Faster machine learning on larger graphs with NumPy and Pandas
One of the most exciting features of StellarGraph 1.0 is a new graph data structure — built using NumPy and Pandas — that results in significantly lower memory usage and faster construction times.
By Huon Wilson, CSIRO Data61

This week, StellarGraph released a new version of its open source library for machine learning on graphs. One of the most exciting features of StellarGraph 1.0 is a new graph data structure — built using NumPy and Pandas — that results in significantly lower memory usage and faster construction times.
Consider that a graph created from Reddit, with more than 200 thousand nodes and 11 million edges, required almost 7GB of memory with previous iterations of the library’s graph data structure. It also took 2.5 minutes to construct.
In the new StellarGraph class’s minimal form, that same Reddit graph now uses approximately 174MB. And this isn’t even a classic ‘memory versus time’ balance: the new form takes only 0.9 seconds to construct.
That is, the new StellarGraph class is 40 times smaller to store and hundreds of times faster to construct than the old StellarGraph.
In this article, we’ll explore how a careful focus on what works best for graph machine learning — in this case replacing StellarGraph’s graph data structure from one built on NetworkX to one built using NumPy and Pandas — led to big performance enhancements in the StellarGraph class.
A class above
The StellarGraph library is an open source, user-friendly library for graph machine learning. A graph is a collection of nodes and the edges between them, where the edges represent some connection or relationship between the nodes.
The core abstraction in the library is the StellarGraph class, which is a graph data structure that manages all the information about the graph or graphs being used for machine learning.
Previous versions of the StellarGraph class were backed by NetworkX, which allowed for quick and effective development of many graph machine learning algorithms because of its convenient and flexible API, built using nested dictionaries.
However, this flexibility meant it wasn’t optimised for graph machine learning: NetworkX has different trade-offs than those best for machine learning, the most notable being the amount of memory required to store a graph.
So, over the releases leading up to 1.0, the NetworkX-backed graph data structure was replaced with a new one built using NumPy and Pandas.
How does it work?
There are three key parts to the new StellarGraph class:
- Efficient storage of edges
- Keeping node features available for quick indexing
- Support for arbitrary node IDs.
Efficient storage of edges
The new StellarGraph class stores most of its data using NumPy arrays.
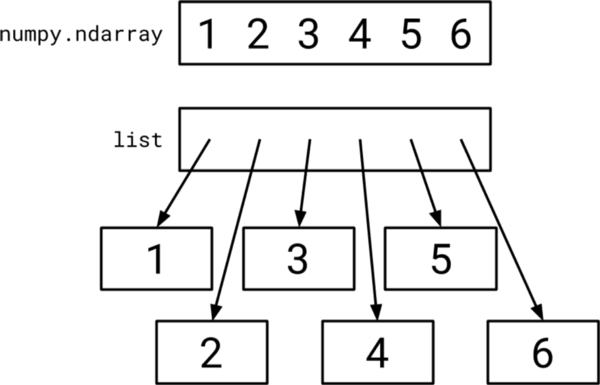
These arrays lay data out contiguously in memory, so that an array of four byte integers (like the numpy.int32 type) requires only four bytes per element. This is different to a Python list of the same integers, which requires ten times more memory, at 43 bytes per element.
The edges of the graph are conceptually pairs of a source node ID and a target node ID, representing the connection between the two nodes. In the new StellarGraph class, the edges are stored as NumPy arrays containing the source and targets in a “structure of arrays” style.
This explains a significant fraction of the reduction in memory use for the Reddit graph. The edge information can be placed contiguously in memory with no overhead from Python objects. By using NumPy natively, we also get to easily leverage the efficient sparse matrix and graph algorithms provided by the SciPy library.
Keeping node features available for quick indexing
NumPy arrays are also used for node features. StellarGraph is optimised for machine learning, which typically means working with vectors of “features”, or lists of numbers that encode information about each entity. Any StellarGraph graph can have nodes of multiple types, with a different number of features associated with every node of each type.

The new StellarGraph class stores the node features by having a large rectangular 2D NumPy array for each node type: for a particular node type, the first row of the array represents the features for the first node of that type, similarly for the second row, and so on.
This encoding is very memory efficient, since numeric features can be all laid out with no overhead from Python objects, just like edges. It is also fast, because queries about the features of nodes at given locations in the array can be answered by slicing out rows from the array, which is implemented as native C code in the NumPy library.
Support for arbitrary node IDs
Querying this data structure requires some tricks. It is great for storage, but actually getting the features of a node requires knowing its location; whether it’s the first or tenth or hundredth node of its type.
One approach is to just require that all node IDs are sequential integers, starting from 0, so all graphs with three nodes have IDs 0, 1, 2. However, this makes the library hard to use with real world datasets where the IDs might be UUIDs, random values, or some other non-trivial encoding. It quickly gets more complicated in heterogeneous graphs, with more than one type of node.

Thus, the final key piece of the new StellarGraph class is using the pandas.Index types to provide a translation between convenient and conventional node IDs and the sequential integers so that any node ID values can work, and the users of the class don’t have to think about doing their own translation or management.
The Pandas Index types are being used as a time- and memory-efficient dictionary, mapping IDs to sequential integers (which both StellarGraph and Pandas call “ilocs”, meaning integer locations). It leverages Pandas’ optimised C and Cython native code.
These ilocs are used as part of the edge storage discussed above. The ilocs are small integers, and so the contiguous layout of a NumPy array ensures our edges are always stored efficiently. Many of StellarGraph’s algorithms work directly with these ilocs, and so see no overhead due to the “fancy” IDs.
There are some additional details here. For example, the nodes are actually numbered globally in the index, not per type, so the graph above would have A → 2, B → 3, …, but most of these are shielded from the user.
In summary —
StellarGraph is easy to install and easy to use because it builds on the shoulders of giants. By using NumPy and Pandas we get most of the benefits of optimised native code without having to write the low-level code ourselves — which would require careful optimisation and risk serious memory-corruption bugs — or be concerned with having to carefully distribute it for every platform.
The new StellarGraph class delivered in 1.0 uses NumPy and Pandas to reduce memory use and improve speed through careful selection of the moving parts, and by focusing on just what is required for graph machine learning. Building on existing libraries gives us the benefits of native code without the problems.
To get started with graph machine learning with the new StellarGraph class in the StellarGraph library, pip install stellargraph, and then create a new optimised graph object with your data with StellarGraph(nodes, edges). There are demos with all the details.
This work involved major contributions, research and code from Andrew Docherty, Geoff Jarrad, Huon Wilson and Kieran Ricardo. We’re working on even more improvements top of this optimised base, that should improve memory use and speed even further, such as #718.
This work is supported by CSIRO’s Data61, Australia’s leading digital research network.
Bio: Huon Wilson is a software engineer with a strong background in mathematics and statistics, with significant experience in low-level systems programming fields like compilers, and languages like C++, C as well as more exotic ones like Rust. At a higher level, he has experience with numerical programming in R and Python, and with most language paradigms and many other areas of software engineering.
Original. Reposted with permission.
Related:
- Graph Neural Network model calibration for trusted predictions
- Scalable graph machine learning: a mountain we can climb?
- Graph Machine Learning Meets UX: An uncharted love affair