
 How to Speed up Pandas by 4x with one line of code
How to Speed up Pandas by 4x with one line of code

 How to Speed up Pandas by 4x with one line of code
How to Speed up Pandas by 4x with one line of codeWhile Pandas is the library for data processing in Python, it isn't really built for speed. Learn more about the new library, Modin, developed to distribute Pandas' computation to speedup your data prep.
Pandas is the go-to library for processing data in Python. It’s easy to use and quite flexible when it comes to handling different types and sizes of data. It has tons of different functions that make manipulating data a breeze.

The popularity of various Python packages over time. Source
But there is one drawback: Pandas is slow for larger datasets.
By default, Pandas executes its functions as a single process using a single CPU core. That works just fine for smaller datasets since you might not notice much of a difference in speed. But with larger datasets and so many more calculations to make, speed starts to take a major hit when using only a single core. It’s doing just one calculation at a time for a dataset that can have millions or even billions of rows.
Yet most modern machines made for Data Science have at least 2 CPU cores. That means, for the example of 2 CPU cores, that 50% or more of your computer’s processing power won’t be doing anything by default when using Pandas. The situation gets even worse when you get to 4 cores (modern Intel i5) or 6 cores (modern Intel i7). Pandas simply wasn’t designed to use that computing power effectively.
Modin is a new library designed to accelerate Pandas by automatically distributing the computation across all of the system’s available CPU cores. With that, Modin claims to be able to get nearly linear speedup to the number of CPU cores on your system for Pandas DataFrames of any size.
Let’s see how it all works and go through a few code examples.
How Modin Does Parallel Processing With Pandas
Given a DataFrame in Pandas, our goal is to perform some kind of calculation or process on it in the fastest way possible. That could be taking the mean of each column with .mean(), grouping data with groupby, dropping all duplicates with drop_duplicates(), or any of the other built-in Pandas functions.
In the previous section, we mentioned how Pandas only uses one CPU core for processing. Naturally, this is a big bottleneck, especially for larger DataFrames, where the lack of resources really shows through.
In theory, parallelizing a calculation is as easy as applying that calculation on different data points across every available CPU core. For a Pandas DataFrame, a basic idea would be to divide up the DataFrame into a few pieces, as many pieces as you have CPU cores, and let each CPU core run the calculation on its piece. In the end, we can aggregate the results, which is a computationally cheap operation.
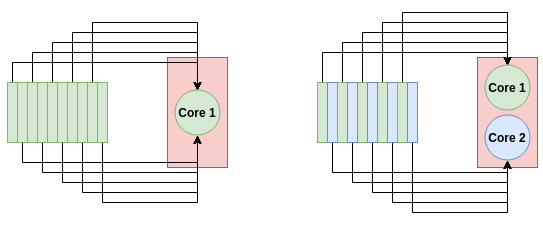
How a multi-core system can process data faster. For a single-core process (left), all 10 tasks go to a single node. For the dual-core process (right), each node takes on 5 tasks, thereby doubling the processing speed.
That’s exactly what Modin does. It slices your DataFrame into different parts such that each part can be sent to a different CPU core. Modin partitions the DataFrames across both the rows and the columns. This makes Modin’s parallel processing scalable to DataFrames of any shape.
Imagine if you are given a DataFrame with many columns but fewer rows. Some libraries only perform the partitioning across rows, which would be inefficient in this case since we have more columns than rows. But with Modin, since the partitioning is done across both dimensions, the parallel processing remains efficient all shapes of DataFrames, whether they are wider (lots of columns), longer (lots of rows), or both.

