DBSCAN Clustering Algorithm in Machine Learning
An introduction to the DBSCAN algorithm and its implementation in Python.

In 2014, the DBSCAN algorithm was awarded the test of time award (an award given to algorithms which have received substantial attention in theory and practice) at the leading data mining conference, ACM SIGKDD.
Introduction
Clustering analysis is an unsupervised learning method that separates the data points into several specific bunches or groups, such that the data points in the same groups have similar properties and data points in different groups have different properties in some sense.
It comprises of many different methods based on different distance measures. E.g. K-Means (distance between points), Affinity propagation (graph distance), Mean-shift (distance between points), DBSCAN (distance between nearest points), Gaussian mixtures (Mahalanobis distance to centers), Spectral clustering (graph distance), etc.
Centrally, all clustering methods use the same approach i.e. first we calculate similarities and then we use it to cluster the data points into groups or batches. Here we will focus on the Density-based spatial clustering of applications with noise (DBSCAN) clustering method.
If you are unfamiliar with the clustering algorithms, I advise you to read the Introduction to Image Segmentation with K-Means clustering. You may also read the article on Hierarchical Clustering.
Why do we need a Density-Based clustering algorithm like DBSCAN when we already have K-means clustering?
K-Means clustering may cluster loosely related observations together. Every observation becomes a part of some cluster eventually, even if the observations are scattered far away in the vector space. Since clusters depend on the mean value of cluster elements, each data point plays a role in forming the clusters. A slight change in data points might affect the clustering outcome. This problem is greatly reduced in DBSCAN due to the way clusters are formed. This is usually not a big problem unless we come across some odd shape data.
Another challenge with k-means is that you need to specify the number of clusters (“k”) in order to use it. Much of the time, we won’t know what a reasonable k value is a priori.
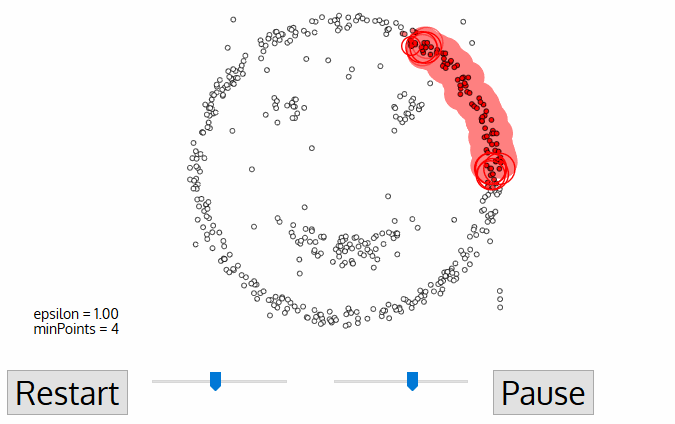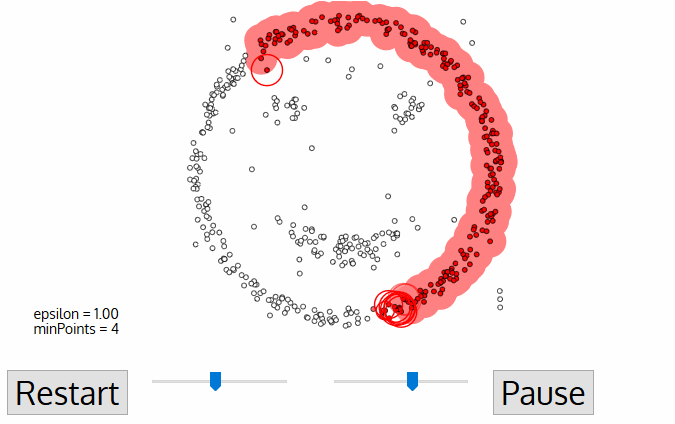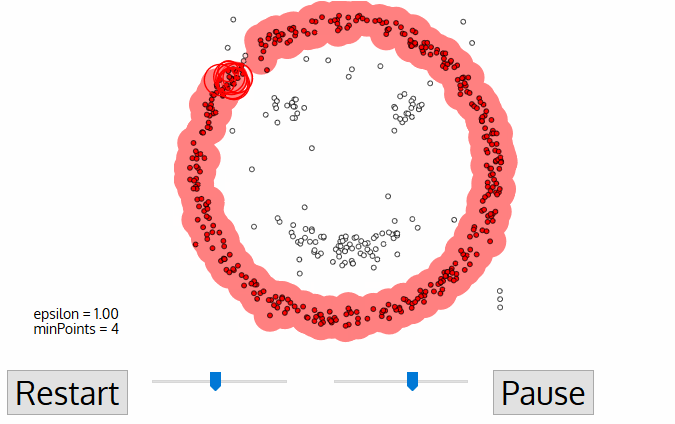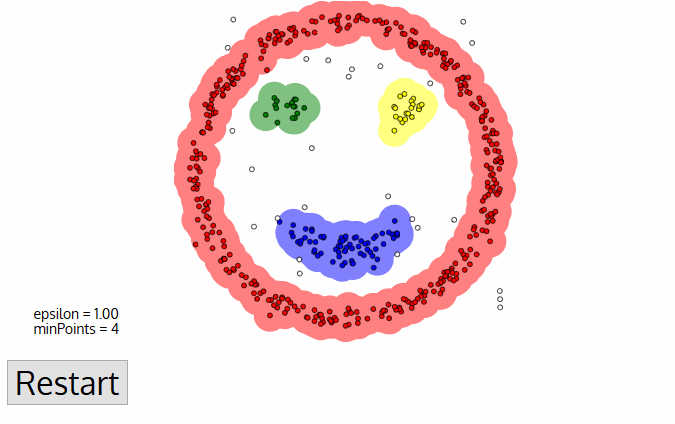
What’s nice about DBSCAN is that you don’t have to specify the number of clusters to use it. All you need is a function to calculate the distance between values and some guidance for what amount of distance is considered “close”. DBSCAN also produces more reasonable results than k-means across a variety of different distributions. Below figure illustrates the fact:

Density-Based Clustering Algorithms
Density-Based Clustering refers to unsupervised learning methods that identify distinctive groups/clusters in the data, based on the idea that a cluster in data space is a contiguous region of high point density, separated from other such clusters by contiguous regions of low point density.
Density-Based Spatial Clustering of Applications with Noise (DBSCAN) is a base algorithm for density-based clustering. It can discover clusters of different shapes and sizes from a large amount of data, which is containing noise and outliers.
The DBSCAN algorithm uses two parameters:
- minPts: The minimum number of points (a threshold) clustered together for a region to be considered dense.
- eps (ε): A distance measure that will be used to locate the points in the neighborhood of any point.
These parameters can be understood if we explore two concepts called Density Reachability and Density Connectivity.
Reachability in terms of density establishes a point to be reachable from another if it lies within a particular distance (eps) from it.
Connectivity, on the other hand, involves a transitivity based chaining-approach to determine whether points are located in a particular cluster. For example, p and q points could be connected if p->r->s->t->q, where a->b means b is in the neighborhood of a.
There are three types of points after the DBSCAN clustering is complete:
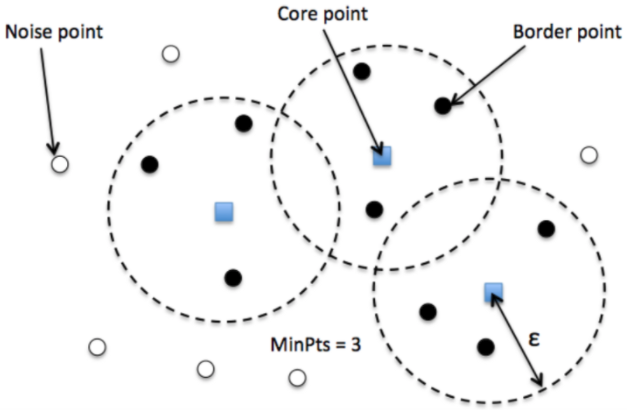
- Core — This is a point that has at least m points within distance n from itself.
- Border — This is a point that has at least one Core point at a distance n.
- Noise — This is a point that is neither a Core nor a Border. And it has less than m points within distance n from itself.
Algorithmic steps for DBSCAN clustering
- The algorithm proceeds by arbitrarily picking up a point in the dataset (until all points have been visited).
- If there are at least ‘minPoint’ points within a radius of ‘ε’ to the point then we consider all these points to be part of the same cluster.
- The clusters are then expanded by recursively repeating the neighborhood calculation for each neighboring point
Parameter Estimation
Every data mining task has the problem of parameters. Every parameter influences the algorithm in specific ways. For DBSCAN, the parameters ε and minPts are needed.
- minPts: As a rule of thumb, a minimum minPts can be derived from the number of dimensions D in the data set, as
minPts ≥ D + 1. The low valueminPts = 1does not make sense, as then every point on its own will already be a cluster. WithminPts ≤ 2, the result will be the same as of hierarchical clustering with the single link metric, with the dendrogram cut at height ε. Therefore, minPts must be chosen at least 3. However, larger values are usually better for data sets with noise and will yield more significant clusters. As a rule of thumb,minPts = 2·dimcan be used, but it may be necessary to choose larger values for very large data, for noisy data or for data that contains many duplicates. - ε: The value for ε can then be chosen by using a k-distance graph, plotting the distance to the
k = minPts-1nearest neighbor ordered from the largest to the smallest value. Good values of ε are where this plot shows an “elbow”: if ε is chosen much too small, a large part of the data will not be clustered; whereas for a too high value of ε, clusters will merge and the majority of objects will be in the same cluster. In general, small values of ε are preferable, and as a rule of thumb, only a small fraction of points should be within this distance of each other. - Distance function: The choice of distance function is tightly linked to the choice of ε, and has a major impact on the outcomes. In general, it will be necessary to first identify a reasonable measure of similarity for the data set, before the parameter ε can be chosen. There is no estimation for this parameter, but the distance functions need to be chosen appropriately for the data set.
DBSCAN Python Implementation Using Scikit-learn
Let us first apply DBSCAN to cluster spherical data.
We first generate 750 spherical training data points with corresponding labels. After that standardize the features of your training data and at last, apply DBSCAN from the sklearn library.

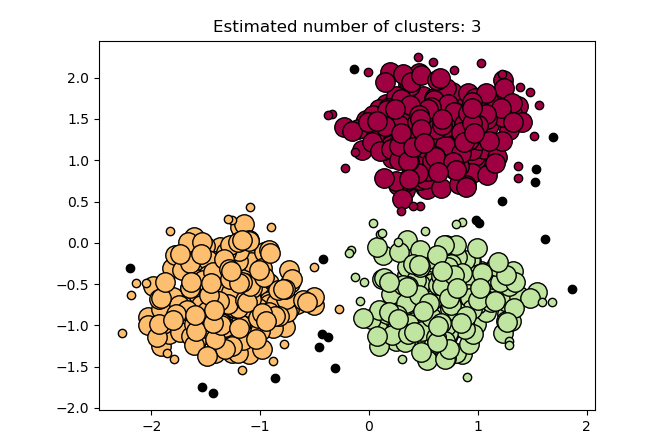
The black data points represent outliers in the above result. Next, apply DBSCAN to cluster non-spherical data.
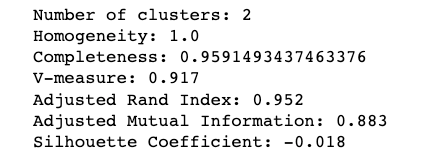
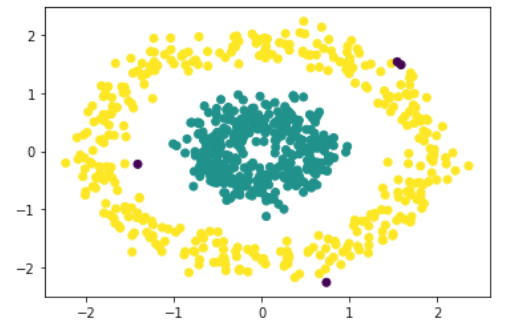
Which is absolutely perfect. If we compare with K-means it would give a completely incorrect output like:
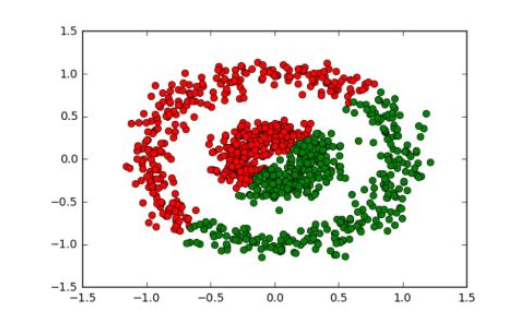
The Complexity of DBSCAN
- Best Case: If an indexing system is used to store the dataset such that neighborhood queries are executed in logarithmic time, we get
O(nlogn)average runtime complexity. - Worst Case: Without the use of index structure or on degenerated data (e.g. all points within a distance less than ε), the worst-case run time complexity remains
O(n²). - Average Case: Same as best/worst case depending on data and implementation of the algorithm.
Conclusion
Density-based clustering algorithms can learn clusters of arbitrary shape, and with the Level Set Tree algorithm, one can learn clusters in datasets that exhibit wide differences in density.
However, I should point out that these algorithms are somewhat more arduous to tune contrasted to parametric clustering algorithms like K-Means. Parameters like the epsilon for DBSCAN or for the Level Set Tree are less intuitive to reason about compared to the number of clusters parameter for K-Means, so it’s more difficult to choose good initial parameter values for these algorithms.
That is all for this article. I hope you guys have enjoyed reading it, please share your suggestions/views/questions in the comment section.
Thanks for Reading!
Bio: Nagesh Singh Chauhan is a Big data developer at CirrusLabs. He has over 4 years of working experience in various sectors like Telecom, Analytics, Sales, Data Science having specialisation in various Big data components.
Original. Reposted with permission.