Why and How to Use Dask with Big Data
The Pandas library for Python is a game-changer for data preparation. But, when the data gets big, really big, then your computer needs more help to efficiency handle all that data. Learn more about how to use Dask and follow a demo to scale up your Pandas to work with Big Data.
By Admond Lee, Data Scientist, MicronTech.

Being a data scientist, Pandas is one of the best tools for data cleaning and analysis used in Python.
It’s seriously a game-changer when it comes to cleaning, transforming, manipulating, and analyzing data.
No doubt about it.
In fact, I’ve even created my own toolbox for data cleaning using Pandas. The toolbox is nothing but a compilation of common tricks to deal with messy data with Pandas.
My Love-Hate Relationship with Pandas
Don’t get me wrong.
Pandas is great. It’s powerful.
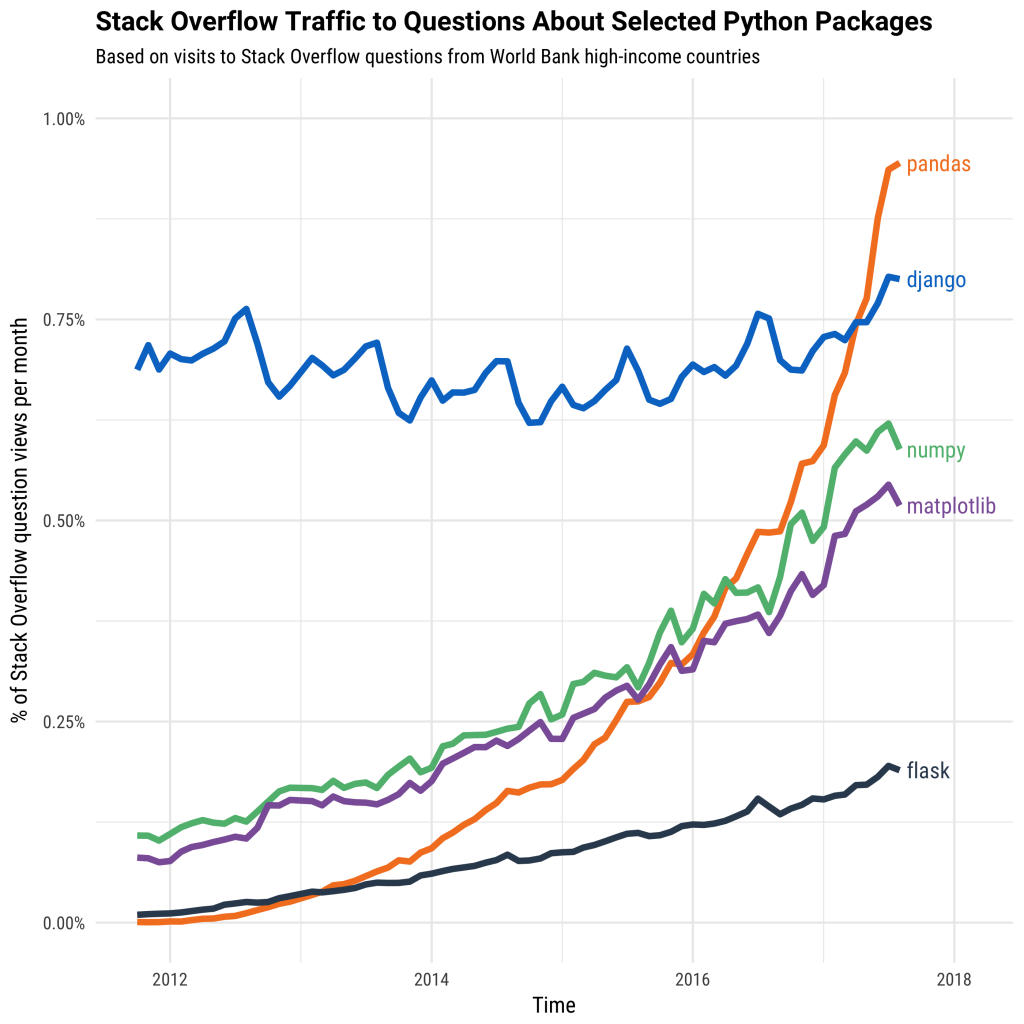
Stack Overflow Traffic to Questions about Selected Python Packages
It’s still one of the most popular data science tools for data cleaning and analytics.
However, after being in the data science field for some time, the data volume that I’m dealing with increases from 10MB, 10GB, 100GB, to 500GB, or sometimes even more than that.
My PC either suffered low performance or long runtime due to the inefficient local memory usage for data that was larger than 100GB.
That was the time when I realized Pandas wasn’t initially designed for data at large scales.
That was the time when I realized the stark difference between large data and big data.
A famous joke by Prof. Dan Ariely:
The word large and big are in themselves “relative,” and in my humble opinion, large data is data sets that are less than 100GB.
Now, Pandas is very efficient with small data (usually from 100MB up to 1GB), and performance is rarely a concern.
But when you have more data that’s way larger than your local RAM (say 100GB), you can either still use Pandas to handle data with some tricks to a certain extent or choose a better tool — in this case, Dask.
This time, I chose the latter.
Why Dask works like MAGIC
To some of us, Dask might be something that you’re already familiar with.
But to most aspiring data scientists or people who just got started in data science, Dask might sound a little bit foreign.
And this is perfectly fine.
In fact, I didn’t get to know Dask until I faced the real limitation of Pandas.
Keep in mind that Dask is not a necessity if your data volume is sufficiently low and can fit into your PC’s memory space.
So the question now is…
What’s Dask, and why Dask is better than Pandas to handle big data?
Dask is popularly known as a Python parallel computing library
Through its parallel computing features, Dask allows for rapid and efficient scaling of computation.
It provides an easy way to handle large and big data in Python with minimal extra effort beyond the regular Pandas workflow.
In other words, Dask allows us to easily scale out to clusters to handle big data or scale down to single computers to handle large data through harnessing the full power of CPU/GPU, all beautifully integrated with Python code.
Cool, isn’t it?
Think of Dask as an extension of Pandas in terms of performance and scalability.
What’s even cooler is that you can switch between a Dask dataframe and Pandas dataframe to do any data transformation and operation on demand.
How to use Dask with Big Data?
Okay, enough of theory.
It’s time to get our hands dirty.
You can install Dask and try that in your local PC to use your CPU/GPU.
But we’re talking about big data here, so let’s do something different.
Let’s go BIG.
Instead of taming the “beast” by scaling down to single computers, let’s discover the full power of the “beast” by scaling out to clusters, for FREE.
YES, I mean it.
Understanding that setting up a cluster (AWS, for example) and connecting Jupyter notebook to the cloud can be a pain to some data scientists, especially for beginners in cloud computing, let’s use Saturn Cloud.
This is a new platform that I’ve been trying out recently.
Saturn Cloud is a managed data science and machine learning platform that automates DevOps and ML infrastructure engineering.
To my surprise, it uses Jupyter and Dask to scale Python for big data using the libraries we know and love (Numpy, Pandas, Scikit-Learn, etc.). It also leverages Docker and Kubernetes so that your data science work is reproducible, shareable, and ready for production.
There are three main types of Dask user interfaces, namely Array, Bag, and Dataframe. We’ll focus mainly on Dask Dataframe in the code snippets below, as this is what we mostly would be using for data cleaning and analytics as a data scientist.
1. Read CSV files to Dask dataframe
import dask.dataframe as dd
df = dd.read_csv('https://e-commerce-data.s3.amazonaws.com/E-commerce+Data+(1).csv', encoding = 'ISO-8859-1', blocksize=32e6)
Dask dataframe is no different from Pandas dataframe in terms of normal files reading and data transformation, which makes it so attractive to data scientists, as you’ll see later.
Here we just read a single CSV file stored in S3. Since we just want to test out Dask dataframe, the file size is quite small, with 541909 rows.
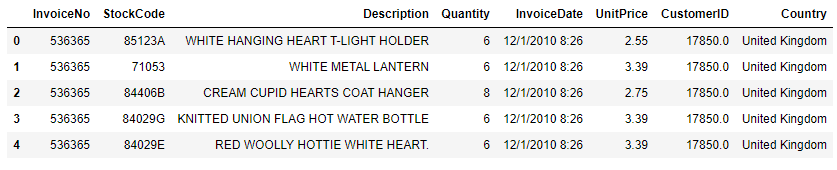
Dask dataframe after reading CSV file.
NOTE: We can also read multiple files to the Dask dataframe in one line of code, regardless of the file size.
When we load up our data from the CSV, Dask will create a DataFrame that is row-wise partitioned i.e. rows are grouped by an index value. That’s how Dask is able to load the data into memory on-demand and process it super fast — it goes by partition.
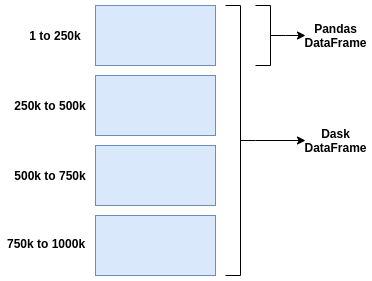
In our case, we see that the Dask dataframe has 2 partitions (this is because of the blocksize specified when reading CSV) with 8 tasks.
“Partitions” here simply mean the number of Pandas dataframes split within the Dask dataframe.
The more partitions we have, the more tasks we will need for each computation.
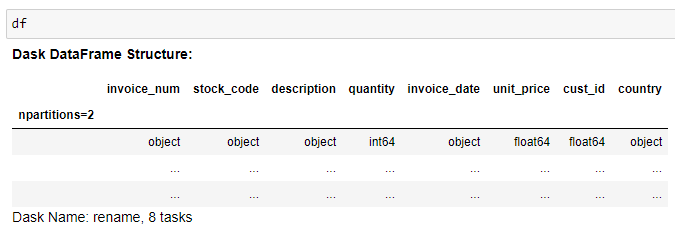
Dask dataframe structure.
2. Use compute() to execute the operation
Now that we’ve read the CSV file to Dask dataframe.
It is important to remember that, while Dask dataframe is very similar to Pandas dataframe, some differences do exist.
The main difference that I notice is this compute method in Dask dataframe.
df.UnitPrice.mean().compute()
Most Dask user interfaces are lazy, meaning that they don’t evaluate until you explicitly ask for a result using the compute method.
This is how we calculate the mean of the UnitPrice by adding compute method right after the mean method.
3. Check number of missing values for each column
df.isnull().sum().compute()
Similarly, if we want to check the number of missing values for each column, we need to add compute method.
4. Filter rows based on conditions
df[df.quantity < 10].compute()
During the data cleaning or Exploratory Data Analysis (EDA) process, we often need to filter rows based on certain conditions to understand the “story” behind the data.
We can do the exact operation as what we do in Pandas by just adding compute method.
And BOOM! We get the results!
DEMO to create a Dask cluster & run Jupyter at scale with Python
Now that we’ve understood how to use Dask in general, it’s time to see how to create a Dask cluster on Saturn Cloud and run Python code in Jupyter at scale.
I recorded a short video to show you exactly how to do the setup and run Python code in a Dask cluster in minutes.
How to create a Dask cluster and run Jupyter Notebook on Saturn Cloud
Final Thoughts
Thank you for reading.
In terms of functionalities, Pandas still wins.
In terms of performance and scalability, Dask is ahead of Pandas.
In my opinion, if you have data that’s larger than a few GB (comparable to your RAM), go with Dask for the purpose of performance and scalability.
If you want to create a Dask cluster in minutes and run your Python code at scale, I highly recommend you to get the community edition of Saturn Cloud here for FREE.
Original. Reposted with permission.
Bio: Admond Lee is now in the mission of making data science accessible to everyone. He is helping companies and digital marketing agencies achieve marketing ROI with actionable insights through innovative data-driven approaches. With his expertise in advanced social analytics and machine learning, Admond aims to bridge the gaps between digital marketing and data science.
Related: