Disentangling disentanglement: Ideas from NeurIPS 2019
This year’s NEURIPS-2019 Vancouver conference recently concluded and featured a dozen papers on disentanglement in deep learning. What is this idea and why is it so interesting in machine learning? This summary of these papers will give you initial insight in disentanglement as well as ideas on what you can explore next.
By Vinay Prabhu, Chief Scientist, UnifyID.

Credit: ‘ Striving for Disentanglement’ by Simon Greig.
Disentanglement in Representation learning
On Thursday evening of the conference week, as I sauntered around the poster session in the massive east exhibition halls of the Vancouver convention center, I realized that I had chanced upon probably the 5th poster in the past couple of days entailing analysis of a disentanglement framework the authors had worked on.

Figure 1: (Yet another) Poster on disentanglement at this year’s NEURIPS.
A quick check in the proceedings led me to this stunning statistic: A total of I-KID-YOU-NOT dozen papers were accepted this year with the term ‘DISENTANGLEMENT’ in the title. There were at least a few more that I chanced upon in the multitude of workshops. (There were 20+ papers and talks during the 2017 NEURIPS workshop on Learning Disentangled Representations: from Perception to Control, and we had a challenge workshop this year as well.)
I had first encountered this flavor of usage of the term in statistical learning during the last stages of my doctoral journey at CMU (circa 2013) when I read ‘Deep Learning of Representations: Looking Forward’ by Yoshua Bengio in which he emphasized the need to be ‘.. learning to disentangle the factors of variation underlying the observed data’. (How I wish he still authored such single-author papers.)
As it turns out, much to the chagrin of the physicists perhaps, if you are working on teasing out visual style from digit type on MNIST, or separating shape and pose in images of human bodies and facial features from facial shape on CelebA or grappling with unwrapping the effects of mixture ratio of the two constituent compounds and environmental factors such as thermal fluctuation in images generated for microstructure growth, you are disentangling.
There seems to be no consensus on what the term precisely means or what metric(s) capture the extent of it, an observation that is confirmed by this rather funny/snarky slide in Stafano Soatto’s talk at IPAM (refer to the playlist below).

Figure 2: Invariance and disentanglement in deep representations.
That said, this is not a case of there existing a mere smattering of empirical experiments that all use their own customized notion of disentanglement. In fact, reasonably rigorous frameworks have been proposed harnessing powerful tools from areas such as Variational inference, Shannonian Information theory, Group theory, and matrix factorization. Deepmind’s group theoretic treatment of the same seems to have perched itself as one of the go-to frameworks. In case you are looking for a succinct 3 min recap of what this is, please refer to this video that I saw during one of Simons Institute workshops (around the 7th minute). (A very detailed talk from one of the main authors of the Deepmind group can be found here).
Figure 3: Group theoretic framework for disentanglement.
A bird’s view of the papers presented
In Fig 4 below is a bird’s-eye view of the 12 papers presented. I roughly bucketed them into two subsections depending on whether the main perceived goal of the paper (from my humble viewpoint) was to either analyze and/or critique the properties of a pre-existing framework or to harness one and apply the same to an interesting problem domain. Bear in mind that this is admittedly a rather simplistic categorization and this is not very instructive of whether the applications oriented papers did or did not critique and analyze the frameworks used or that the analysis/critique papers did not include real-world applications.
Figure 4: Disentanglement papers categorization (NEURIPS -2019).
(You can find the pdf version with the paper links here.)
What do they mean by disentanglement?
In order to summarize the contexts in which disentanglement was used in these papers, I created a look-up-table (See Table 1). In those cases where the authors explicitly did not have a subsection dedicated to defining the same, I improvised and extracted the gist (and hence the caveat [improv]).

Table 1(a): Disentanglement context in the application papers.
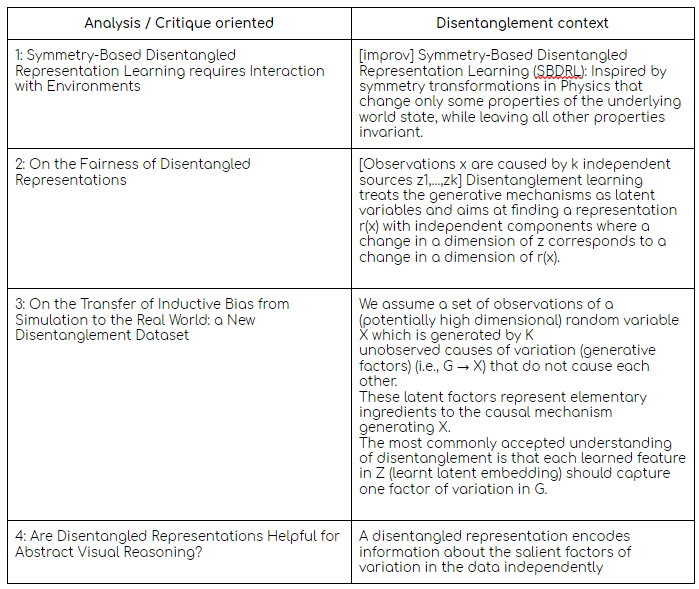
Table 1(b): Disentanglement context in the analysis papers.
Reproducibility and open-sourced code
Given the strong growing trend towards open-sourcing the code used to produce the results, 10 of the 12 author-groups shared their GitHub repos as well. This is captured in Table 2 below:
Table 2: Papers and the open-source code links.
What now? Some ideas..
[Here are some scribbles to try and guilt myself into working on this more seriously. Please take these with a grain of salt or 12 :) ]
1: Survey paper detailing the definitions, frameworks and metrics to be used.
2: Disentangling author/writing style/nation of origin using Kannada-MNIST dataset. (65 native volunteers from India and 10 non-native volunteers from the USA.)
3: It’s somewhat surprising that no one’s tried throwing a K user interference channel model for entanglement and see if an Interference Alignment-like trick works for Dsprites-like datasets
4: Disentangling Shoe type, pocket and device location from Gait representations
5: Bridging the body of work pertaining to (Hyperspectral) Unmixing / Blind source separation and disentangled representation learning.
Resource list:
Companion Github repo replete with paper summaries and cheat sheets:
https://github.com/vinayprabhu/Disentanglement_NEURIPS_2019/
A. Datasets to get started with:
[1] https://www.github.com/cianeastwood/qedr
[2] https://github.com/deepmind/dsprites-dataset
[3] https://github.com/rr-learning/disentanglement_dataset
(Major props to the NeurIPS 2019: Disentanglement Challenge organizers for the resources they shared as well! )
Link: https://www.aicrowd.com/challenges/neurips-2019-disentanglement-challenge
google-research/disentanglement_lib
B. Video playlist:
[1] Y. Bengio’s: From Deep Learning of Disentangled Representations to Higher-level Cognition
https://www.youtube.com/watch?v=Yr1mOzC93xs&t=355s
[2] \beta-VAE (Deepmind): https://www.youtube.com/watch?v=XNGo9xqpgMo
[3] Flexibly Fair Representation Learning by Disentanglement: https://www.youtube.com/watch?v=nlilKO1AvVs&t=27s
[4] Disentangled Representation Learning GAN for Pose-Invariant Face Recognition: https://www.youtube.com/watch?v=IjsBTZqCu-I
[5] Invariance and disentanglement in deep representations (Fun talk), https://www.youtube.com/watch?v=zbg49SMP5kY
(From NEURIPS 2019 authors)
[1] The Audit Model Predictions paper: https://www.youtube.com/watch?v=PeZIo0Q_GwE
[2] Twiml interview of Olivier Bachem (3 papers on this topic at NEURIPS-19): https://www.youtube.com/watch?v=Gd1nL3WKucY
c. Cheatsheets
Cheat sheet 1: All the abstracts! (Print on A3/2).
Cheat sheet 2: All the essences!
Original. Reposted with permission.
Bio: Vinay Prabhu is currently on a mission to model human kinematics using motion sensors on smartphones paving the way for numerous breakthroughs in areas such as passive password-free authentication, geriatric care, neuro-degenerative disease modeling, fitness, and augmented reality. He is currently the Chief Scientist at UnifyID Inc and has over 30 peer reviewed publications in areas spanning Physical layer wireless communications, Estimation theory, Information Theory, Network Sciences, and Machine Learning. His recent research projects include Deep Connectomics networks, Grassmannian initialization, SAT: Synthetic-seed-Augment-Transfer framework and the Kannada-MNIST dataset. He holds a PhD from Carnegie Mellon University and an MS from Indian Institute of Technology-Madras.
Related: