The Data Science Puzzle, Revisited
The data science puzzle is re-examined through the relationship between several key concepts in the realm, and incorporates important updates and observations from the past year. The result is a modified explanatory graphic and rationale.
Last year I wrote an overview post which defines a number of key concepts related to data science -- including data science itself -- and attempts to explain how these pieces fit together into a so-called "data science puzzle." As a new year begins, and a previous year worth of advances, insights, and accomplishments get rolled into our collective professional outlook, I thought it would be prudent to revisit this puzzle, noting and incorporating any changes and updates which may contribute to rearranging the puzzle for the foreseeable future, and to provide some addition commentary where warranted.
Big Data is still important to data science. Take your pick of metaphors, but any way you look at it, Big Data is the raw material that has continues to fuel the data science revolution.
As relates to Big Data, I believe that justification of data-acquisition and -retention from a business point of view, expectations that Big Data projects start providing actual financial returns, and the challenges related to data privacy and security will become the big Big Data stories not only of 2017 but moving forward in general. In short, it's time for big returns from, and big protections for, Big Data.
However, as others have opined, Big Data now "just is," and is perhaps no longer an entity deserving of the special attention it has received for the better part of a decade.
Machine learning is one of the primary technical drivers of data science. The goal of data science is to extract insight from data, and machine learning is the engine which allows this process to be automated. Machine learning algorithms continue to facilitate the automatic improvement of computer programs from experience, and these algorithms are becoming increasingly vital to a variety of diverse fields.
I believe (and I'm not alone) that automated machine learning will increasingly become an industrial strength force to be reckoned with, assisting data scientists with a variety of machine learning and modeling tasks, but not supplanting data scientists... not yet, at least. Interpretation of models is still required, and while the nuance and finesse of the human eye cannot be entirely outsourced to machine learning pipelines, much of the algorithm and feature selection can, as can the assessment and comparison of multiple models in a search for the best fit.
I previously cited the complicated relationship between machine learning and data mining (with which, I assume, most people can identify). I think that the lines between the 2 disciplines are becoming even more blurred than in the past (if that's possible). I previously stressed that machine learning was a tool facilitating the data mining process; however, as machine learning becomes a more mainstream term, I foresee their accelerated widespread confounding.
Deep learning is also a process; it is the application of deep neural network technologies -- neural network architectures (which are particular types of machine learning algorithms) with multiple hidden layers -- to solve problems. As a process, deep learning is to neural networks as data mining is to "traditional" machine learning (this is a somewhat flawed comparison lacking nuance, but at a very high level I stand by it).
Deep learning still isn't as widespread as one might think, given its dramatic uptick in attention and hyped success this past year. However, I definitely see it (slowly) becoming more of a go-to tool for data scientists over the next few years. As it becomes a go-to classification technology, however, it becomes increasingly important to remember that deep learning is not a panacea, nor is it even a valid option in a wide variety (majority?) of cases. Also, deep learning and artificial intelligence are not synonymous.
When I think of artificial intelligence, the following still rings true for me:
In my opinion, AI is a yardstick, a moving target, an unattainable goal.
But that doesn't mean that AI is not worthy of pursuit; AI research pays dividends in the form of inspiration and motivation. As you may have noticed, however, AI has a perception problem. Just as data mining used to be a mainstream term that struck fear into the hearts of many (mostly related to the invasion of privacy), AI frightens the masses from an entirely different viewpoint, one that evokes SkyNet-style fears. I don't know whether we thank the media, Elon Musk, the confounding of AI with deep learning and its successes, or something else entirely, but I don't think the end result is escapable: this perception issue is real, and the uninitiated are becoming terrified.
There is also this: though machine learning, artificial intelligence, deep learning, computer vision and natural language processing (along with a variety of other applications of these "intelligent" technologies) are all separate and distinct fields and application domains, even practitioners and researchers have to admit that there is some continually evolving "concept creep" going on any more, beyond the regular ol' confusion and confounding that has always taken place. And that's OK; these fields all started out as niche sub-disciplines of other fields (computer science, statistics, linguistics, etc.), and so their constant evolution should be expected. While it is important on some level to ensure that everyone who should have a basic understanding of their differences indeed possesses this understanding, when it comes to their application in fields such as data science, I would humbly submit that getting too far into the semantic weeds doesn't provide practitioners with much benefit in the long term.
Artificial and machine intelligence will look very different in 2030 than it does now, and not having a basic understanding of this evolving set of technologies and the research that fuels them, or being open to their application as data scientists, will have a detrimental effect on your long term success.
I previously defined data science as follows:
Data science is a multifaceted discipline, which encompasses machine learning and other analytic processes, statistics and related branches of mathematics, increasingly borrows from high performance scientific computing, all in order to ultimately extract insight from data and use this new-found information to tell stories.
I'm actually still quite comfortable with this definition. Of particular note, I have found over the past year that considerable confusion exists between the terms data science and data mining. While it's not settled law, I stand by the following:
Data science employs all sorts of different tools from a variety of related areas (see everything you've read above here). Data science is both synonymous with data mining, as well as a superset of concepts which includes data mining.
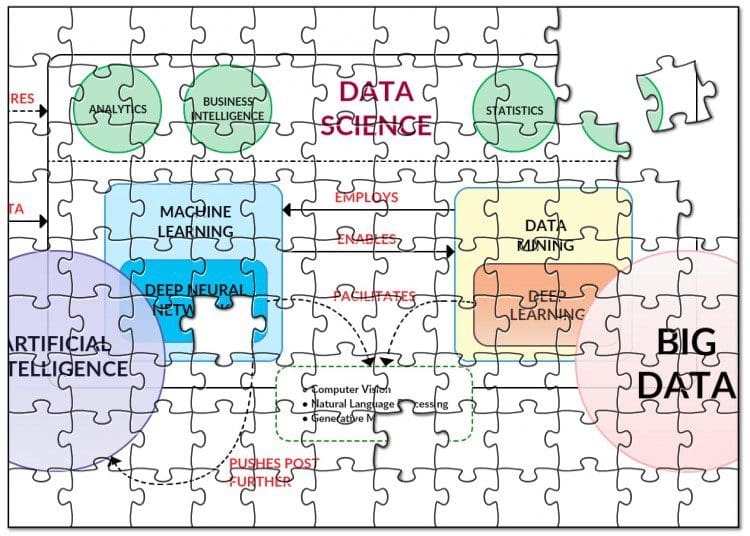
So while the original data science puzzle graphic is not totally outdated, I have modified it as shown below, in order to incorporate the above discussion points:

In particular, note the following:
- Big Data has become less important as a separate entity worthy of highlight (Big Data isn't coming any longer; it is just the reality)
- The relationships between AI, machine learning, and deep learning are always in flux to some degree, and will be continually reconsidered
- The metamorphosis of AI into an artificial & machine intelligence sphere, which reflects the increased importance of cognitive & intelligent technologies
- Natural language processing, computer vision, and generative models are more closely associated with a new artificial & machine intelligence relationship sphere, reflecting the realities on the ground
- The relationship between machine learning and data mining versus neural networks and deep learning has not been altered; however, it may become more important to demonstrate the functional relationships rather than highlight the analogous relations (as they are currently shown) in the near future (at least, more important in my mind)
- While I have made mention of high performance scientific computing and its role in data science, it is not shown in the graphic; I anticipate a likely change in this next year, given the increased importance of distributed and parallel capabilities -- including GPU parallelism -- along with the demand for raw computing resources in general
I am confident that data science will continue to evolve and adopt and/or absorb new tools and technologies into its toolkit, once their use to the profession becomes apparent. While I am still not totally comfortable with the term data science, there's no doubt that it exists, is real, and is welcomed wholeheartedly by many, and that its adoption rate only stands to increase over time.
And again, before you get too upset with any of the above, take it for what it is: just one man's opinion.
Related: