 Peer Reviewing Data Science Projects
Peer Reviewing Data Science Projects
 Peer Reviewing Data Science Projects
Peer Reviewing Data Science ProjectsIn any technical development field, having other practitioners review your work before shipping code off to production is a valuable support tool to make sure your work is error-proof. Even through your preparation for the review, improvements might be discovered and then other issues that escaped your awareness can be spotted by outsiders. This peer scrutiny can also be applied to Data Science, and this article outlines a process that you can experiment with in your team.
By Shay Palachy, Data Science Consultant.
Peer review is an important part of any creative activity. It is used in research — both inside and outside academia — to ensure the correctness of results, adherence to the scientific method, and quality of output. In engineering, it is used to provide outside scrutiny and to catch costly errors early on in the process of technology development. Everywhere it is used to improve decision making.
Those of us working in the tech industry are familiar with one particular and very important instance of peer review — the code review process. If you’ve ever received a review, you should know that despite being slightly uncomfortable — as putting our creations under scrutiny always is — it can be highly valuable. This process forces us to prepare and, as a result, find numerous improvements to make even before the review. This often raises small but significant issues that have escaped our gaze but are easy for an outsider to spot, and sometimes it can provide very profound insights.
The goal of this post, then, is to suggest a layout for a process that performs a similar function for data science projects. It is built as part of my own personal view of how small-scale data science projects should be run, a topic that I have covered in a previous blog post: Data Science Project Flow for Startups. You can find a figure for this workflow below.
This framework is also based on my experience as a lead data scientist, team leader, and finally, an independent consultant, witnessing work patterns followed by various companies I consulted. I have also relied on the experience of many of my friends leading teams or groups of data scientists.
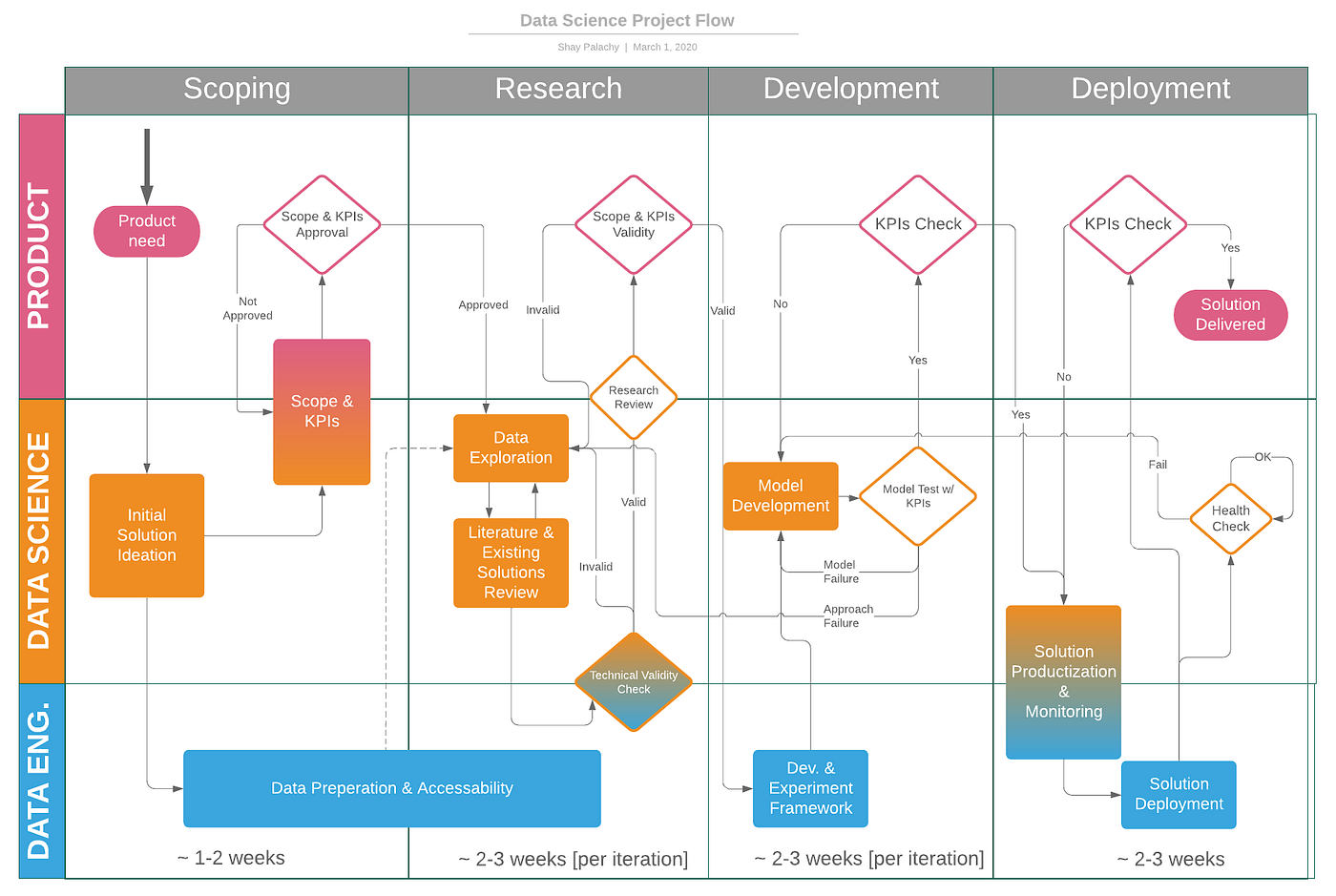
Figure 1: Data Science Project Flow (source: author).
In accordance with my view for a project flow, I suggest two different peer review processes for the two phases I feel require peer scrutiny the most: the research phase and the model development phase.
The goal, then, is to provide a general framework for a peer review process for both phases that will:
- Formalize the process and provide structure.
- Encourage data scientists to ask and provide peer review.
- Reduce the risk of costly errors.
I’ll discuss the motivation, goals, and structure for both processes, accompanying each with a unique list of questions and issues to check for.
Similar to the project flow, these processes were written with small teams working on applied data science in mind. However, larger teams or even research groups might find some of the ideas below useful.
Credits: The model development review checklist is the creation of Philip Tannor, an awesome data scientist and an even better person.
Data Science Research Phase Review
Just to jog your memory, we call “the research phase” that part in the process where we perform an iterative back-and-forth between data exploration and literature review (can include reviewing existing code and implementations). This phase also includes mapping out the space of possible methodological approaches to frame and solve the problem at hand, and forming our recommendation for the best way forward, complementing it by listing the advantages and risks inherent in each choice.

Figure 2: The three checks of the research phase (source: author).
Notice three types of checks are performed at this stage to validate the naturally impactful choice of approach:
- Technical validity check, often done together with data/software engineers supporting the project, is meant to ensure that the suggested approach can be successfully deployed and supported by engineering.
- Research review, where a peer helps the data scientist validate his process and recommendations. We’ll delve into this in a moment.
- Scope and KPIs validity check, done with the product person in charge, to ensure the recommended approach remains within the scope of the project and seems set to satisfy the project’s KPIs.
Motivation
I think that the main motivation for data scientists to get a peer review of the research phase of their projects is to prevent them from choosing the wrong approach or direction in this early phase of the project. These errors — referred to as approach failures in the DS workflow — are very costly to make, and they impede the project for the rest of its lifecycle.
If we’re lucky, we discover the approach failure after several model development iterations, and we lose precious weeks of data scientist work. This is the case where the approach failure leads to degraded performance when measured by using the metrics we’ve chosen to track and optimize.
In some cases, however, the performance discrepancies resulting from an approach failure are much more subtle and can be extremely hard to recognise before validating model performance using significant amounts of production data, and sometimes even user/client feedback to that behaviour, leading to discovery the failure only after the model is in production. And the cost is significantly higher: Months of work of data scientists, engineers and product people, a decline in client satisfaction, potential churn, and even reduced earnings.
This is why model benchmarking cannot be the only way we hope to find methodological errors in our process and decisions; we must explicitly assume they might escape detection by these means, and attempt to discover them methodologically, by examining the process itself, its logic and the claims and data supporting them.
Goals
Obviously, the main goal here is to catch costly errors early on, as mentioned above, by explicitly putting core aspects of the process under examination, while also performing a basic sanity check for several catch-alls.
However, two additional sub-goals can be stated here: First, improving the ability of the data scientist to explain and defend her decisions in upcoming product/business review process. Second, better preparing to present the output of the research phase to the rest of the team, an extremely common and important practice in most data science teams/groups.
Structure
There are three steps to prepare for the review are:
- The reviewed data scientist prepares a presentation (not necessarily slides) of the research process he went through.
- The reviewed data scientist sets up a long meeting (at least 60 minutes; it took us two hours last time) with the reviewer.
- The reviewer goes over the checklist (before the meeting).
In his presentation, the data scientist under review attempts to touch upon the following seven points:
- Reminder: Project scope and product need.
Always start from here, as a major point of the review is to estimate how well the process followed, and the choices made serve project scope and needs. - Initial guidelines and KPIs.
In many cases, this will be the first time the reviewing DS will see the translation of product needs to technical KPIs, and this is a good chance to expose this to peer scrutiny. Cover problem characteristics and constraints. - Assumptions made.
We all make strong assumptions about things like data format, availability, acceptable mistakes, and common product use patterns. Make them explicit. - Data used and how it was explored.
Data exploration results can justify both some assumptions and the choice of approach to be presented, so present them clearly. - List of possible approaches/solutions arrived at.
The first major output of the research phase: A map of the solution landscape, detailing the pros and cons of each — including assumptions — and possibly also portraying the origins and the relations between them, if relevant. - Selected approach going forward & justifications.
Your recommendation. This is the most salient output of this phase, but remember that to chart a course, you must first have a map. The context provided by the solution landscape should enable you to explain the choice to the reviewer, while also ruling out the alternatives. - What possible failures will lead to alternative choices?
I believe that this often-overlooked product of the research phase is no less important than your recommendation. You are now bolstering it with contingency plans, explicitly sharing how the inherent risk of a research-driven project can be hedged and accounted for.
Finally, here is a suggested structure for the review meeting:
- The DS under review: Research phase presentation
- Reviewer: General feedback
- Reviewer: Going over the checklist (see below)
- Reviewer: Approve or Reject
- Together: Resulting action points
Checklist
The list focuses on questions that should be addressed during the research phase. I have divided it into ten categories:
- Data Properties
- Approach Assumptions
- Past Experience
- Objective Alignment
- Implementation
- Scaling
- Compose-/Break-ability
- Information Requirements
- Domain Adaptation
- Noise/Bias/Missing Data Resilience
Let’s go over the questions. Remember, this is just a preliminary suggestion I came up with, not comprehensive coverage of everything that needs to be considered.
Data Properties
Regarding the initial dataset:
- How was the generated? How was it samples? Was it updated?
g., 10% of last month's data was sampled uniformly from each of the existing five clients. - What noise, sampling bias, and missing data did this introduce?
g., one of the clients only integrated with our service two weeks ago, introducing a down-sampling bias of his data in the dataset. - Can you modify sampling/generation to reduce or eliminate noise? Sampling bias? Missing data?
g., either upsample the under-sampled client by a factor of two or use data from only the last two weeks for all clients. - Can you explicitly model noise, independently from an approach?
- If the dataset is labeled, how was it labeled?
- What label bias did this introduce? Can it be measured?
g., the label might come from semi-attentive users. Labelling a very small (but representative) set by hand using experts/analysts might be tractable and will enable us to measure label bias/error on this set. - Can you modify or augment the labelling process to compensate for existing bias?
- How similar is the initial dataset to input data expected in production, structure, and schema-wise?
g., the content of some items changes dynamically in production. Or perhaps different fields are missing, depending on the time of creation, or the source domain, and are later completed or extrapolated. - How representative is the initial dataset of production data?
g. The distribution of data among clients constantly changes. Or perhaps it was sampled over two months of spring, but the model will go up when winter starts. Or it might have been collected before a major client/service/data source was integrated. - What is the best training dataset you could hope for?
- Define it very explicitly.
- Estimate: By how much will it improve performance?
- How possible and costly is it to generate?
g., tag the sentiment of 20,000 posts using three annotators and give the mode/average score as the label of each. This will require 400 man-hours, expected to cost two or three thousand dollars, and is expected to increase accuracy by at least 5% (this number is usually extremely hard to provide).
Approach Assumptions
- What assumptions does each approach make on the data/data generation process/the phenomenon under study?
- Is it reasonable to make these assumptions about your problem? To what degree?
- How do you expect applicability to relate to a violation of these assumptions? E.g., 10% violation → 10% reduced performance?
- Can these assumptions be validated independently?
- Any edge/corner cases which violate these assumptions?
Example: To determine whether a change in plane ticket prices drives an upsurge in the use of your service, you might want to use some classic causal inference statistical methods over a time series of both values. Alternatively, you might predict plane ticket prices for the next month using a common model like ARIMA.
