BERT, RoBERTa, DistilBERT, XLNet: Which one to use?
Lately, varying improvements over BERT have been shown — and here I will contrast the main similarities and differences so you can choose which one to use in your research or application.
By Suleiman Khan, Ph.D., Lead Artificial Intelligence Specialist
Google’s BERT and recent transformer-based methods have taken the NLP landscape by a storm, outperforming the state-of-the-art on several tasks. Lately, varying improvements over BERT have been shown — and here I will contrast the main similarities and differences so you can choose which one to use in your research or application.
BERT is a bi-directional transformer for pre-training over a lot of unlabeled textual data to learn a language representation that can be used to fine-tune for specific machine learning tasks. While BERT outperformed the NLP state-of-the-art on several challenging tasks, its performance improvement could be attributed to the bidirectional transformer, novel pre-training tasks of Masked Language Model and Next Structure Prediction along with a lot of data and Google’s compute power. If you are not yet familiar with BERT’s basic technology, I recommend reading this 3-minute blog post quickly.
Lately, several methods have been presented to improve BERT on either its prediction metrics or computational speed, but not both.
XLNet and RoBERTa improve on the performance while DistilBERT improves on the inference speed. The table below compares them for what they are!
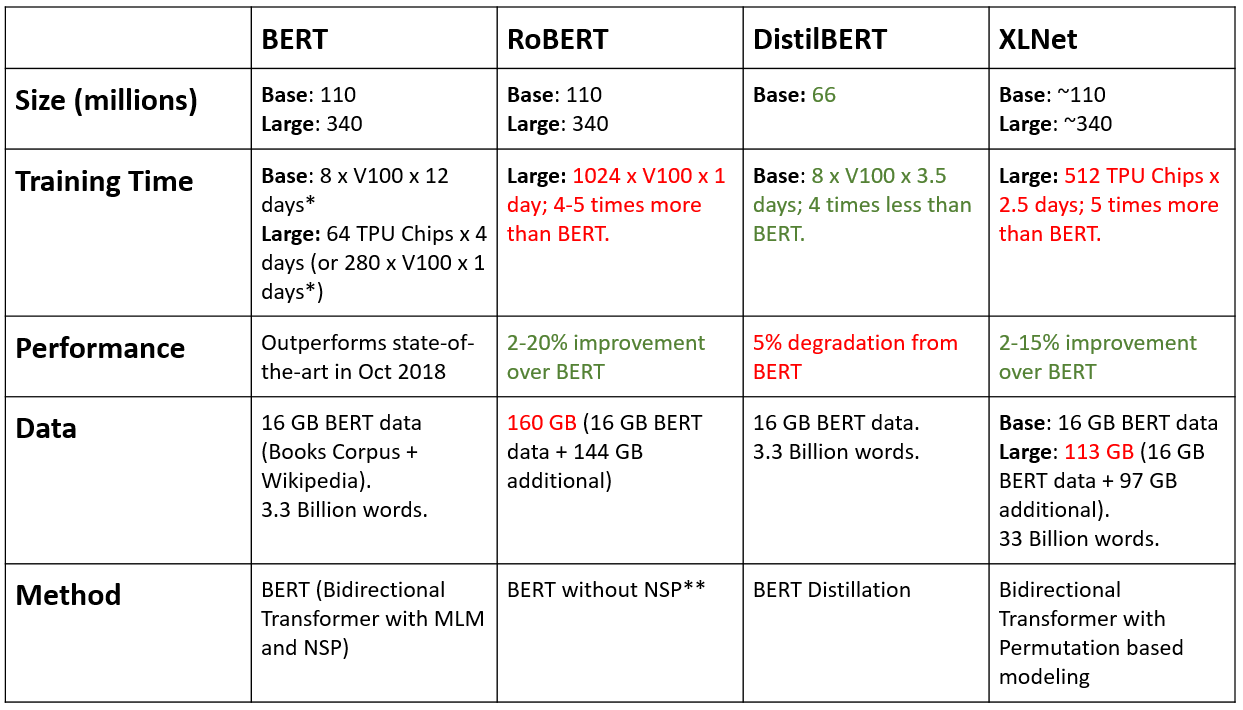
* estimated GPU time (original training time was 4 days using 4 TPU Pods)
** uses larger mini-batches, learning rates and step sizes for longer training along with differences in masking procedure.
*** Numbers as given in the original publications, unless specified otherwise.
XLNet is a large bidirectional transformer that uses improved training methodology, larger data and more computational power to achieve better than BERT prediction metrics on 20 language tasks.
To improve the training, XLNet introduces permutation language modeling, where all tokens are predicted but in random order. This is in contrast to BERT’s masked language model where only the masked (15%) tokens are predicted. This is also in contrast to the traditional language models, where all tokens were predicted in sequential order instead of random order. This helps the model to learn bidirectional relationships and therefore better handles dependencies and relations between words. In addition, Transformer XL was used as the base architecture, which showed good performance even in the absence of permutation-based training.
XLNet was trained with over 130 GB of textual data and 512 TPU chips running for 2.5 days, both of which ar e much larger than BERT.
RoBERTa. Introduced at Facebook, Robustly optimized BERT approach RoBERTa, is a retraining of BERT with improved training methodology, 1000% more data and compute power.
To improve the training procedure, RoBERTa removes the Next Sentence Prediction (NSP) task from BERT’s pre-training and introduces dynamic masking so that the masked token changes during the training epochs. Larger batch-training sizes were also found to be more useful in the training procedure.
Importantly, RoBERTa uses 160 GB of text for pre-training, including 16GB of Books Corpus and English Wikipedia used in BERT. The additional data included CommonCrawl News dataset (63 million articles, 76 GB), Web text corpus (38 GB) and Stories from Common Crawl (31 GB). This coupled with whopping 1024 V100 Tesla GPU’s running for a day, led to pre-training of RoBERTa.
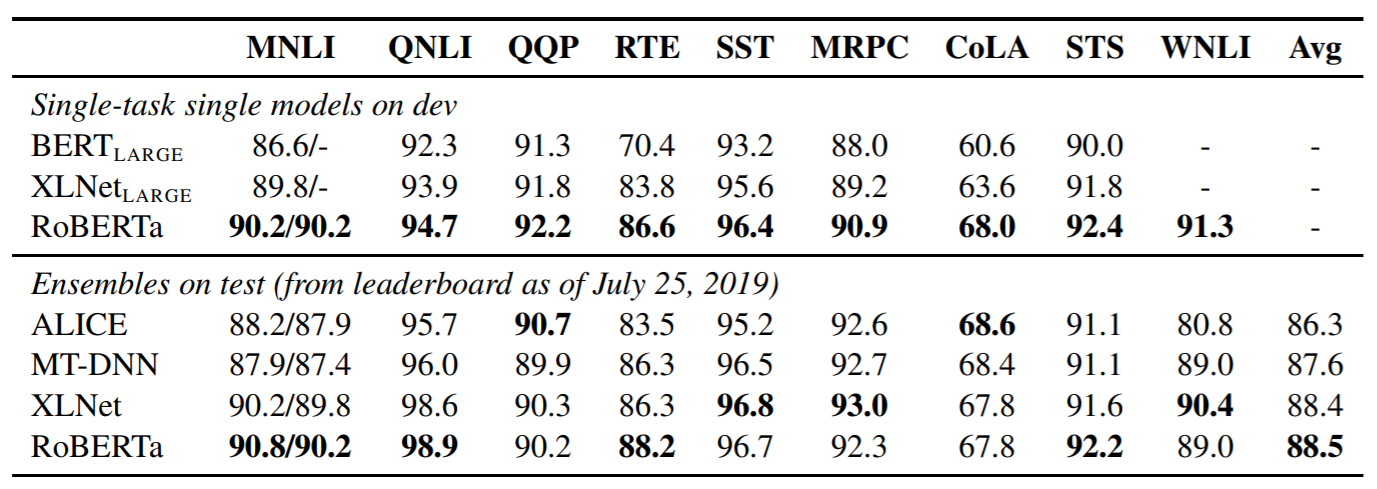
As a result, RoBERTa outperforms both BERT and XLNet on GLUE benchmark results:
On the other hand, to reduce the computational (training, prediction) times of BERT or related models, a natural choice is to use a smaller network to approximate the performance. There are many approaches that can be used to do this, including pruning, distillation and quantization, however, all of these result in lower prediction metrics.
DistilBERT learns a distilled (approximate) version of BERT, retaining 95% performance but using only half the number of parameters. Specifically, it does not has token-type embeddings, pooler and retains only half of the layers from Google’s BERT. DistilBERT uses a technique called distillation, which approximates the Google’s BERT, i.e. the large neural network by a smaller one. The idea is that once a large neural network has been trained, its full output distributions can be approximated using a smaller network. This is in some sense similar to posterior approximation. One of the key optimization functions used for posterior approximation in Bayesian Statistics is Kulback Leiber divergence and has naturally been used here as well.
Note: In Bayesian statistics, we are approximating the true posterior (from the data), whereas with distillation we are just approximating the posterior learned by the larger network.
So which one to use?
If you really need a faster inference speed but can compromise few-% on prediction metrics, DistilBERT is a starting reasonable choice, however, if you are looking for the best prediction metrics, you’ll be better off with Facebook’s RoBERTa.
Theoratically, XLNet’s permutation based training should handle dependencies well, and might work better in longer-run.
However, Google’s BERT does serve a good baseline to work with and if you don't have any of the above critical needs, you can keep your systems running with BERT.
Conclusion
Most of the performance improvements (including BERT itself!) are either due to increased data, computation power, or training procedure. While these do have a value of their own — they tend to do a tradeoff between computation and prediction metrics. Fundamental improvements that can increase performance while using fewer data and compute resources are needed.
The writer tweets at @SuleimanAliKhan. — We are Hiring —
Bio: Suleiman Khan, Ph.D. is a Lead Artificial Intelligence Specialist.
Original. Reposted with permission.
Related:
- Adapters: A Compact and Extensible Transfer Learning Method for NLP
- BERT is changing the NLP landscape
- Pre-training, Transformers, and Bi-directionality