 The Data Science Puzzle — 2020 Edition
The Data Science Puzzle — 2020 Edition
 The Data Science Puzzle — 2020 Edition
The Data Science Puzzle — 2020 EditionThe data science puzzle is once again re-examined through the relationship between several key concepts of the landscape, incorporating updates and observations since last time. Check out the results here.

With a new year upon us, let's take a fresh look at the current state of the data science puzzle. What are the most important constituent concepts of the data science landscape? How do they fit together? Which of these have been elevated in importance since the previous installment, and which are less important?
As a few years have passed since I last treated this particular topic, it might be worth having a look at this out of interest, and for comparison. We will proceed by first looking at the concept definitions from last time, and then look at how things have changed since then.
We start with the perceived original driver of the data science revolution, big data. What I said in 2017:
Big Data is still important to data science. Take your pick of metaphors, but any way you look at it, Big Data is the raw material that [...] continues to fuel the data science revolution.
As relates to Big Data, I believe that justification of data-acquisition and -retention from a business point of view, expectations that Big Data projects start providing actual financial returns, and the challenges related to data privacy and security will become the big Big Data stories not only of 2017 but moving forward in general. In short, it's time for big returns from, and big protections for, Big Data.
However, as others have opined, Big Data now "just is," and is perhaps no longer an entity deserving of the special attention it has received for the better part of a decade.
While I don't condone the capitlization of most key terms in general, "big data" seemed to previously demand this treatment given its near-fabled status and brand name-like station. Notice this time around I have reneged this status, which goes hand in hand with the idea that big data is no longer top level data science terminology. As alluded to in the final sentence, moving forward big data is simply "data," and we could reword part of that excerpt to read, "data is the raw material that continues to fuel the data science revolution."
Look, at this point we should all be aware of how important data is to the process of data science (it's right there in the name). Whether our data is big or small or lies somewhere else on the data sizing spectrum really doesn't require distinguishing from the outset. We all want to science the data and provide value, whether the data is a lot or a little. "Big data" may provide us with more or unique opportunities for the types of analytics and modeling to employ, but this seems akin to distinguishing the size of our nails from the get-go just so we know what size and type of hammer to bring along for a given job.
Data is everywhere. Much of it is big. It's time we stop emphasizing so, just like it's time we stop saying "smart" phone. The phones are all basically smart now, and making special note of it really says more about you than it does about the phone.
One thing I stand by, however, is that the challenges related to data privacy and security will only grow in importance as the years march on, and we can add ethics into that mix as well, though seriously treating these topics is beyond the scope of this article.
Here's what I said about machine learning as a component of data science last time:
Machine learning is one of the primary technical drivers of data science. The goal of data science is to extract insight from data, and machine learning is the engine which allows this process to be automated. Machine learning algorithms continue to facilitate the automatic improvement of computer programs from experience, and these algorithms are becoming increasingly vital to a variety of diverse fields.
I stand by this, and would only make the argument that machine learning is more than one of the primary technical drivers of data extraction, it is the the primary technical driver.
There are a variety of aspects to data science; we are discussing a number of them in this very article. However, when thinking about extracting insight from data which cannot be seen with the "naked eye" via descriptive statistics or the visualization of these stats or some type of business intelligence reporting — all of which can be very useful and provide invaluable illumination in the proper circumstance — machine learning is the natural path to take, a path which has automation baked in.
Machine learning is not synonymous with data science; however, given the reliance on machine learning to extract insight from data, you can forgive the many who often make this mistake.
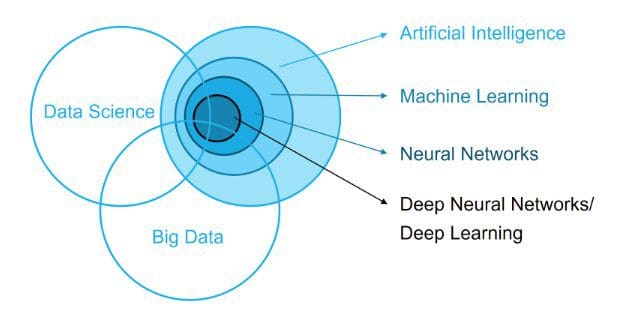
So what about deep learning?
Deep learning is also a process; it is the application of deep neural network technologies -- neural network architectures (which are particular types of machine learning algorithms) with multiple hidden layers -- to solve problems. As a process, deep learning is to neural networks as data mining is to "traditional" machine learning (this is a somewhat flawed comparison lacking nuance, but at a very high level I stand by it).
Deep learning is a specific type of machine learning, which is the employment of deep neural networks for insight extraction. Neural networks still provide state of the art results in a wide variety of fields — notably computer vision and natural language processing — which is why they are often treated distinctly from machine learning. While they are just a tool, they are a tool that often seems to prove especially useful in particular data science tasks.
Since the previous data science puzzle article, deep learning has moved from having asserted itself quite dominantly in computer vision and having its sights set on natural language processing, to now having completed its engulfing of NLP. Like in computer vision, deep learning algorithms are now not the only algorithms used for tackling problems, but they certainly have become some of the first choices for a whole host of subtasks, and for god reason.
The data science relationship with artificial intelligence seems to have morphed quite dramatically over the past three years. AI seemed to be used much more sparingly way back then. Today, every machine learning and data science startup seems to be in the business of artificial intelligence, along with a whole host of others which employ no AI whatsoever.
But what is artificial intelligence? Note that this is not artificial general intelligence, the idea of creating an intelligence which can adapt readily to new problems, much like human intelligence. Here's what I wrote about AI three yeas ago:
In my opinion, AI is a yardstick, a moving target, an unattainable goal.
But that doesn't mean that AI is not worthy of pursuit; AI research pays dividends in the form of inspiration and motivation. As you may have noticed, however, AI has a perception problem. Just as data mining used to be a mainstream term that struck fear into the hearts of many (mostly related to the invasion of privacy), AI frightens the masses from an entirely different viewpoint, one that evokes SkyNet-style fears. I don't know whether we thank the media, Elon Musk, the confounding of AI with deep learning and its successes, or something else entirely, but I don't think the end result is escapable: this perception issue is real, and the uninitiated are becoming terrified.
There is also this: though machine learning, artificial intelligence, deep learning, computer vision and natural language processing (along with a variety of other applications of these "intelligent" technologies) are all separate and distinct fields and application domains, even practitioners and researchers have to admit that there is some continually evolving "concept creep" going on any more, beyond the regular ol' confusion and confounding that has always taken place. And that's OK; these fields all started out as niche sub-disciplines of other fields (computer science, statistics, linguistics, etc.), and so their constant evolution should be expected. While it is important on some level to ensure that everyone who should have a basic understanding of their differences indeed possesses this understanding, when it comes to their application in fields such as data science, I would humbly submit that getting too far into the semantic weeds doesn't provide practitioners with much benefit in the long term.
Artificial and machine intelligence will look very different in 2030 than it does now, and not having a basic understanding of this evolving set of technologies and the research that fuels them, or being open to their application as data scientists, will have a detrimental effect on your long term success.
As I alluded to above, getting into the semantic weeds of exactly what defines artificial intelligence is not what I'm wont to do. I have a vague idea of what I would technically classify as "artificial intelligence," as do you; our vague ideas may differ. The underlying current of my perception of what I consider AI, and its main benefit, is its unattainability. AI represents a set of vaguely defined lofty goals, the closer to which we get become replaced with eve more lofty goals.
And that brings us to data science:
Data science is a multifaceted discipline, which encompasses machine learning and other analytic processes, statistics and related branches of mathematics, increasingly borrows from high performance scientific computing, all in order to ultimately extract insight from data and use this new-found information to tell stories.
I still like this definition. It's succinct, pulls things together, and doesn't really need to be elaborated on, at least in my opinion. But I did write it, so I might be biased.
Lastly, let's talk about statistics. How does stats play into the greater landscape of data science? Here's what Diego Kuonen had to say on the subject three years, after I published my last article on the subject:
.@mattmayo13, isn't #Statistics the puzzle paper?
"The #DataScience Puzzle"
> https://t.co/9E1zqJoDx6#BigData #ML #DL #AI #Analytics #IoT pic.twitter.com/zjcHkUChKO— Prof. Diego Kuonen (@DiegoKuonen) January 25, 2017
And he's right! If data science is a puzzle, as in a jigsaw puzzle, the paper the puzzle is printed on is metaphorically the foundation upon which data science stands. Statistics is that foundation.
And those are the top-level concepts of data science, or at least how I see them. These are not the only important aspects of the landscape, obviously. Numerous other aspects such as data visualization have not been included herein, and many would argue they should have been. I stand by my selections however, and leave other concepts for another time.
Lastly, I want to emphasize that this is all one person's opinion, based on how I have tweaked my mental model over the past number of years. It's not fact, but it is my take, though I'm sure there will be lots for people to disagree with.
Related:
- The Data Science Puzzle, Revisited
- The Data Science Puzzle, Explained
- The Machine Learning Puzzle, Explained