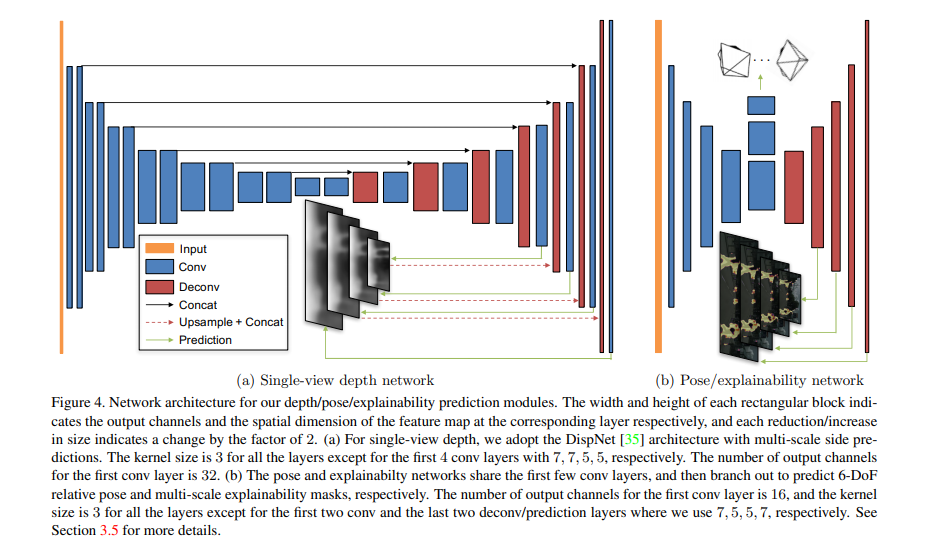
The target view concatenated with all the source views forms the input to the pose estimation network. The output is the relative pose between the target view and each of the source views. The network is made up of 7 stride-2 convolutions followed by a 1 x 1 convolution with 6 ∗ (N −1) output channels. These correspond to 3 Euler angles and 3-D translation for each source. The global average is applied to aggregate predictions at all spatial locations. Apart from the last convolution layer, where a nonlinear activation is applied, all the others are followed by a ReLU activation function.
The explainability prediction network shares the first five feature encoding layers with the pose network. This is followed by 5 deconvolution layers with multi-scale side predictions. Apart from the prediction layers, all the conv/deconv layers are followed by ReLU.

Here’s how this model performs in comparison to other models.

Did you know: Machine learning can help add amazing image effects to mobile apps. From removing backgrounds, to adding artistic styles, and beyond, Fritz AI makes it easy to build ML-powered photo editing tools.
Unsupervised Monocular Depth Estimation with Left-Right Consistency (CVPR 2017)
This paper proposes a convolutional neural network that’s trained to perform single image depth estimation without ground-truth depth data. The authors propose a network architecture that performs end-to-end unsupervised monocular depth estimation with a training loss that enforces left-right depth consistency inside the network.
Unsupervised Monocular Depth Estimation with Left-Right Consistency
Learning based methods have shown very promising results for the task of depth estimation in single images. However…

The network estimates depth by inferring disparities that warp the left image to match the right one. The left input image is used to infer the left-to-right and right-to-left disparities. The network generates the predicted image with backward mapping using a bilinear sampler. This results in a fully differentiable image formation model.
The convolutional architecture is inspired by DispNet. It’s made up of two parts—an encoder and a decoder. The decoder uses skip connections from the encoder’s activation blocks to resolve higher resolution details. The network predicts two disparity maps — left-to-right and right-to-left.
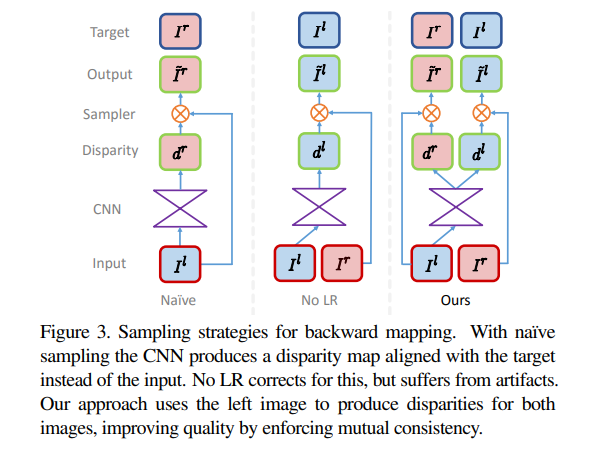
In the training process, the network generates an image by sampling pixels from the opposite stereo image. The image formation model uses the image sampler from the spatial transformer network (STN) to sample the input image using a disparity map. The bilinear sample used is locally differentiable.
Here are the results obtained on the KITTI 2015 stereo 200 training set disparity images.


Unsupervised Learning of Depth and Ego-Motion from Monocular Video Using 3D Geometric Constraints (2018)
The authors propose a method for unsupervised learning of depth and ego-motion from single-camera videos. It takes into consideration the inferred 3D geometry of the whole scene and enforces the consistency of the estimated 3D point clouds and ego-motion across consecutive frames. A backpropagation algorithm is used for aligning 3D structures. The model is tested on the KITTI dataset and a video dataset captured on a mobile phone camera.
Unsupervised Learning of Depth and Ego-Motion from Monocular Video Using 3D Geometric Constraints
We present a novel approach for unsupervised learning of depth and ego-motion from monocular video. Unsupervised…
Learning depth in an unsupervised manner relies on the existence of ego-motion in the video. The network produces a single-view depth estimate given two consecutive frames from a video. An ego-motion estimate is also produced from the pair.
Supervision for the training model is achieved by requiring the depth and ego-motion estimates from adjacent frames to be consistent. The authors propose a loss that penalizes inconsistencies in the estimated depth without relying on backpropagation via image reconstruction.

Here are the results obtained on the KITTI Eigen test set.

Deep learning — For experts, by experts. We’re using our decades of experience to deliver the best deep learning resources to your inbox each week.
Depth Prediction Without the Sensors: Leveraging Structure for Unsupervised Learning from Monocular Videos (AAAI 2019)
This paper is concerned with the task of unsupervised learning of scene depth and robot ego-motion, where supervision is provided by monocular videos. This is done by introducing geometric structure in the learning process. It involves modeling the scene and the individual objects, camera ego-motion and object motions learned from monocular video inputs. The authors also introduce an online refinement method.
Depth Prediction Without the Sensors: Leveraging Structure for Unsupervised Learning from Monocular…
Learning to predict scene depth from RGB inputs is a challenging task both for indoor and outdoor robot navigation. In…
The authors introduce an object motion model that shares the same architecture as the ego-motion network. It is, however, specialized for predicting motions of individual objects in 3D. It takes an RGB image sequence as input. It’s complemented by pre-computed instance segmentation masks. The work of the motion model is to learn to predict the transformation vectors per object in 3D space. This creates the observed object appearance in the respective target frame.
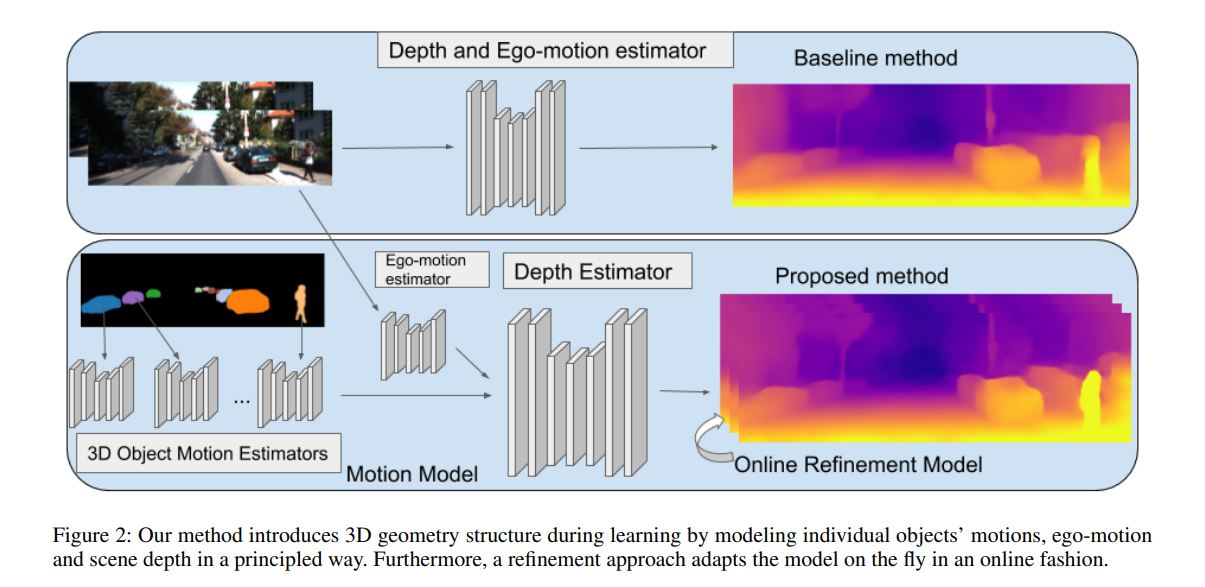
The figure below shows the results obtained using this model.

PlaneNet: Piece-wise Planar Reconstruction from a Single RGB Image (CVPR 2018)
This paper presents a deep neural network (DNN) for piecewise planar depth map reconstruction from a single RGB image. The proposed DNN learns to infer a set of plane parameters and the corresponding plane segmentation masks from a single RGB image.
The proposed deep neural architecture — PlaneNet — learns to directly produce a set of plane parameters and probabilistic plane segmentation masks from a single RGB image. The loss function defined is agnostic to the order of planes. Furthermore, the network predicts a depth map at non-planar surfaces whose loss is defined via the probabilistic segmentation masks to allow backpropagation.

PlaneNet: Piece-wise Planar Reconstruction from a Single RGB Image
This paper proposes a deep neural network (DNN) for piece-wise planar depthmap reconstruction from a single RGB image…
PlaneNet is built upon Dilated Residual Networks (DRNs). Three output branches for the three prediction tasks are composed given the high-resolution final feature maps from DRN. These are plane parameters, non-planar depth maps, and segmentation masks.
The plane parameter branch has a global average pooling to reduce the feature map size to 1 x 1. This is followed by a fully connected layer to produce K×3 plane parameters. K is the predicted constant number of planes. An order-agnostic loss function based on the Chamfer distance metric for the regressed plane parameters is then defined.
The plane segmentation branch starts with a pyramid pooling module that’s followed by a convolutional layer to produce channel likelihood maps for planar and non-planar surfaces. A dense conditional random field (DCRF) module is appended based on the fast inference algorithm. The DCRF module is jointly trained with the preceding layers. A standard softmax cross-entropy loss is used to supervise the segmentation training.
The non-planar depth branch shares the same pyramid pooling module followed by a convolution layer that produces a 1-channel depth map.

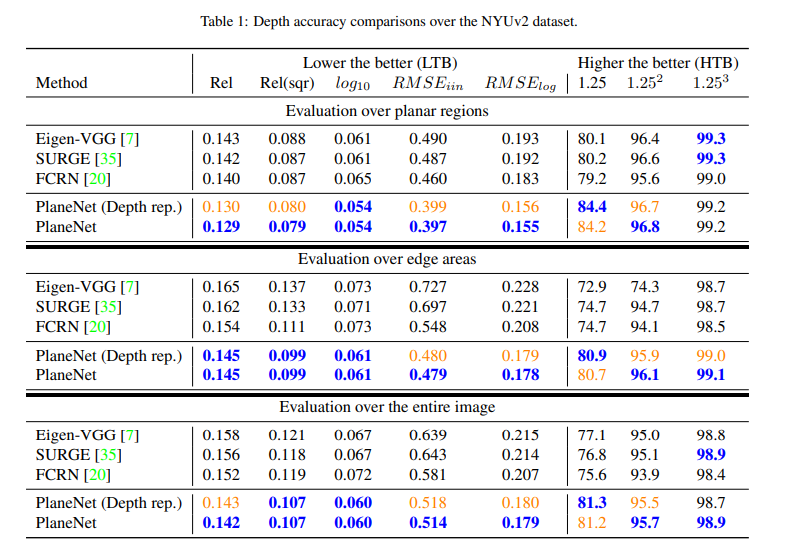
Here are the depth accuracy comparisons over the NYUv2 dataset.
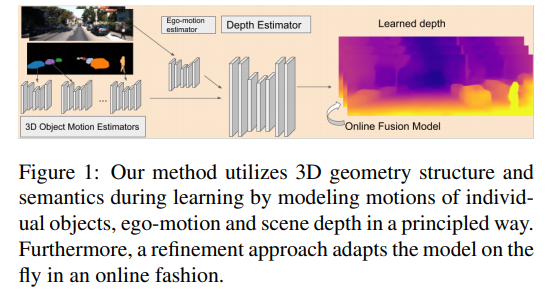
Unsupervised Monocular Depth and Ego-motion Learning with Structure and Semantics (AAAI 19)
The approach proposed in this paper incorporates both structures and semantics for unsupervised monocular learning of depth and ego-motion.
Unsupervised Monocular Depth and Ego-motion Learning with Structure and Semantics
We present an approach which takes advantage of both structure and semantics for unsupervised monocular learning of…
The approach proposed in this paper is able to model dynamic scenes by modeling object motion and can also adapt to an optional online refinement technique. Modeling of individual object motions enables the method to handle highly dynamic scenes. This is done by introducing a third component to the model that predicts motions of objects in 3D. It utilizes the same network structure as the ego-motion network but trains to separate weights. The motion model predicts the transformation vectors per object in 3D-space. This creates the observed object appearance in the respective target frame when applied to the camera. The final warping result is a combination of the individual warping from moving objects and the ego-motion. The ego-motion is computed by masking out the object motions of the images first.

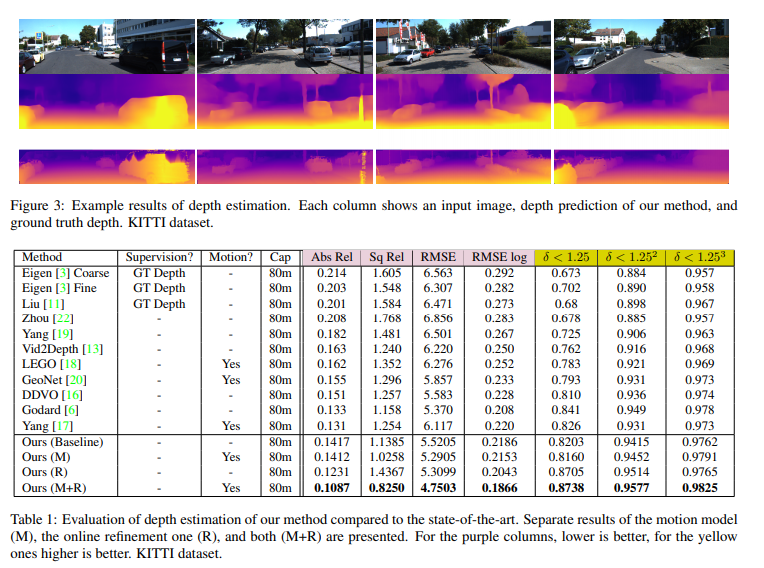
Here are the results obtained on the KITTI dataset.
Learning the Depths of Moving People by Watching Frozen People (CVPR 2019)
The method presented in this paper predicts dense depth in situations where both a monocular camera and people in the scene are freely moving. The approach starts with learning human depth from internet videos of people imitating mannequins. The method uses motion parallax cues from the static areas of the scenes to guide depth predictions.

Learning the Depths of Moving People by Watching Frozen People
We present a method for predicting dense depth in scenarios where both a monocular camera and people in the scene are…
Derived 3D data from YouTube is used as supervision for training. These videos form the new Mannequin Challenge (MC) dataset. The authors design a deep neural network that takes an RGB image, a mask of human regions, and an initial depth of the environment as input.
It then outputs a dense depth map over the entire image. The depth maps produced by this model can be used to produce 3D effects such as synthetic depth-of-field, depth-aware inpainting, and inserting virtual objects into the 3D scene with correct occlusion
The depth prediction model on the MannequinChallenge dataset is done in a supervised manner. The full input to the network includes a reference image, a binary mask of human regions, a depth map estimated from motion parallax, a confidence map, and an optional human keypoint map. With these inputs, the network predicts the full depth map for the whole scene. The network architecture is a variant of the hourglass network with the nearest neighbor upsampling layers replaced by bilinear upsampling layers.

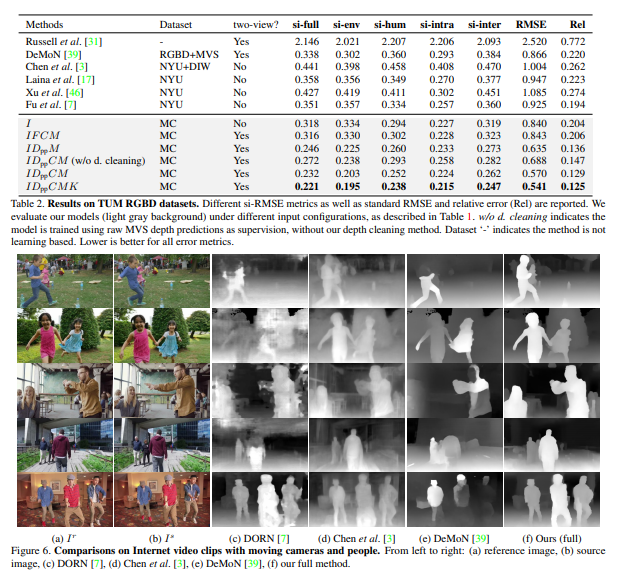
Here are the results obtained from this model.
Conclusion
We should now be up to speed on some of the most common — and a couple of very recent — techniques for performing depth estimation in a variety of contexts.
The papers/abstracts mentioned and linked to above also contain links to their code implementations. We’d be happy to see the results you obtain after testing them.
Bio: Derrick Mwiti is a data analyst, a writer, and a mentor. He is driven by delivering great results in every task, and is a mentor at Lapid Leaders Africa.
Original. Reposted with permission.
Related:
- Research Guide for Neural Architecture Search
- Research Guide: Advanced Loss Functions for Machine Learning Models
- Research Guide for Transformers