Why would you put Scikit-learn in the browser?
Honestly? I don’t know. But I do think WebAssembly is a good target for ML/AI deployment (in the browser and beyond).
By Maurits Kaptein, Tilburg University
In my own academic work, and in working with various companies and hospitals, I often face the challenge of moving validated models into production. Deployment turns out to be hard; it is one of the prime barriers holding up adoption of many useful models in various fields. After trying out various solutions, we decided on the use of WebAssembly binaries for model deployment. Now, this choice is not always understood: many data scientists have not yet heard about WebAssembly and if they have they mostly associate it with running tasks in the browser. Also, interested readers will quickly find projects like pyodide, which, while super interesting, puts readers on the wrong foot in suggesting that model deployment could be done by moving the full python stack to the browser: that’s not how we think about it. We simply regard WebAssembly as a safe, portable, and efficient compile target to deploy fitted models anywhere. In this piece I will try to explain our reasoning behind this choice of technology.
Desiderata: what would we like when putting models in production?
Choosing a technology often benefits from having a good set of desiderata (requirements if you wish): what would we like our technology to do? Here are a few things we considered for AI/ML model deployment:
Note: I am treating the notion of a “model” quite broadly here; this might include pre- and post-processing. Effectively, when generating inferences often the “model” is just a set of operations carried out on some input data leading to some output.
- We would like a minimal impact on the work-practices of those creating and validating models. Effectively, it would be great if Data Scientists / researchers that are building and validating useful models could use their preferred tools also for deployment. It should be easy.
- We would like deployed models to be computationally efficient (i.e., be fast). While during training execution speed might not be a big issue (although training speed might very well be), it will be an issue when we want to generate inferences repeatedly. Once you are evaluating a model thousands of times a second, it is nice if it runs fast.
- We would like deployed models to have a small memory footprint. In deployment it would be great if inferences are not only efficient time-wise, but also memory-wise. A small and fast task ultimately improves user experiences, reduces costs, and saves significant amounts of energy.
- We would like deployed models to be portable. We should not have to rebuild models when we move them from servers to IoT devices to mobile phones to web-browsers.
- We would like deployed models to be safe and verifiable. A model should run safely and sand-boxed, and it should be possible to verify that the correct model is available.
- We would like to be able to experiment easily with deployed models. Once models are deployed it should be possible to easily A/B test various versions of a model.
Deployment using WebAssembly
Given the desiderata above we looked at several technologies varying from putting jupyter notebooks in production using docker containers, to rebuilding our models in c or rust and compiling executables for various runtimes, to using one of the ever-growing suit of products currently on offer to make putting models into production easier (i.e., pyTorch, TFX, Lambda, Azure, etc.). All failed in one way or another. Docker containers allow you to simply copy your existing Python stack, packages, model, and all, but the resulting containers are often bloated and slow. Rebuilding is performant but time-consuming. Existing cloud services score well on some, but never all desiderata. So, we created our own model deployment process.
Our deployment process using WebAssembly
Before checking whether our deployment process using WebAssembly fits the desiderata, I guess I should explain the steps involved:
- We allow data scientists to fit models using their favourite
pythonorRpackages/tools. - Using our simple package(s), e.g., the
sclblpypackage forpython, a data scientist can upload a stored model (or pipeline) directly from their preferred workspace (see this post for a simple example). - After uploading the model, we automatically “decompose” it — i.e., we strip it off all unnecessary details — and convert just the bare necessities into a WebAssembly binary. This step is admittedly challenging and it took us quite some headaches to build, but, luckily, it needs to be done only once for each model class. Once done, every model of a known model class can automatically be optimized and transpiled to WebAssembly. (For example: suppose you fit a linear regression model using
scikit-learn. In this case, a stored model object contains a lot of information that is not essential for inference: we effectively strip the object to create a WebAssembly binary that contains only the required vector operations). - After generating a
.wasmbinary, which follows the WASI standard to make it fully portable, it can be run anywhere. We often end up hosting the binary on our servers and creating a REST endpoint to consume the inference task, but we have also deployed model objects in the browser, and on the edge.
So, that’s the process we ended up with.
What is WebAssembly?
I guess it’s useful to briefly digress and explain WebAssembly. According to the official WebAssembly page, “WebAssembly (abbreviated Wasm) is a binary instruction format for a stack-based virtual machine. Wasm is designed as a portable compilation target for programming languages, enabling deployment on the web for client and server applications.” Now, while this is true, with the advent of WASI and, amongst others, the fabulous open-source tools provided by our friends at Wasmer, the definition almost looks too limited: WASI binaries can be ran anywhere. So, for us, WebAssembly is a compile target that effectively provides executables that run at native speed, in extremely small and efficient containers, virtually anywhere.
So, let’s check if that fits…
Desideratum 1: Ease of use
We are currently able to convert models to WebAssembly using a single-line-of -code. Here is a super simple example:
We can do this for pretty much all of sklearn, statsmodels, and xgboost. You can do that using the sclblpy package.
Recently, we started supporting ONNX uploads, effectively covering pretty much any model or pipeline you would like to deploy.
So yes, we think this process is easy enough.
Desideratum 2: Computationally efficient
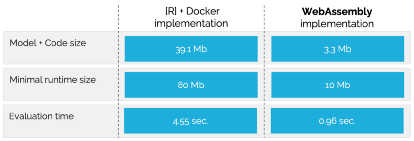
While WebAssembly “promises” to be efficient & fast, it is always good to look at the actual numbers. We fit a BART model for automatic property valuation (AVM); see the demo application here. Generating 1000 posterior draws, when deploying the fitted model using a Docker container, takes a bit over 4.5 seconds for a round trip (i.e., including the network latency). Doing the same using our WebAssembly deployment consistently takes less than a second. We find such speed ups all the time: see this post for some more benchmarks (We also keep a keen eye on WebGPU, a fast developing complementary standard that will enable us to add GPU support to our CPU optimized WebAssembly binaries).
So, yes, the WebAssembly model deployments are fast. However, it is good to understand why it can often be so much faster than existing ror python based inferences. In part, the speed improvement comes from moving to a compiled, lower level language (i.e., strongly typing, better memory management, strong compiler optimization, etc.). However, those improvements are only part of the story: WebAssembly model deployment also allows us to strip a lot of the “layers” involved:
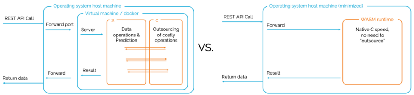
As each layer takes time and resources to run, stripping them ends up being hugely beneficial in terms of latency, energy consumption, and computation costs.
Desideratum 3: Memory footprint
We want models to be small in terms of memory. And, given the analysis of the layers presented above, it’s not just the model “package” itself that should be small; it would be nice if the whole runtime can be as small and efficient as possible. Following up on the AVM demo, this seems to work out well: In R we got the BART model itself down to ~40Mb, and the runtime to ~80Mb (both took some effort). Using WebAssembly deployment we ended up with a model “package” of just over 3Mb, and a runtime of only 10Mb. So that’s a total of ~120Mb vs. 13Mb. Yes, WebAssembly model deployment has a small memory footprint.
Desideratum 4: Portability
Small and fast creates novel opportunities. The portability of WebAssembly models allows running them on servers, in browsers, or on the edge. This generates new use-cases: We have deployed object recognition models on drones (to fly around harbours and recognize the maintainance state of freight containers). We also ran recommender models on the user’s browser, and we are able to send models to hospitals (for radiology diagnosis purposes) as opposed to sending sensitive patient data to central servers. Portability. Check.
Desideratum 5: Safe and verifiable
A question that comes up quite often is “how do we ensure that the returned inferences are valid”? One nice thing about using WebAssembly binaries is that we can extensively validate a model’s inputs and outputs, and consolidate the functionality. The resulting binary can subsequently be validated using simple checksums; we can make sure that the right model is delivered at the right place.
Next to verification, we obviously want the model package to not do any harm to the surrounding computing environment; luckily this is what WebAssembly was designed for; it’s inherently sandboxed and safe.
So, yes, this one also pans out.
Desideratum 6: Easy experimentation
Once the gap to deployment has been bridged, the world does not stop. Often a deployed model is just one instance of all models that could possibly be conceived for a specific problem. It would be great if it was easy to test different versions of a model. WebAssembly binaries make this process simple: setting up A/B tests with a two binaries (or even setting up adaptive schemes such as Thompson sampling over multiple competing models) is straightforward once a model is a stand-alone, easy to ship and easy to run, “package”.
Proper sandboxing and portability make experimenting easy.
Wrap up
We have a lot of experience moving models into production. Based on that experience, we ended up developing a new platform that facilitates model deployment via WebAssembly; for us this ticks all the boxes. That said, a technical solution will never solve the full “problem of model deployment”. Every time we try to bridge the gap from model training and validation to actual usage we are confronted with organizational, legal, financial and ethical questions. We cannot argue that all of these can be solved easily. But, we do think technically the deployment problem is solvable and WebAssembly provides the perfect vehicle to tackle the challenges involved.
Disclaimer
It’s good to note my own involvement here: I am a professor of Data Science at the Jheronimus Academy of Data Science and one of the co-founders of Scailable. Thus, no doubt, I have a vested interest in Scailable; I have an interest in making it grow such that we can finally bring AI to production and deliver on its promises. The opinions expressed here are my own.
Bio: Prof. Dr. Maurits Kaptein is a professor of data science at Tilburg University, The Netherlands, and one of the co-founders of Scailable. Maurits has worked on various topics, from multi-armed bandits to Bayesian Additive Regression Tree (BART) models to efficient methods for adaptive clinical trials. After all that’s done, it’s time to go surfing.
Original. Reposted with permission.
Related:
- Stop training more models, start deploying them
- Software Interfaces for Machine Learning Deployment
- Demystifying the AI Infrastructure Stack