Microsoft’s DoWhy is a Cool Framework for Causal Inference
Inspired by Judea Pearl’s do-calculus for causal inference, the open source framework provides a programmatic interface for popular causal inference methods.

I recently started a new newsletter focus on AI education. TheSequence is a no-BS( meaning no hype, no news etc) AI-focused newsletter that takes 5 minutes to read. The goal is to keep you up to date with machine learning projects, research papers and concepts. Please give it a try by subscribing below:

The human mind has a remarkable ability to associate causes with a specific event. From the outcome of an election to an object dropping on the floor, we are constantly associating chains of events that cause a specific effect. Neuropsychology refers to this cognitive ability as causal reasoning. Computer science and economics study a specific form of causal reasoning known as causal inference which focuses on exploring relationships between two observed variables. Over the years, machine learning has produced many methods for causal inference but they remain mostly difficult to use in mainstream applications. Recently, Microsoft Research open sourced DoWhy, a framework for causal thinking and analysis.
The challenge with causal inference is not that is a new discipline, quite the opposite, but that the current methods represent a very small and simplistic version of causal reasoning. Most models that try to connect causes such as linear regression rely on empirical analysis that makes some assumption about the data. Pure causal inference relies on counterfactual analysis which is a closer representation to how humans make decisions. Imagine a scenario in which you are traveling with your families for vacations to an unknown destination. Before and after the vacation you are wrestling with a few counterfactual questions:
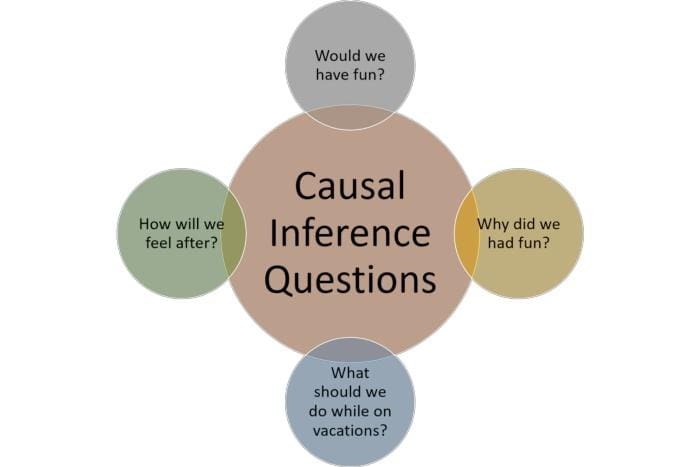
Answering these questions is the focus of causal inference. Unlike supervised learning, causal inference depends on estimation of unobserved quantities. This if often known as the “fundamental problem” of causal inference which implies that a model never has a purely objective evaluation through a held-out test set. In our vacation example, you can either observe the effects on going on vacation or not going on vacations but never both. This challenge forces causal inference to make critical assumptions about the data generation process. Traditional machine learning frameworks for causal inference try to take shortcuts around the “fundamental problem” resulting on a very frustrating experience for data scientists and developers.
Introducing DoWhy
Microsoft’s DoWhy is a Python-based library for causal inference and analysis that attempts to streamline the adoption of causal reasoning in machine learning applications. Inspired by Judea Pearl’s do-calculus for causal inference, DoWhy combines several causal inference methods under a simple programming model that removes many of the complexities of traditional approaches. Compared to its predecessors, DoWhy makes three key contributions to the implementation of causal inference models.
- Provides a principled way of modeling a given problem as a causal graph so that all assumptions explicit.
- Provides a unified interface for many popular causal inference methods, combining the two major frameworks of graphical models and potential outcomes.
- Automatically tests for the validity of assumptions if possible and assesses robustness of the estimate to violations.
Conceptually, DoWhy was created following two guiding principles: asking causal assumptions explicit and testing robustness of the estimates to violations of those assumptions. In other words, DoWhy separates the identification of a causal effect from the estimation of its relevance which enables the inference of very sophisticated causal relationships.
To accomplish its goal, DoWhy models any causal inference problem in a workflow with four fundamental steps: model, identify, estimate and refute.
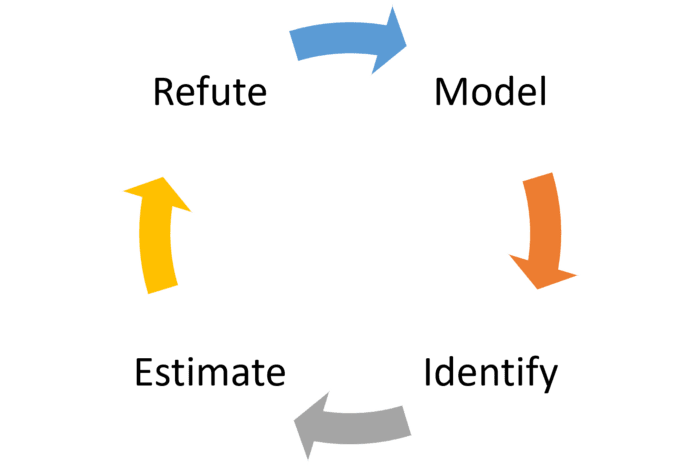
- Model: DoWhy models each problem using a graph of causal relationships. The current version of DoWhy supports two formats for graph input: gml (preferred) and dot. The graph might include prior knowledge of the causal relationships in the variables but DoWhy does not make any immediate assumptions.
- Identify: Using the input graph, DoWhy finds all possible ways of identifying a desired causal effect based on the graphical model. It uses graph-based criteria and do-calculus to find potential ways find expressions that can identify the causal effect
- Estimate: DoWhy estimates the causal effect using statistical methods such as matching or instrumental variables. The current version of DoWhy supports estimation methods based such as propensity-based-stratification or propensity-score-matching that focus on estimating the treatment assignment as well as regression techniques that focus on estimating the response surface.
- Verify: Finally, DoWhy uses different robustness methods to verify the validity of the causal effect.
Using DoWhy
Developers can start using DoWhy by installing the Python module using the following command:
python setup.py installLike any other machine learning program, the first step of a DoWhy application is to load the dataset. In this example, imagine that we are trying to infer the correlation between different medical treatments and outcomes represented by the following dataset.
Treatment Outcome w0
0 2.964978 5.858518 -3.173399
1 3.696709 7.945649 -1.936995
2 2.125228 4.076005 -3.975566
3 6.635687 13.471594 0.772480
4 9.600072 19.577649 3.922406DoWhy relies on pandas dataframes to capture the input data:
rvar = 1 if np.random.uniform() >0.5 else 0
data_dict = dowhy.datasets.xy_dataset(10000, effect=rvar, sd_error=0.2)
df = data_dict['df']
print(df[["Treatment", "Outcome", "w0"]].head())At this point, we simply need about four steps to infer causal relationships between the variables. The four steps correspond to the four operations of DoWhy: model, estimate, infer and refute. We can start by modeling the problem as a causal graph:
model= CausalModel(
data=df,
treatment=data_dict["treatment_name"],
outcome=data_dict["outcome_name"],
common_causes=data_dict["common_causes_names"],
instruments=data_dict["instrument_names"])
model.view_model(layout="dot")
from IPython.display import Image, display
display(Image(filename="causal_model.png"))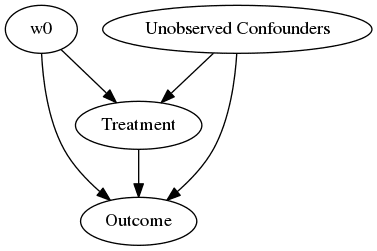
The next step is to identify the causal relationships in the graph:
identified_estimand = model.identify_effect()Now we can estimate the causal effect and determine if the estimation is correct. This example uses linear regression for simplicity:
estimate = model.estimate_effect(identified_estimand,
method_name="backdoor.linear_regression")
# Plot Slope of line between treamtent and outcome =causal effect
dowhy.plotter.plot_causal_effect(estimate, df[data_dict["treatment_name"]], df[data_dict["outcome_name"]])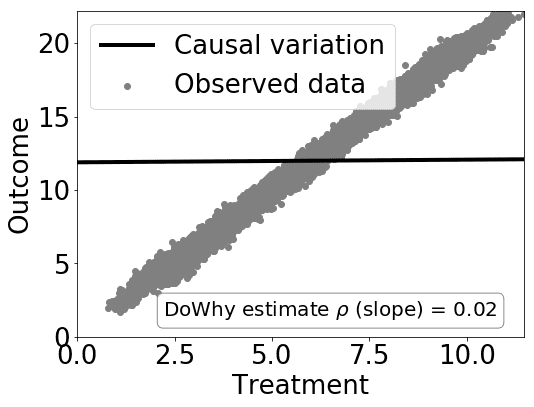
Finally, we can use different technique to refute the causal estimator:
res_random=model.refute_estimate(identified_estimand, estimate, method_name="random_common_cause")DoWhy is a very simple and useful framework to implement causal inference models. The current version can be used as a standalone library or integrated into popular deep learning frameworks such as TensorFlow or PyTorch. The combination of multiple causal inference methods under a single framework and the four-step simple programming model makes DoWhy incredibly simple to use for data scientist tackling causal inference problems.
Original. Reposted with permission.
Related:
- Facebook Uses Bayesian Optimization to Conduct Better Experiments in Machine Learning Models
- Learning by Forgetting: Deep Neural Networks and the Jennifer Aniston Neuron
- Netflix’s Polynote is a New Open Source Framework to Build Better Data Science Notebooks