A Pandas DataFrame (left) is stored as one block and is only sent to one CPU core. A Modin DataFrame (right) is partitioned across rows and columns, and each partition can be sent to a different CPU core up to the max cores in the system.
The figure above is a simple example. Modin actually uses a Partition Manager that can change the size and shape of the partitions based on the type of operation. For example, there might be an operation that requires entire rows or entire columns. In that case, the Partition Manager will perform the partitions and distribution to CPU cores in the most optimal way it can find. It’s flexible.
To do a lot of the heavy lifting when it comes to executing the parallel processing, Modin can use either Dask or Ray. Both of them are parallel computing libraries with Python APIs, and you can select one or the other to use with Modin at runtime. Ray will be the safest one to use for now as it is more stable — the Dask backend is experimental.
But hey, that’s enough theory. Let’s get to the code and speed benchmarks!
Benchmarking Modin Speed
The easiest way to install and get Modin working is via pip. The following command installs Modin, Ray, and all of the relevant dependencies:
pip install modin[ray]
For our following examples and benchmarks, we’re going to be using the CS:GO Competitive Matchmaking Data from Kaggle. Each row of the CSV contains data about a round in a competitive match of CS:GO.
We’ll stick to experimenting with just the biggest CSV file for now (there are several) called esea_master_dmg_demos.part1.csv, which is 1.2GB. With such a size, we should be able to see how Pandas slows down and how Modin can help us out. For the tests, I’ll be using an i7–8700k CPU, which has 6 physical cores and 12 threads.
The first test we’ll do is simply reading in the data with our good’ol read_csv(). The code itself is the exact same for both Pandas and Modin.
To measure the speed, I imported the time module and put a time.time() before and after the read_csv(). As a result, Pandas took 8.38 seconds to load the data from CSV to memory while Modin took 3.22 seconds. That’s a speedup of 2.6X. Not too shabby for just changing the import statement!
Let’s do a couple of heavier processes on our DataFrame. Concatenating multiple DataFrames is a common operation in Pandas — we might have several or more CSV files containing our data, which we then have to read one at a time and concatenate. We can easily do this with the pd.concat() function in Pandas and Modin.
We’d expect that Modin should do well with this kind of an operation since it’s handling a lot of data. The code is shown below.
In the above code, we concatenated our DataFrame to itself 5 times. Pandas was able to complete the concatenation operation in 3.56 seconds while Modin finished in 0.041 seconds, an 86.83X speedup! It appears that even though we only have 6 CPU cores, the partitioning of the DataFrame helps a lot with the speed.
A Pandas function commonly used for DataFrame cleaning is the .fillna() function. This function finds all NaN values within a DataFrame and replaces them with the value of your choice. There’s a lot of operations going on there. Pandas has to go through every single row and column to find NaN values and replace them. This is a perfect opportunity to apply Modin since we’re repeating a very simple operation many times.
This time, Pandas ran the .fillna() in 1.8 seconds while Modin took 0.21 seconds, an 8.57X speedup!
A caveat and final benchmarks
So is Modin always this fast?
Well, not always.
There are some cases where Pandas is actually faster than Modin, even on this big dataset with 5,992,097 (almost 6 million) rows. The table below shows the run times of Pandas vs. Modin for some experiments I ran.
As you can see, there were some operations in which Modin was significantly faster, usually reading in data and finding values. Other operations, such as performing statistical calculations, were much faster in Pandas.
Practical Tips for using Modin
Modin is still a fairly young library and is constantly being developed and expanded. As such, not all of the Pandas functions have been fully accelerated yet. If you try and use a function with Modin that is not yet accelerated, it will default to Pandas, so there won’t be any code bugs or errors. For the full list of Pandas methods that are supported by Modin, see this page.
By default, Modin will use all of the CPU cores available on your machine. There may be some cases where you wish to limit the number of CPU cores that Modin can use, especially if you want to use that computing power elsewhere. We can limit the number of CPU cores Modin has access to through an initialization setting in Ray since Modin uses it on the backend.
import ray ray.init(num_cpus=4) import modin.pandas as pd
When working with big data, it’s not uncommon for the size of the dataset to exceed the amount of memory (RAM) on your system. Modin has a specific flag that we can set to true, which will enable its out of core mode. Out of core basically means that Modin will use your disk as overflow storage for your memory, allowing you to work with datasets far bigger than your RAM size. We can set the following environment variable to enable this functionality:
export MODIN_OUT_OF_CORE=true
Conclusion
So there you have it! Your guide to accelerating Pandas functions using Modin. Very easy to do by changing just the import statement. Hopefully, you find Modin useful in at least a few situations to accelerate your Pandas functions.
Related: