Why BERT Fails in Commercial Environments
The deployment of large transformer-based models in dynamic commercial environments often yields poor results. This is because commercial environments are usually dynamic, and contain continuous domain shifts between inference and training data.
By Oren Pereg, Moshe Wasserblat & Daniel Korat, Intel AI
Large transformer-based neural networks such as BERT, GPT and XLNET have recently achieved state-of-the-art results in many NLP tasks. The success of these models is based on transfer learning between a generic task (for example, language modeling) and a specific downstream task. These models perform remarkably well on static evaluation sets where labelled data is available. However, deployment of these models in dynamic commercial environments often yields poor results. This is because commercial environments are usually dynamic, and contain continuous domain shifts (e.g. new themes, new vocabulary or new writing styles) between inference and training data.
The traditional way of dealing with these dynamic environments is to perform continuous re-training and validation, requiring continuous manual data labeling which is time-consuming, costly and therefore impractical. One promising path to achieve better robustness and scalability in data-scarce commercial environments is to embed domain-independent knowledge in the pre-trained models during the fine-tuning stage.
Pre-trained Models Shine in Low Resource Environments
In practice, many commercial setups run the same task on multiple domains. Consider for example, sentiment analysis of two different products such as cameras (domain A) and laptops (domain B). In this case, the amount of existing labeled data for the different domains is often very small, and it is both costly and impractical to produce additional labeled data.
A major advantage of pre-trained models is their ability to adapt to specific tasks by using relatively small amounts of labeled data, compared to training a model from scratch (see Figure 1). This advantage plays an important role in practical multi-domain environments.
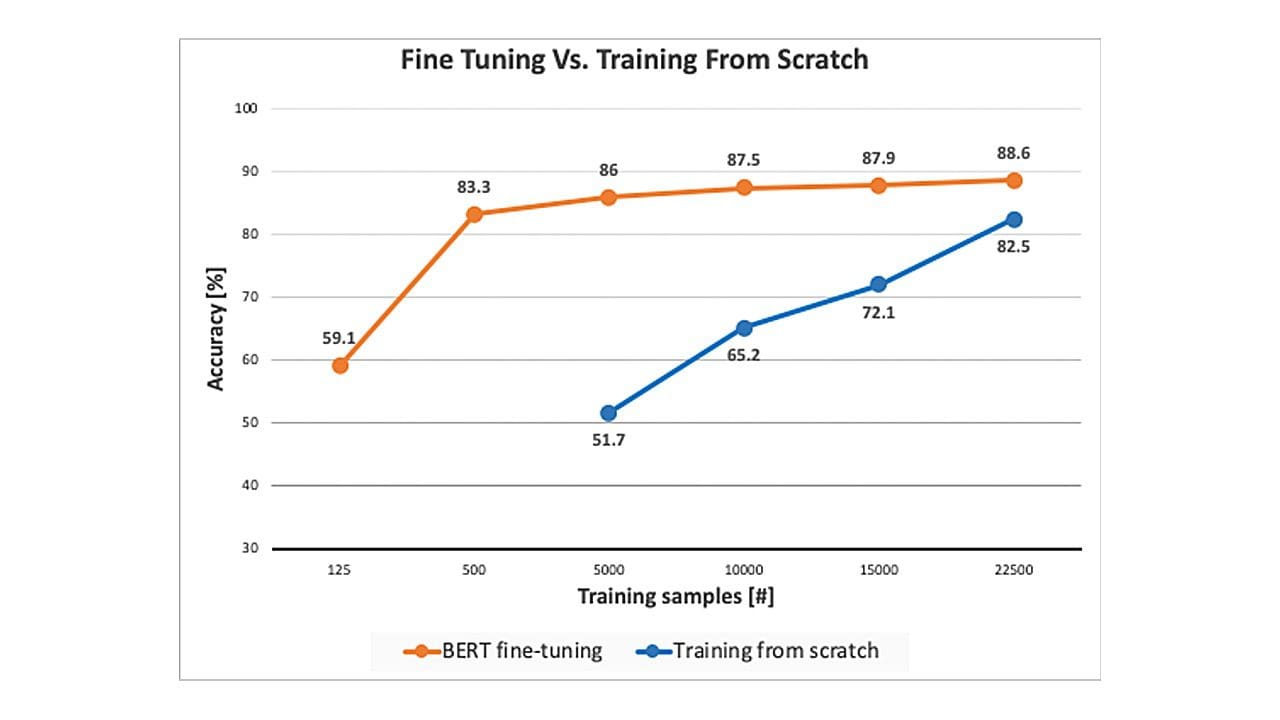
But what enables this enhanced capability of fine-tuned pre-trained models to be successful in low data environments? Part of the answer lies in the fact that during the massive pre-training step, the network learns structural language traits, such as syntax. Because syntax is a generic trait, it is both task-independent and domain-independent. This generic “knowledge” helps to bridge the gap between different tasks and domains and is leveraged by the fine-tuning step for data efficiency.
A recent work titled “What Does BERT Look At?” has shed some light on what BERT learns during pre-training. From this analysis of BERT’s self-attention mechanism, it is evident that BERT learns a substantial amount of linguistic knowledge. For example, some of BERT’s attention-heads attend to the direct objects of verbs, determiners of nouns such as definite articles, and even coreferent mentions (see Figure 2). It is remarkable that a model that was trained in an unsupervised manner and without any labeled data is able to learn generic aspects of a language.

Do Pre-trained Models Solve the Dynamic Commercial Environments Challenge?
In some dynamic commercial environments, it is not practical to produce any labeled data at all. Consider an environment in which new domains are frequently being added or changed. In this case, constantly labeling new training data would be an ineffective and never-ending task. These cases require unsupervised domain adaptation systems that use existing labeled data from one domain (source domain) for training, and then perform inference on unlabeled data from another domain (target domain).
We observed that pre-trained models excel in cases where there are small amounts of target-domain labeled data (Figure 1), but what about cases where there isn’t any labeled data from the target domain at all? How do pre-trained models perform in those environments? To date, using pre-trained models has shown only a small improvement over training from scratch (see blue vs. orange bar in Figure 3). The large gap between fine-tuning BERT using labeled target domain data (green bar) and both fine-tuning BERT or training an RNN from scratch using only source domain data (blue and orange bars) suggests that the information learned by the pre-trained models during pre-training yields some enhancement over training from scratch, but it is not sufficient for scaling across domains when labeled data from the target domain is unavailable. Or to put it more bluntly: the unsupervised domain adaptation problem is still far from being solved by fine-tuning pre-trained models using only source domain data.
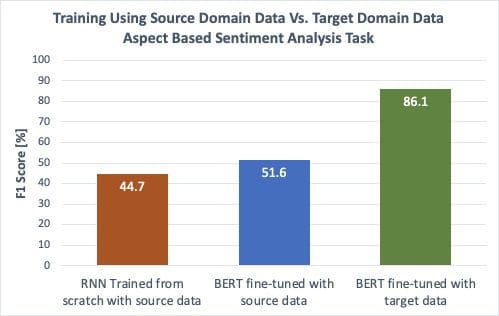
- The orange bar represents training an RNN from scratch using source domain data (laptop reviews) and performing inference using the target domain data (restaurant reviews).
- The blue bar represents fine-tuning BERT using source domain data.
- The green bar represents fine-tuning BERT using target domain data.
Source: Intel AI Lab. Configuration: Intel Xeon E5-2699A v4 CPU @ 2.40GHz. Testing done by Intel on February 27, 2020.
A Step Towards Closing the Gap: Embedding Structural Information
So what can be done in order to close the gap between in-domain and fully cross-domain environments? In an open discussion between Yann LeCun and Christopher Manning, Manning argued that providing structural information enables us to design systems that can learn more from less data, and at a higher level of abstraction, compared to systems lacking structural information. This view is broadly supported by the NLP community.
Indeed, a recent line of work shows that using structural information, namely syntactic information, improves the generalization models. This improved generalization enhances the robustness of the model for in-domain setups and even more so for cross-domain setups. For example, in one of the most prominent recent works introducing the LISA (Linguistically-Informed Self-Attention) model, the authors showed that embedding syntactic dependency parsing information significantly improved the accuracy of an SRL task in a cross-domain setup. The authors embedded the syntactic information directly in the attention heads of a transformer network and trained it from scratch.
Another recent work showed that models that use dependency relations and coreference chains as auxiliary supervision embedded in self-attention outperforms the largest GPT-2 model in a cloze test task. Other works show better generalization for tasks such as coreference resolution and Neural Machine Translation (NMT).
These recent advancements take us one step closer to achieving better robustness and scalability in data-scarce commercial environments, but there are still open questions and challenges that need to be addressed by the NLP community. What types of external information should be used? How should this information be embedded in pre-trained models?
Conclusion
Large transformer-based pre-trained models have recently achieved state-of-the-art results in many NLP tasks. These models, which were trained for a general language modeling task, learn some basic structural traits of the language which makes them generalize better across domains. They perform remarkably well in cross-domain setups when given small amounts of labeled target-domain data. However, the challenge of dealing with dynamic cross-domain setups in which there is no labeled target-domain data, still remains. Embedding external domain-independent knowledge, namely syntactic information, in pre-trained models during the fine-tuning stage holds great promise for achieving better robustness and scalability in data-scarce commercial environments.
Notices & Disclaimers
Software and workloads used in performance tests may have been optimized for performance only on Intel microprocessors. Performance tests, such as SYSmark and MobileMark, are measured using specific computer systems, components, software, operations and functions. Any change to any of those factors may cause the results to vary. You should consult other information and performance tests to assist you in fully evaluating your contemplated purchases, including the performance of that product when combined with other products. For more complete information visit www.intel.com/benchmarks.
Performance results are based on testing as of dates shown in configurations and may not reflect all publicly available security updates. No product or component can be absolutely secure. For more complete information about performance and benchmark results, visit www.intel.com/benchmarks.
Intel technologies may require enabled hardware, software or service activation. Your costs and results may vary.
© Intel Corporation. Intel, the Intel logo, and other Intel marks are trademarks of Intel Corporation or its subsidiaries. Other names and brands may be claimed as the property of others.
Original. Reposted with permission.
Related:
- BERT is changing the NLP landscape
- Intent Recognition with BERT using Keras and TensorFlow 2
- BERT, RoBERTa, DistilBERT, XLNet: Which one to use?