Optimize Response Time of your Machine Learning API In Production
This article demonstrates how building a smarter API serving Deep Learning models minimizes the response time.
By Yannick Wolf, Lead Data Scientist @ Sicara
This article demonstrates how building a smarter API serving Deep Learning models minimizes the response time.

Your team worked hard to build a Deep Learning model for a given task (let's say: detecting bought products in a store thanks to Computer Vision). Good.
You then developed and deployed an API that integrates this model (let's keep our example: self-checkout machines would call this API). Great!
The new product is working well and you feel like all the work is done.
But since the manager decided to install more self-checkout machines (I really like this example), users have started to complain about the huge latency that occurs each time they are scanning a product.
What can you do? Buy 10x faster—and 10x more expensive—GPUs? Ask data scientists to try reducing the depth of the model without degrading its accuracy?
Cheaper and easier solutions exist, as you will see in this article.
A basic API with a big dummy model
First of all, we'll need a model with a long inference time to work with. Here is how I would do that with TensorFlow 2's Keras API (if you're not familiar with this Deep Learning framework, just step over this piece of code):
When testing the model on my GeForce RTX 2080 GPU, I measured an inference time of 303 ms. That's what we can call a big model.
Now, we need a very simple API to serve our model, with only one route to ask for a prediction. A very standard API framework in Python is Flask. That's the one I chose, along with a WSGI HTTP Server called Gunicorn.
Our unique route parses the input from the request, calls the instantiated model on it and sends the output back to the user.
We can run our deep learning API with the command:
gunicorn wsgi:appOkay, I can now send some random numbers to my API and it responds to me with some other random numbers. The question is: how fast?
Let's load test our API
We indeed want to know how fast our API responds, and especially when increasing the number of requests per second. Such a load test can be performed using Locust Python library.
This library works with a locustfile.py which indicates which behavior to simulate:
Locust simulates several users, executing different tasks at the same time. In our case, we want to define only one task which is to call the /predict route with a random input.
We can also parametrize the wait_time, which is the time a simulated user waits after having received a response from the API, before sending his next request. To simulate the self-checkout use case, I've set this time to be a random value between 1 and 3 seconds.
The number of users is chosen through Locust's dashboard, where all the statistics are shown in real-time. This dashboard can be run by calling the command:
locust --host=http://localhost:8000 # host of the API you want to load test
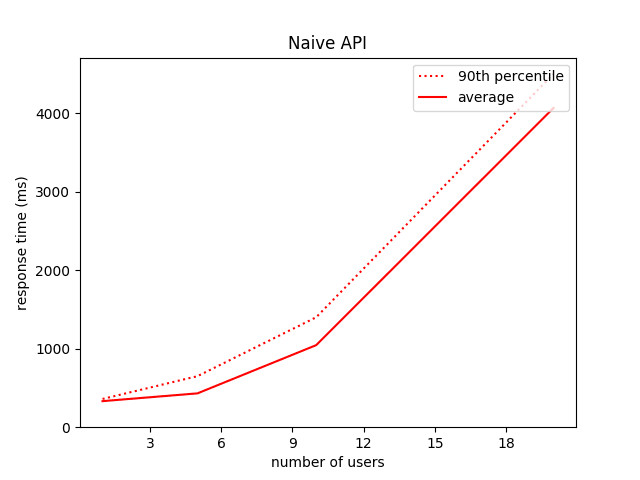
So, how does our naive API react when we increase the number of users? As we could expect, quite badly:
- with 1 user, the average response time I measured was 332 ms (slightly more than the isolated inference time previously measured, nothing surprising)
- with 5 users, this average time increased a little bit: 431 ms
- with 20 users, it reached 4.1 s (more than 12 times more than with 1 user)
These results are not so surprising when we think of how requests are handled by our API. By default Gunicorn launches 2 processes: a master process listen to incoming requests, stores them into a FIFO queue, and sends them successively to a worker process, each time it's available. The latter manages to run your code to compute the response for each request.
Since the worker process is single-threaded, requests are handled one by one. If 5 requests arrive simultaneously, the 5th request will receive its response after 5 x 300 ms = 1500 ms, which explains the high average response time with 20 users.
The more the faster
Luckily, Gunicorn provides two ways to scale APIs by increasing:
- the number of threads handling requests
- the number of worker processes
The multi-threading option is not the one that may help us the most since TensorFlow would not allow a thread to access the session graph initialized in another thread.
On the other hand, setting a number of workers greater than one would create several processes, with the whole Flask app initialized for each worker. Each one instantiates its own TensorFlow session with its own model.
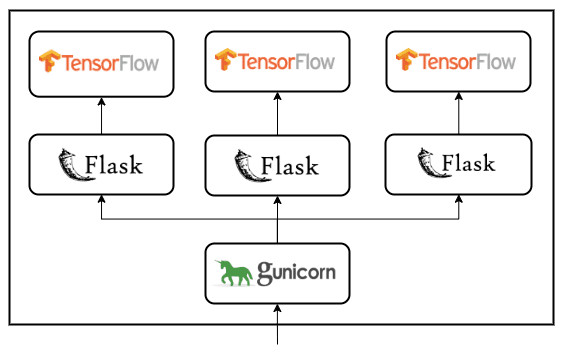
Let's try this approach by running the following command:
gunicorn wsgi:app --workers=5And here are the new performances we get with a multi-workers API:
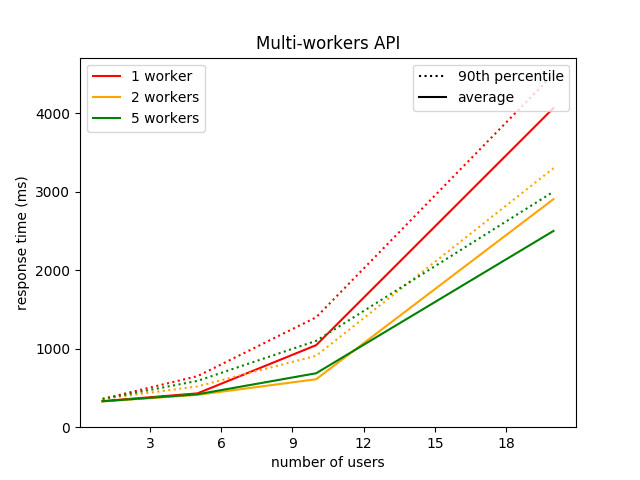
You can see that the effect on response time when using 5 workers instead of 1 is drastic: the 4.1 s average for 20 users has almost been divided by 2. By 2 and not by 5 as you might expect, because of the wait time between requests — it would have been divided by 5 if the simulated users were immediately requesting the API again after having received a response.
You may wonder why I stopped to 5 workers: why not to set-up 20 workers, to be able to handle all the 20 users requesting the API at the exact same time? The reason is that each worker is an independent process that instantiates its own version of the model in the GPU memory.
20 workers would thus consume 20 times the size of the model just for initializing the weights, and more memory is then needed for inference computing. With a 2GiB model and an 8GiB GPU, we are a bit limited.
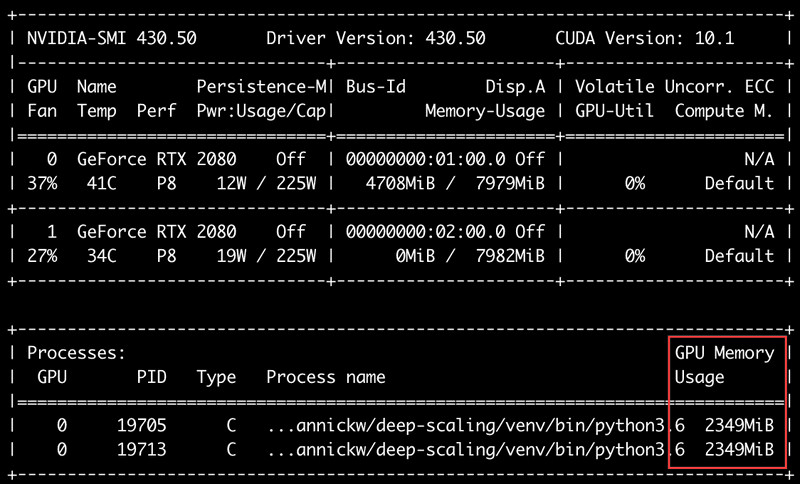
It's possible to maximize the number of running workers, by fine-tuning the memory allocated to each of them with a TensorFlow parameter (per_process_gpu_memory_fraction in TensorFlow 1.x, and memory_limit in TensorFlow 2.x — I've only tested the first one), setting it to the minimal value which does not make predictions fail with an out of memory error.
As warned by the library, reducing the available memory could theoretically increase inference time by disabling optimization. However, I did not personally notice any significant change.
Anyway, this will not allow us to run 20 workers, even using our 2 GPUs. So, let us buy 2 more? Don't panic, you have more than one string to your bow.
Haste makes waste
Let us come back to the mono-worker case for now. If you think about how things happen when two or more requests arrive almost at the same time to this API, there is something unoptimized:
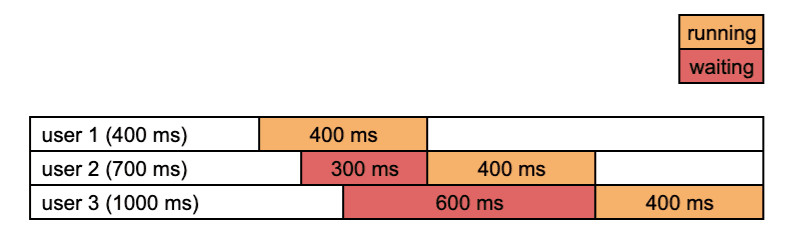
The API passes the 3 inputs through the model one by one. However, most Deep Learning models, thanks to the nature of the mathematical operations they are made of, can process several inputs at the same time without increasing inference time — that's what we call batch processing, and that's what we usually do during the training phase.
So, why not processing these 3 inputs in a batch? This would imply that after receiving the first request, the API waits a bit before running the model, in order to receive the 2 next requests before processing them all in one. This would increase the response time for the first request but decrease it on average.
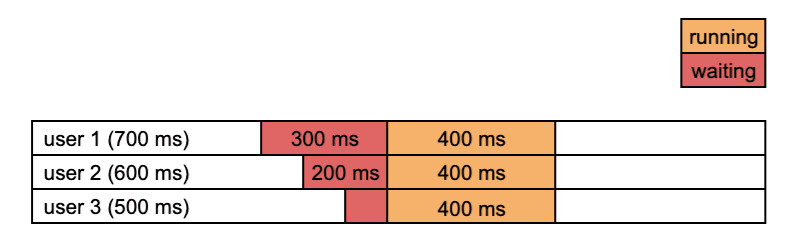
In practice, we do not know when future requests will arrive, and it's a bit complex to decide how long to wait for potential next requests. A quite logical rule to trigger processing of queued requests is to do it:
- if the number of queued requests has reached a maximum value, corresponding to the GPU memory limit or the maximum number of users (if known)
OR
- if the oldest request in the queue is older than a timeout value. This value has to be fine-tuned empirically to minimize the average response time.
Here is a way to implement such behavior, still with a Gunicorn - Flask - TensorFlow stack, using a Python queue and a thread dedicated to handling requests by batch.
This new API has to be run with as many threads as the maximum number of requests we want to be able to process in batch:
gunicorn wsgi:app --threads=20Here are the very satisfying results I've got after a very quick fine-tuning of the timeout value:
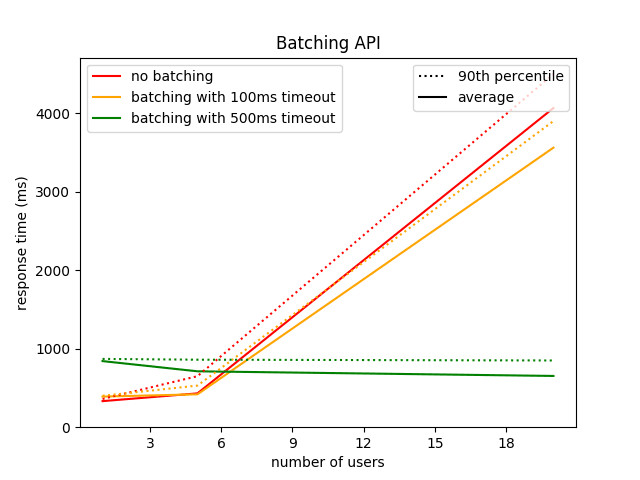
As you can see, when simulating only 1 user, this new API set-up with a timeout of 500 ms increases response time by 500 ms (the timeout value) and is of course useless. But with 20 users, the average response time has been divided by 6.
Note that in order to get still better results, this batching technique can be used in parallel with the multi-workers one presented above.
Didn't we reinvent the wheel?
As developers, it's a kind of guilty pleasure to code from scratch something that should very likely already be implemented by an existing tool and that's what we've just done all along this article.
A tool indeed exists for serving a TensorFlow model in an API. It has been developed by TensorFlow and it is called... TensorFlow Serving.
Not only does it allow to start a prediction API for the model without writing any other code than the model itself, but it also provides several optimizations that you may find interesting, like parallelism and requests batching!
To serve a model with TF Serving, the first thing you need is to export it to your disk (in the TensorFlow format, not the Keras one), which can be done with the following piece of code:
Then, one of the easiest ways to start a serving API is to use the TF Serving docker image.
The command below will start a prediction API that you can test by requesting this endpoint: http://localhost:8501/v1/models/my_model:predict
docker run -p 8501:8501 \
--mount type=bind,source=/path/to/my_model/,target=/models/my_model \
-e MODEL_NAME=my_model -it tensorflow/servingNote that it does not use the GPU by default. You can find in this documentation how to make it work.
What about batching? You will have to write such a batching config file:
max_batch_size { value: 20 }
batch_timeout_micros { value: 500000 }
max_enqueued_batches { value: 100 }
num_batch_threads { value: 8 }It includes, in particular, the 2 parameters used in our custom implementation: max_batch_size and batch_timeout_micros parameter. The latter is what we called the timeout and has to be given in microseconds.
Finally, the command to run TF Serving with batching enabled is:
docker run -p 8501:8501 \
--mount type=bind,source=/path/to/my_model/,target=/models/my_model \
--mount type=bind,source=/path/to/batching.cfg,target=/batching.cfg \
-e MODEL_NAME=my_model -it tensorflow/serving \
--enable_batching --batching_parameters_file=/batching.cfgI tested it and thanks to some black magic, I got even better results than with my custom batching API:
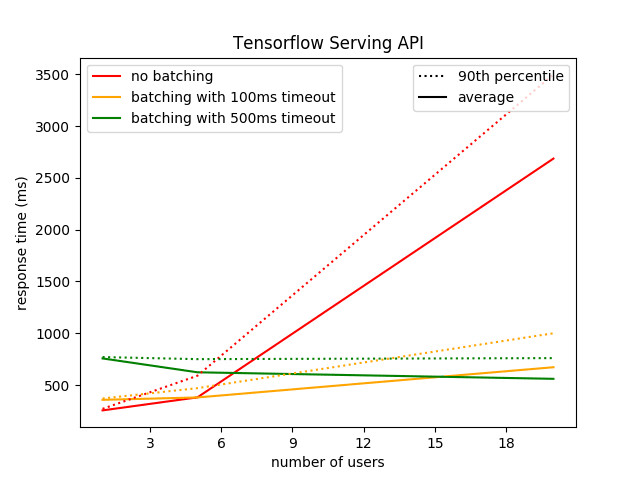
I hope that you will be able to use the different tips presented in this article to boost your own Machine Learning APIs. There are many tracks I did not explore, especially the optimizations on the model itself (rather than the API) like Model Pruning or Post-training Quantization.
Bio: Yannick Wolf is Lead Data Scientist at Sicara.
Original. Reposted with permission.
Related:
- Software Interfaces for Machine Learning Deployment
- TensorFlow 2.0 Tutorial: Optimizing Training Time Performance
- How to Do Hyperparameter Tuning on Any Python Script in 3 Easy Steps