Many such methods not only — sometimes implicitly — assume that input time series are realizations of stationary stochastic processes, but they also provide neither a measure of the degree of stationarity of a time series nor a degree to which it can violate this assumption. Finally, they provide no upper bound on errors— or the probability of making them— when this assumption is violated to any degree.
As such, this is a significant downside of these methods, and it should be presented and accounted for explicitly. In this case, stationarity can actually be tested independently, regardless of the method used, so the validity of certain methods can be ascertained before making a choice.
Here are some examples of some very strong and commonly implicit assumptions approaches make:
- Each feature follows a Gaussian distribution.
- Time series are realizations of a stationary process.
- Features are strictly independent (e.g., Naive Bayes assumes this).
- Separability of the measurements of different components in the system being measured.
Past Experience
- What experience do you have applying this approach, whether in general or to similar problems?
- Did you find any published (e.g., in a blog post or an article) success/failure stories of applying this approach to similar problems?
- Did you reach out to peers for their experience?
- What lessons are to be learned from the above?
- If this project is an attempt to iterate and improve upon an existing solution: What solutions were used to solve this problem so far? What were their advantages, and from what issues did they suffer?
Objective Alignment
For supervised learning methods based on optimization:
- Which loss functions can be used when fitting model parameters? How do they relate to project KPIs?
- Which metrics can be used for model selection/hyperparameter optimization? How do they relate to project KPIs?
- What hard constraints should be added to reflect KPIs?
For unsupervised learning methods:
- What measure does the method optimize?
- How does it relate to the KPIs?
g., how well does maximizing separability of averaged-word-vectors approximate finding a set of articles capturing different opinions on a topic? - What are some edge cases that satisfy the metric well but not the KPI?
For unsupervised representation learning:
- Why is the fake task (e.g., predicting the neighbour of a word in Word2Vec) expected to facilitate the learning of input representations that will benefit a model trying to perform the actual task?
Implementation
- Are there implementations of the approach in a language currently used in your production environment?
- Is the implementation up-to-date? Consistently supported? In wide use?
- Are there successful uses of this specific implementation by companies/organisations similar to yours? On problems similar to yours?
Scaling
- How does computation/training time scale with the number of data points?
- With the number of features?
- How does storage scale with data points/features?
Compose-/Break-ability
- Can models for different domains (categories/ clients/ countries) be composed in a sensible way, if required?
- Alternatively, can their results be integrated in a meaningful way?
- Can a general model be broken down into per-domain models? Can per-domain related inner-components of such a model be identified and utilized?

Figure 3: Model composability might be a requirement, and comes in different forms (source: author).
Example: Let’s assume we’re working on a topical dynamic playlist generation system, as part of a music streaming service. This means we want to generate and update playlists automatically around topics such as “New Indie”, “British New-Wave”, “Feminist Music” or “Cheesy Love Songs”. For added complexity, we might also want to allow playlists for combinations of topics, like “Feminist New-Wave” or “New Gloomy Indie”. Or perhaps, we want to be able to personalize each playlist to a listener. Eventually, if we have a model that ranks songs for inclusion in a topical playlist and another personalized model that ranks songs by how likely is a specific user to like them, we might want to be able to combine the results of two such models.
Different approaches can support these scenarios in different ways. For example, if we model each person/topic as a probability distribution over all songs, where playlists are generated on-the-fly by repeated samplings (without repetitions), any number of such models can easily be combined into a single probability distribution, and then the same process can be used to generate the adapted playlist. If, however, we use some ML model ranking songs using a score, we might have to devise a way to make scores of different models comparable, or use generic ways to integrate several rankings over the same set of items.
Information Requirements
- To what degree does each approach rely on the amount of available information? What is the expected impact on the performance of small amounts of information?
- Does this align well with the amount of currently available information? With future availability?
For example, training a neural-network-based sequence model for text classification from scratch usually requires a lot of information if you can’t rely on pre-trained models or word embeddings. If, for example, we’re building a script-or-module classifier for code files, this might be exactly the situation we’re in. In this case, and assuming each programming language represents an independent domain, NN models might not function well for very rare programming languages or those we have very few labels for.
Cold Start & Domain Adaptation
- How fast will new clients/categories/countries/domains be expected to reach the minimal information requirements of each approach?
- Can a general model be expected to perform well for them, at least as a starting point?
- Is there a way to adapt an already-fitted model to a new domain? Is this expected to yield better performance than training from scratch? Can this be done faster/cheaper than training from scratch?
Example: Let’s say we are building a recommendation system for products in our online marketplace, used by numerous merchants, where new merchants join and start to sell their products every day. Using a neural-network-based model that learns an embedding for merchants — and/or their products — over some data representing them can perform surprisingly well for such new merchants by mapping them close to similar existing merchants in the embedding space, and then drawing upon the knowledge already learned on how likely different shoppers are to purchase certain products from existing merchants.
Noise/Bias/Missing Data Resilience
Does the approach handle noise in the data? How?
- Does it model it specifically?
- If so, consider: How applicable is the noise model to the noise generating process in your problem?
- For anomalies/prediction/causality/dynamics: Does the approach model exogenous variables in the system?
For supervised and semi-supervised methods:
- How sensitive is each approach to bias in labelling?
- What are the implications of a biased model in your case?
- Are generic bias-correction techniques applicable to the approach?
For all methods:
- How does each approach handle missing data, if at all?
- How badly is performance expected to degrade as missing data increases, in each case?
Data Science Model Development Phase Review
Again, recall that what I call the model development phase is the part of the data science project where a lot of data processing is done (including feature generation, if used), actual models are applied to actual data — in supervised scenarios they are trained or fitted — and are benchmarked using some predetermined metric, often on a set aside test/validation set.
You can think of the whole thing as one big iteration — no matter how many approaches are examined — but I prefer to think of it as several iterations, each dedicated to a single approach. These are either carried out in parallel, or in sequence, by the ranking we outlined at the end of the research phase, where an approach failure — estimating that model sub-performance is due to basic inapplicability or mismatch of the current approach to the problem — leads to a new model development iteration over the next-best approach.

Figure 4: The two checks of the model development phase (source: author).
Similar to all other phases, the final checkpoint is a joint discussion with the product manager in charge to validate that the model-to-be-deployed actually satisfies project KPIs. Yet before that, another review is given by a peer.
Motivation and Goals
As in the research review, the motivation here is that model development phase errors can also be costly. These errors are almost always discovered in production and may require active model monitoring to catch. Otherwise, they are caught late in the productization phase, while requiring a developer/data engineer and exposing gaps between implicit assumptions made about engineering capabilities or the production environment; the technical validity check done at the end of the research phase is meant to mitigate some of these errors. However, since many of them are (1) technical, (2) implementation-based, and (3) model-specific, they can often only be examined during and after this stage, and so the model development review also handles them.
The goals, thus, are the same: First, providing a structured review process to the model development phase that will increase peer scrutiny by formally incorporating it into the project flow. Second, reducing the risk of costly errors by examining a prepared list of questions and issues to check for based on the valuable experience of other data scientists who had to tackle them.
Structure
There are three simple steps to make in preparation for the review:
- The reviewed data scientist prepares a presentation (not necessarily slides) of the model development process.
- The reviewed data scientist sets up a thorough meeting (at least 60 min.) with the reviewing data scientist.
- The reviewing DS goes over the checklist (before the meeting).
The data scientist under review should cover the following points in his presentation:
- Reminder: Project scope and product need
- Selected approach after the research phase
- Metric + soft & hard constraints for model selection
- Data used, preprocessing and feature engineering
- Models examined, training regime, hyperparameter optimization.
- Selected model, alternatives & pros/cons of each.
- Next steps: Automation, productization, performance optimization, monitoring, etc.
The same structure is suggested here for the review meeting:
- Reviewed DS: Model development phase presentation
- Reviewer: General feedback
- Reviewer: Going over the checklist (see below)
- Reviewer: Approve or Reject
- Together: Resulting action points
Checklist
Again, Philip Tannor created a checklist of questions and issues to use when reviewing the model development phase, divided into the following categories:
- Data Assumptions
- Preprocessing
- Leakage
- Causality
- Loss/Evaluation Metric
- Overfitting
- Runtime
- Stupid Bugs
- Trivial Questions
There is no point in replicating the list here, especially since Philip plans to maintain, so just go and read his blog post.
Original. Reposted with permission.
Bio: Shay Palachy works as a machine learning and data science consultant after being the Lead Data Scientist of ZenCity, a data scientist at Neura, and a developer at Intel and Ravello (now Oracle Cloud). Shay also founded and manages NLPH, an initiative meant to encourage open NLP tools for Hebrew.
Related: