How To Build Your Own Feedback Analysis Solution
Automating the analysis of customer feedback will sound like a great idea after reading a couple hundred reviews. Building an NLP solution to provide in-depth analysis of what your customers are thinking is a serious undertaking, and this guide helps you scope out the entire project.
By Alyona Medelyan, CEO of Thematic.

At Thematic, we’ve spent years researching, designing and developing our customer feedback analysis platform.
While I’d love for everyone to be using ours, I understand that you might have the resources, time and the data required to build one in-house.
There are benefits to building vs. buying. You can customize it to your needs. You can use it as much as you want!
But: You’ll still need to spend time maintaining and training others to use it. There are also many gotchas that you might not have considered!
So, in this post, I’ll help you get started by answering these questions:
- Which core text analysis engine should I use and what should it be able to accomplish?
- Where can you source ready-to-go components?
- How to think about data storage, ingestion and GDPR?
- How to test accuracy?
- How to think about reporting?
- Which types of questions should your solution be able to answer?
- What should the roadmap look like for developing an automated DIY customer feedback solution?
But first, let’s refresh with how you might have gotten here in the first place.
Why you might want to have a feedback analysis solution
If you have ever read through feedback and tried to put together a summary of what people want, you’ll know that it’s a difficult task.
Read 50 to 100 pieces of feedback, and it already feels like Big Data!

You can write a very generic summary fairly quickly. But creating a detailed, actionable report that will be trusted by others is a job of many hours.
The agony of manual analysis
You’ll lose time and patience reading the same thing rephrased over and over.
The thoughts at the back of your head will be anxiety-inducing: Have I cut corners? Have I introduced bias? Will we make the wrong decisions because of my rushed analysis?
And then when you present the results to your boss, and she asks to clarify something, you realize that you need to re-do the analysis from scratch. Ugh!
The magical solution
Imagine a world, in which all feedback is analyzed automatically in-depth, and the report is created on the fly. Wouldn’t it be magical?
You find a data scientist who did some NLP in his undergrad, and the two of you build a solution: Automated feedback analysis.
The company can re-use it over and over, scale up, save costs and remove bias from the analysis producing consistent results all the time.

So how do you actually do it?
Data architecture and engineering
Before you start with the core analysis, it’s important to have the right data engineering and architecture set up.
This is essential for building repeatable and scalable customer feedback analysis.
Data storage
The data storage and architecture need to be designed to support:
- easy ingestion of feedback
- adding additional rows as more feedback is collected
- and changes in format, such as additional customer data or new date format.
Often the feedback collection platform itself can be used for this.
The NLP models that are generated and the code that applies them will also need to be stored somewhere.
Ingesting data
For each new source of feedback (internal and external), you will need to develop an easy way of syphoning data into your feedback analysis solution.
Depending on the feedback collection mechanism, the availability of APIs, and the number of sources, this can be months of development work.
To get started faster, you can use your feedback collection solution (e.g. SurveyMonkey, Delighted, AskNicely, Qualtrics, MaritzCX or Medallia) to export your data into CSV.
In our experience if the data ingestion relies on manual processes, then there is a strong likelihood it won’t be updated, will go stale and the value of all the other work will be lost.
So an API integration is much better in the long run.
Data gathering, cleaning and analysis
Make sure you have examples of typical datasets you need to analyze and that they are stored in the right format.
Make sure that this data has not just the feedback but also metadata about the customers for visualizations. The best format for this is CSV in UTF-8 format.
Try not to open and then save the file in Excel because it may corrupt the data, for example by converting date fields into a different format or converting identifiers into engineering notation which then won’t match the rest of the data.

Many of the approaches to categorizing the data rely on a large corpus, so you may have to wait quite a while before you have enough internal data to work with.
Then you’ll need to manually review the data to pick up any idiosyncrasies of your specific dataset: the type of feedback, the length of each feedback piece, any templated content such as greeting conversations with the live chat agent.
For example, if your dataset consists of complaints, there is no point focusing on sentiment analysis, since most of the things people will say will be negative.
After you have collected the data, it is often necessary to clean it too.
If working with support tickets or emails; the headers, dividers and repeated text need to be removed. If working with chat logs, then agent/customer interactions need to be split and any unnecessary preamble/introductions removed.
Data Privacy (GDPR/CCPA)
Just because the project is being run in-house doesn’t mean you should ignore the relevant privacy laws based on where you operate.
It is important that if your company is compliant with the GDPR, CCPA or equivalent data laws that the necessary protocols are maintained for subject data access requests etc.
One good way of remediating this is to cleanse the data of all personally identifiable information and working with your security or trust department to ensure compliance.
Prepare test data
For each dataset, make sure you have manually chosen themes for each piece of feedback, and they are stored in an easily readable format and consistent way. Ideally, you want themes from multiple people.
Make sure that you have the right evaluation method implemented in a way that can be automated and that it can ingest test data easily.
Let’s look at how to build an NLP engine in-house and what you need to consider.
Building an NLP engine for feedback analysis
Let’s look at how to build an NLP engine in-house and what you need to consider.
Skip approaches that don’t work
First, let me save you lots of time by clarifying why the two most popular approaches to customer feedback analysis won’t give you the results you need.
Why text categorization won’t work on customer feedback
There are open-source text categorization libraries like Facebook’s FastText or proprietary solutions like Monkeylearn. You supply examples of tagged data, and a classifier algorithm learns from these examples how to categorize new text.
Here are three main reasons why they won’t work:
- You won’t discover the unknown unknowns: It’s impossible to know in advance what all the themes are without having read or analyzed feedback before (and that defeats the purpose!).
- It’s going to be very difficult to categorize a piece of feedback with multiple themes and sentiment. And customer feedback is full of such examples.
- If you want to change the set of categories you use, you will need to re-tag all of your data!
If you are only interested in general categories, rather than a deep thematic analysis, you might be happy with text categorization. BUT:
The true value comes from discovering specific, actionable themes, and ideally grouping them by meaning.
Why topic modelling or LDA won’t work on customer feedback
Topic modeling (or LDA) is the second most popular DIY technique for customer feedback analysis.
They are very easy to put together, but the results are very difficult to interpret and refine.
Trust me! We’ve tested this ourselves and spoke to plenty of companies who have tried topic modelling for customer feedback and had to give up…
I have written an article on why topic modelling won’t work if you are interested in learning more.
Step 1. Keyword Discovery
Don’t use NLP APIs for customer feedback
There are plenty of NLP APIs out there for keyword and entity extraction, but when it comes to customer feedback, can they actually deliver meaningful analysis out of the box?
The answer is no.
We have tested the major players, IBM Watson, Google Cloud, Amazon Comprehend, on online airline reviews and the results are disappointing:

IBM Watson

Google Cloud

Amazon Comprehend
The keywords are generic.
Only a small proportion is actually tagged: 32% in the best case. And even very simple variations like capitalization and plural/singular aren’t treated as the same thing.
Why are the results so underwhelming?
Most NLP APIs have been developed on very different types of text: newspaper articles, webpages, research papers, etc.
So while they might excel at those types of text, they’ll fail on customer feedback.
Use open-source keyword extraction or write your own
The best approach is to create your own themes discovery by adopting an existing keyword extraction library such as Kea or Rake to your needs.
I have written a tutorial on this topic to help others get started.
This is what the output of Rake looks like on the same dataset as used to evaluate NLP APIs earlier in the article:
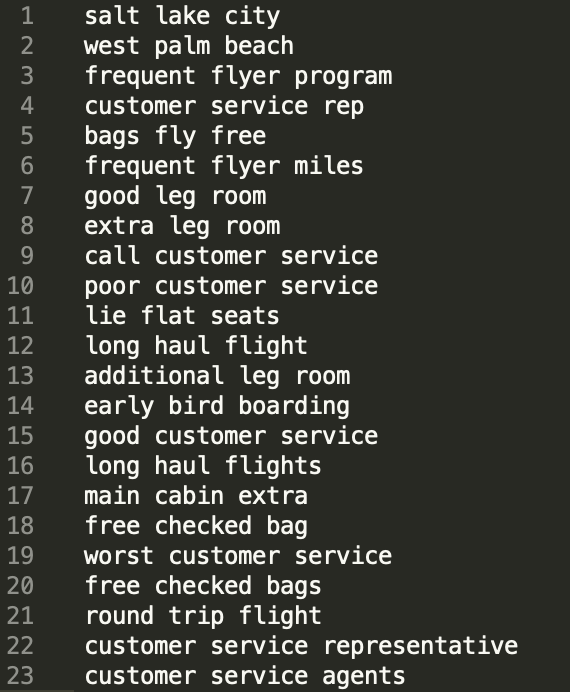
There are already more insightful keywords here, compared to the output from the NLP APIs.
In the next step, we’ll discuss how to turn these keywords into themes.
Finally, please note: Whichever library you use to make the initial themes discovery, keep in mind that it will change over time, and you’ll need to keep updating its code.
Step 2. From keywords to themes
Run any out-of-the-box NLP library on customer feedback, and you’ll end up with a long list of keywords.
Even in the example above, which has the most meaningful keywords, they are repetitive: customer service rep, customer service representative, customer service agents.
There are two main problems with this:
- Words, and even keywords and key phrases, aren’t concepts.
The above phrases customer service rep, customer service representative, customer service agent all refer to one concept and should be seen as a single item instead of three. - Not all concepts are themes.
Customer service agentis quite a generic concept. To make sure it’s actionable, we need more context. Was the customer service agent knowledgeable, rude, or helpful?
Ideally, you’ll want to merge all keywords that mean the same thing into a theme and discard all those that are too generic.
To give you an example, Thematic automatically grouped more than 700 variations of “great flight attendant” into one theme, and that didn’t include themes that are more specific (great crew) or more generic (great staff).
The best way of achieving this is to use many techniques at once: stemming, stop word removal, word embeddings.
For example, an open-source word embedding library Gensim’s word2vec out-of-the-box returns these examples for “great”:

Most other examples I tried produce significantly worse results, but you can train it on your own data to get better accuracy.
What about negation?
Correct, negation is also required to ensure accuracy.
For any feedback such as “not the best service” or “didn’t think she was friendly”, all possible negation expressions shouldn’t be stopwords, and instead part of the theme itself.
At Thematic, we spent 6 months developing a negation algorithm that captures these correctly.
Step 3. Group themes by meaning
Depending on the size of the dataset, you might still end up with hundreds of themes. You’ll need to group these by meaning.
For example, everything that relates to pricing like extra charges, baggage fees, etc. would go together.
You could make a decision on whether payment should be separate or not, based on what else is in the dataset. Here is an example of how we do it in Thematic:
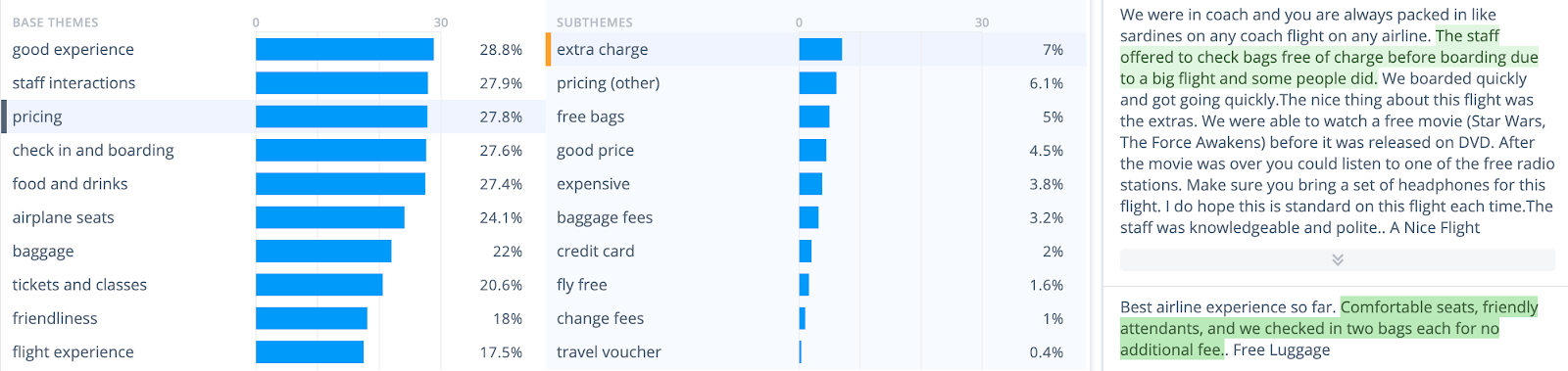
This process will help you make sure that your volume estimations are correct and that you can efficiently navigate this data.
For example, you might want to group themes depending on the department of the company responsible for them, so that you can share with them the themes in the feedback they care about.
To group keywords into themes, you’ll need at least one, or all three, of the following:
- Semantic similarity: Use an NLP approach that returns semantic similarity. These are available as open-source libraries, and you can pre-train it on all of your customer feedback (just raw text, no analysis necessary) to make the results more relevant.
- Clustering: You could also cluster themes by using their attributes such as co-occurrence. Before you do, make sure to convert each keyword into a vector to capture its meaning better.
- Themes editor: For moving some of the themes by hand, since how would the algorithm be able figure out from data your tacit knowledge.
All three components will require implementation since none of the NLP APIs provides this out-of-the-box because they are too specific.
Maintaining consistency over time
Once you have the perfect analysis of your customer feedback, think about how it might change as more feedback is added.
Ideally, you’d want to keep the same themes as you’ve discovered earlier, but you’d want to keep adding new emerging themes into the right places.
How are you able to accomplish this?
First, you would need to keep track of previous themes.
Second, you’ll need to use the same tactics as described above to “fold in” new themes into previous themes.
Ideally, you’d want to see which themes are new in the themes editor, to make sure you review only the new themes, making sure the results are still accurate and relevant.
Assessing accuracy
Once you are done with the analysis, make sure that the results are accurate.
It’s not easy to evaluate accuracy in a way that’s both objectives, meaningful and repeatable.
In earlier posts, we described how to think about evaluating the accuracy and make sure that other elements (coverage and usefulness) are also considered.
Building the reporting functionality for feedback analysis
Let’s assume that your customer feedback has been tagged with all the themes it covers…
Next step is to visualize this in a way that tells others the story. It’s not as easy as it might seem, because all the DIY visualization tools (Excel, Tableau, Looker) aren’t built for visualizing complex data.
And tagged feedback is complex, multivariate data because each piece of feedback corresponds to multiple themes that all inter-relate.
Unfortunately, none of the standard bar charts or pie charts can easily capture these relationships.
Questions that your visualization should be able to answer
You’ll need visualizations that help you answer the following questions while being able to zoom into the details to dig deeper:
- What do people talk about?
- What do people say about X?
- What should I work on next (or, what makes the greatest impact on my metric Y)?
- What changed since Z, optionally, in relation to X?
- Why did my metric drop/increase?
- What are the emerging themes that are too small to see, but that I should be paying attention to?
For each question, you’ll need to come up with a chart that both answers this question and lets users navigate from high-level categories into more specific themes.
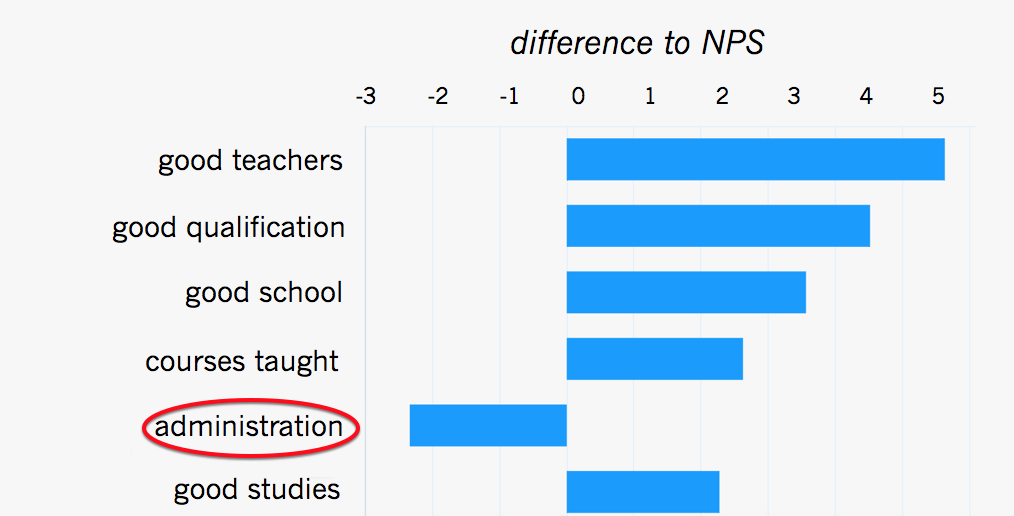
In earlier posts, we’ve discussed in more detail why word clouds aren’t the best solution to answer these questions (well, maybe some).
At Thematic, we use bar charts, line charts, waterfall charts, and special visualizations for showing the impact of themes on key metrics.
This is explained in our post: alternatives to word clouds.
Roadmap for building your own customer feedback analysis solution
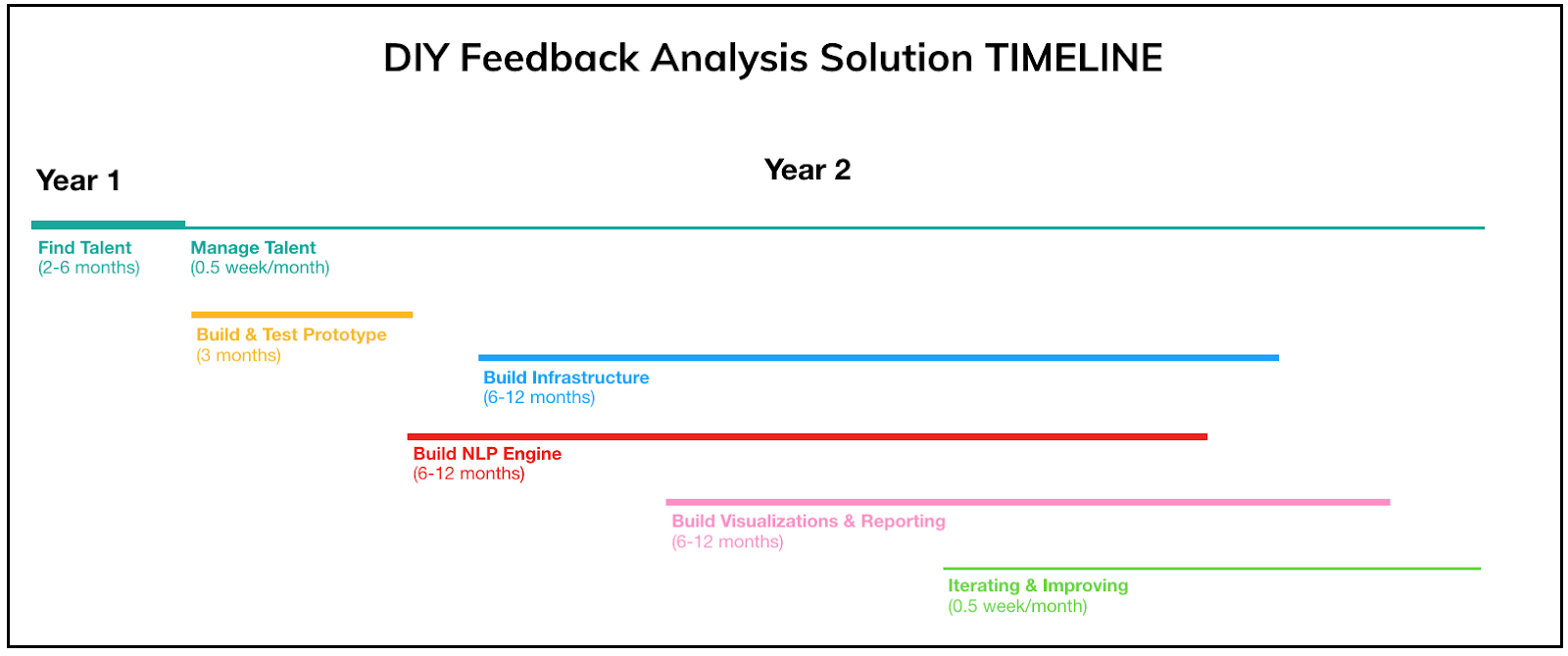
Here is how you could plan your roadmap for developing a solution for customer feedback analysis:
Find the right talent and plan for staff turn over
Your effort: 2-6 months depending on the resources available, plus 1 week every 2 months ongoing.
As you can see from the earlier chapters, you will need to think about many different aspects of customer feedback analysis. On your team, you will need the following people:
- Project lead to oversee the entire process end-to-end and ensure the documentation. Ideally, this person should come from a customer insights background to monitor the usefulness of what’s being created
- Dev ops person and resources to ensure the server infrastructure is available
- Data engineer to ensure you have the right data in the right format
- NLP and Machine learning experts to develop the core of the solution
- Visualizations specialist who may be an expert in a particular solution or a front-end developer who is an expert in one of the visualization frameworks, e.g. Vue or React
- UX expert to make sure that what’s created is usable, and ideally a graphic designer too
- Project manager to make sure the delivery happens in a timely manner
A common mistake we see is when companies only have an NLP and Machine learning expert, but not the rest of the team.
This results in lengthy projects that often are abandoned in the end, even if the initial one-off experiments are promising.
Fail fast?
Your effort: 3-6 months to build and test a rough prototype.
We encourage you to start with just one data source and set a clear time for when you would want this internally built solution to have results at what accuracy.
Having the right accuracy evaluation strategy is critical here.
Note that it might be easy to get from 0% to 70%, but it will get harder and harder to incrementally keep increasing accuracy to a useful state.
If after 3 months, you don’t have useful and actionable themes, it indicates that the project might not have the right knowledge resources.
Infrastructure and data preparation
Your effort: 6-12 months to find the right resources and build the infrastructure.
Have a plan on how to move from a prototype into a repeatable and scalable production environment that delivers insights to those who need them. This is individual to every organization.
Talk to others in your industry who have accomplished this task successfully internally to learn how you might be able to copy their success.
Additional difficulties come into play here, if you use any external resources (e.g. servers), which will require InfoSec approval.
NLP engine
Your effort:6-12 months for extending your prototype and building a themes editor
Read our chapter on NLP engine, and discount a lot of the solutions that haven’t proven to be productive by others.
Building an NLP engine can be a huge time sink if you make the wrong decisions here.
Remember that even the perfect solution will need to be edited by a person, so you’ll need to ensure it’s possible.
For any external components such as APIs, you will also require InfoSec approval.
Visualizations and reporting
Your effort:4-12 months for building not just dashboards but also analytical tools to dig deeper.
Having the right visuals and reports can be deceptively complex!
The best thing about doing this in-house is that you can combine your financial metrics with your customer feedback metrics in one dashboard. But financial data is significantly easier to visualize, and you’ll have to make a compromise on what to display.
This usually results in reporting on generic themes, which isn’t useful.
Iterating and improving your solution
Your effort: 3 days per month at least continuously for gathering feedback, and 1 to 2 months every 6 months to incorporate the best suggestions
The most important thing is to make sure that your solution is used by others and is useful to them.
Ideally, you want to build analytics that tell you implicit feedback about what’s used and what isn’t used.
You’ll need to also run user sessions to collect explicit feedback and ensure enough resources are allocated to implementing improvements.
Other considerations
Other things we haven’t discussed here are keeping up with the ever-changing APIs, libraries, infrastructure and state-of-the-art NLP and Deep Learning.
You will need to allocate maintenance time to make sure your solution stays current.
Finally, what you’ll build is a product. In order for the product to be successful, others need to be onboarded properly to use it.
This is actually one of the hardest things because not using feedback at all and instead relying on gut instinct is the easiest way of making decisions, and most will revert back to this mode of operating if your solution isn’t easy to use.
Even if you have achieved adoption and happy users, as people leave their roles, you’ll need to train up new staff to use your solution to start over.
At Thematic, we have an active Customer Success team that makes this possible.
Summary: Build your own or Buy?
There you have it! A complete guide to building your own customer feedback analysis solution.
When my colleagues saw this draft, they said it’s going to come across like I’m trying to make the process sound overly complex, and am covertly trying to promote Thematic.
And maybe they’re partially right.
Full disclosure: I’ve spent 15 years studying natural language understanding, absolutely love seeing people use the technology I’ve developed, and would be delighted to learn that someone read this and decided to use Thematic instead.
The issue of complexity and difficulty is another story. For some reason, people seem to think that building a customer feedback analysis solution in-house is simple.
From making sure themes are meaningful to accounting for data privacy and GDPR, there are serious pitfalls to consider, and hopefully, this article will save you the time of having to learn from them first hand.
Trust me, manual feedback analysis is painful, but it doesn’t compare to the frustration of building a solution that doesn’t work.
Original. Reposted with permission.
Bio: Alyona Medelyan is the Co-Founder and CEO at Thematic, a SaaS platform for customer insights. We find actionable insights in customer feedback received through NPS and CSAT surveys and tell companies how to drive change to loyalty, customer satisfaction and churn. Thematic uses proprietary word-class Text Analytics developed based on 15+ years of my research in NLP and Machine Learning.
Related: