 First Steps of a Data Science Project
First Steps of a Data Science Project
 First Steps of a Data Science Project
First Steps of a Data Science ProjectMany data science projects are launched with good intentions, but fail to deliver because the correct process is not understood. To achieve good performance and results in this work, the first steps must include clearly defining goals and outcomes, collecting data, and preparing and exploring the data. This is all about solving problems, which requires a systematic process.
By Favio Vazquez, CEO, Closter.

Data science should be implemented in a way that enables decision making to follow a systematic process. To be able to have that, we need a plan and a methodology to do a data science project. Sadly, most data science projects fail because the people involved don’t understand clearly what they have to do, or what are the most important things for a company. Your solution needs to be tied to the goals and objectives of the company or its departments.
In this article, I’ll talk about the first steps of a data science project and what to do to achieve good performance and results in your work. This is a first approach to the whole picture of a data science project that I’ll be talking about in later articles.
But first, I'll tell you a little story on how data science develops in a company (in a common scenario). This is what happens:
- You have a lot of data that you have been collecting for months or years, and someone says: “We have a lot of data, we have to do something about it.”

- The company decides to create new areas to start thinking about how to use data to make decisions. New people are hired to work in these newly created fields.
- The business problems are being transformed into data science problems, and you want to use data to solve them. The company hires “data scientists” and people to collect and analyze data. Someone has to prioritize the problems, and then pass them to the teams.



- With the data science practice in place, you start solving problems with data, using machine learning, statistical analysis, and more. There’s a lot of use cases for the data science departments, and everyone wants to join the revolution.
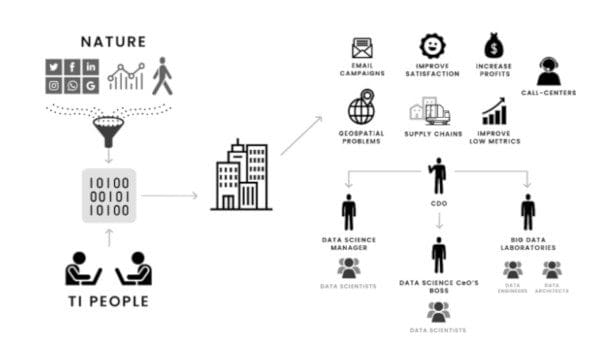
So as you can see, the process comes from necessities, but that’s not always the case. There are companies that start with a data science mindset, so the process could be a little different.
To begin, we need to define the first steps of a data science project:
Business Understanding
A crucial step in the process of any data science project is getting the context of a company and a project. With context, I mean all the specifics on how a company runs its projects, how the company is established, its competitors, how many departments exist, the different objectives and goals they have, and how they measure success or failure.
For a project, it’s the same process. You have to know all of the above and also the expectations, what every person in it will do, and how the project fits within the department running it, also how many people are involved and what is expected from you.
Data collection and ingestion
Data collection is the systematic process of gathering and measuring information on variables of interest that enables answering research questions, test hypotheses, and evaluate outcomes.
There are several ways of working in the data space and several roles as well. But the common thing they have is that they all use data. And you want to be able to have the best possible data when solving business problems.
Collecting data needs a process. It's not just getting data out of nowhere, we have to do it consistently, it's not random, we have to plan for it, and also it depends on engineers, data architects, DataOps and more people than just the data scientist.
One of the hardest things, when you are working with a new dataset, is to discover the most important features for predicting your target, and also, where you can find new sources of information that can improve your understanding of the data and your models.
An amazing amount of data is out there just waiting for you, ready to go, and it's what's called open data. Now, the idea with open data is this. It's data that is free, it's easily accessible, and it's downloadable in convenient forms like, for instance, a CSV or comma-separated values, which is a common form of spreadsheet data.
Exploratory data analysis and data preparation
After you gather your data, you need to understand it and analyze it. The process of data analysis and preparation is where you can check if the previous steps were done correctly, or maybe you need to think about the business case again, or maybe you need more data or different data.
This is where you will be applying a lot of concepts from statistical analysis and also algebra to get the most out of your data. There are great tools to analyze data for free like SQL, Python, or R, or you can do it even with tools like Excel, or if you have the possibilities, you can use platforms like Tableau, PowerBI, and Explorium.
You need to remember that Data science isn’t about software, knowing how to code, or being able to read data from different databases. It is about solving problems. An analogy would be saying that physics isn’t about calculus, moving objects, algebra; it’s about studying nature, understanding it, and modeling it.
Also, data science is an iterative process. Iterating, over and over again, rethinking the business process and needs, experimenting a lot, listening what the data have to say, understanding and encouraging the business to understand that the data’s opinion must always be included in product discussions, finding a critical path to solve the problem and then organizing the team around completing it and going further, letting the models solve the problems, of course using our expertise to help them, but not biasing them.
Data science goes from data to value, but we need to have a good starting point. If you have a poor understanding of the business context, even if you are an expert in machine learning, you will not be able to solve the problem. If you don’t collect the data following a systematic process that enables you to get the best sources of information and use the data you already have, it’s impossible to achieve your goals, and finally, if you don’t take the time to analyze and prepare the data, you will not be able to validate the last steps and come up with hypotheses for the drivers of the identified problems.
There are a lot of places to find this type of data, but it may be complicated to gather it some times. Luckily we have tools like Explorium that make everything easy - learn more about Explorium here.
Related: